Contents
• Motivation for attention 注意力机制的动机
• Sequence-to-sequence models 从序列到序列的模型
• Attention in sequence-to-sequence models 序列到序列中的注意力模型
Attention: A neural network layer that learns to select out relevant parts of the input. 学习选择输入的相关部分的神经网络层。
Motivation for Attention

Origin of RNN Attention RNN网络注意力机制的起源
• The attention mechanism was first proposed in natural language translation models. 注意力机制一开始从自然语言翻译模型中被提出
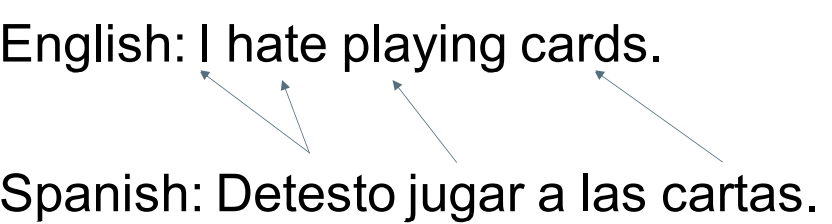
• These models receive as input a sentence in one language and output the corresponding sentence in the target language. 这些模型收到一个某种语言的句子作为输入,希望把这句话翻译成目标语言的对应的句子。
– For example: English to Spanish
Translation
• We’ve seen how RNNs can process sequence inputs.
• For translation, the output is also a sequence (and not necessarily the same length as the input!) 对于翻译,输出也是一个序列,但并不一定和输入序列有相同的长度。
• How would you design a model that can output different length sequences? 如何调整模型,使其可以输出不同长度的序列。
Sequence to Sequence

First part: RNN on the Input Sequence 第一部分:用RNN神经网络处理输入序列
We don’t have to use the outputs at each step we can ignore them and use the last one. 我们不需要在每一步都是用输出,我们可以忽略他们,只在最后一步使用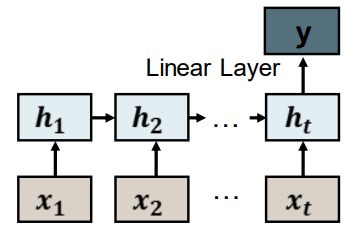
Second part: RNN for Language Modelling 第二部分:用RNN神经网络建立语言模型
The RNN takes the word generated in the last step as the input to the next step. RNN将最后一步生成的单词作为下一步的输入。 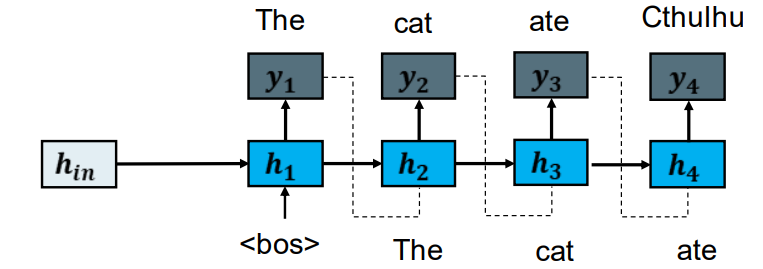
Encoder-Decoder (Seq2Seq) 编码和解码(序列2序列)
• We use 2 RNN models. 我们使用两个rnn模型
• The first (encoder) maps the input sequence to a vector representation. 第一个(编码)rnn网络将输入序列映射成向量表示
• The second (decoder) maps all previously generated tokens to the next token 第二个(解码)将之前生成的tokens映射到 下一个token
• The output of the encoder is used to initialize the decoder’s history 编码器的输出用来初始化解码器的历史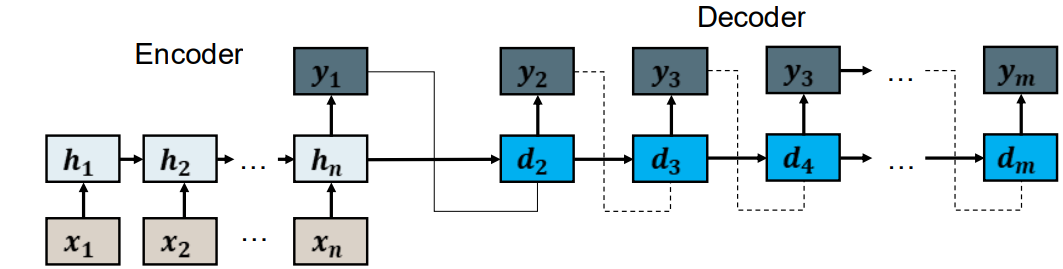
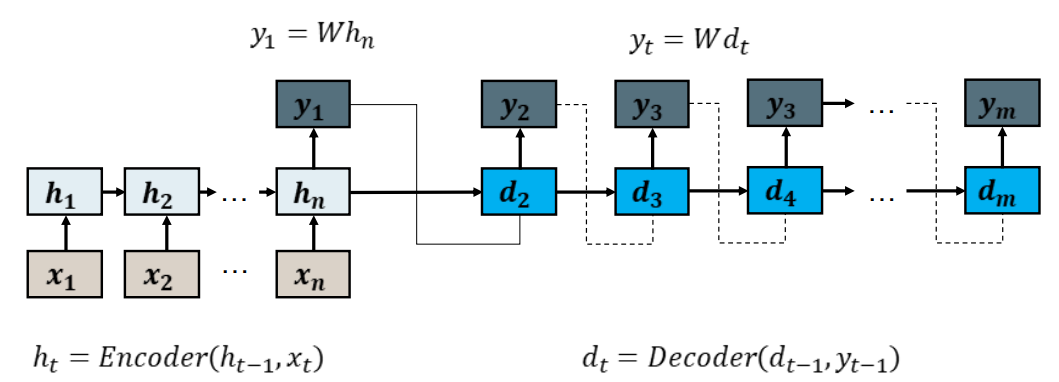
Problems with Encoder-Decoders 编码-解码的问题
• All of the information in the input is compressed into one or two vectors. 所有的输入信息都被压缩成一个或者两个向量
• The decoder must extract information relevant for producing the next output 解码器必须提取相关信息去生成下一个输出
– Often, only some parts of the input are relevant 通常,只有部分输入是相关的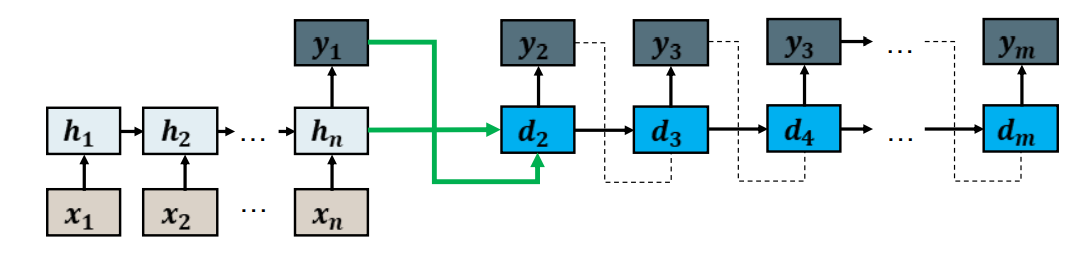
There can be many steps between an input term and a corresponding output term, so: 输入和对应输出之间会有太多步骤
• Forgetting is a problem. 以往是一个问题
• Training is hard (eg vanishing or exploding gradients) 训练很困难,例如:梯度消失、梯度爆炸
Origin of attention
Attention – Key Idea 注意力机制核心思路
Instead of forcing the decoder to extract the information it needs from 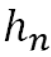 , we instead provide a context vector
, we instead provide a context vector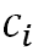 from the encoder computed specifically for the current step.我们不是强迫解码器从hn提取它需要的信息,而是从编码器中提供一个专门为当前步骤计算的上下文向量Ci。
from the encoder computed specifically for the current step.我们不是强迫解码器从hn提取它需要的信息,而是从编码器中提供一个专门为当前步骤计算的上下文向量Ci。
We have a new context vector for every step of the decoding process. 解码过程的每一步都有一个新的上下文向量。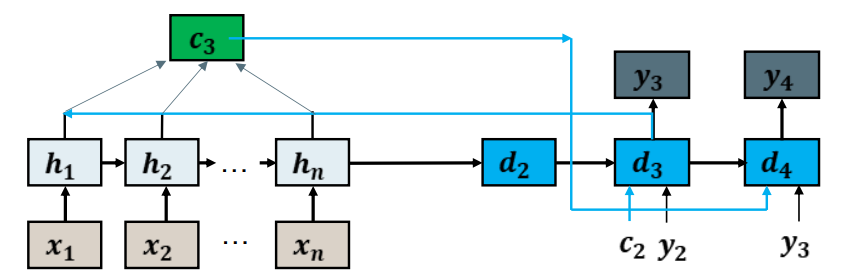
Attention as Weighted Averaging
The context vector is a weighted average of all the encoder outputs. 上下文向量是所有编码器输出的加权平均值。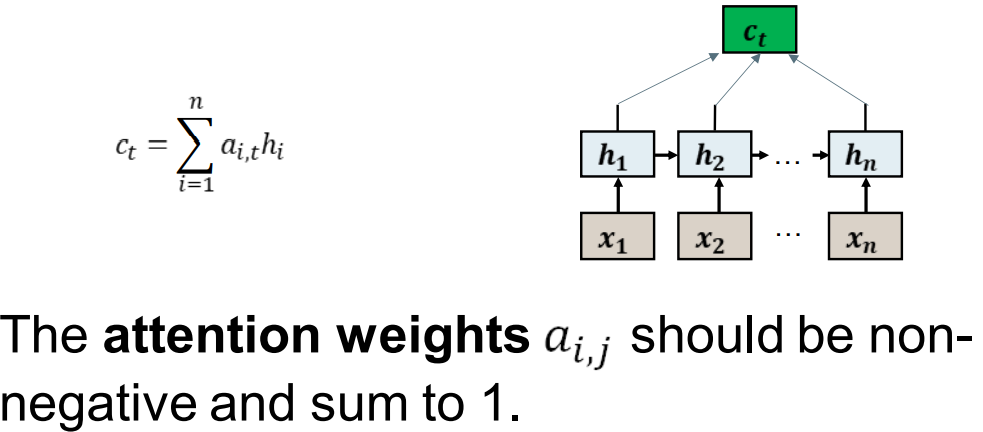
注意力权重应该是非负数且总和为1
Attention Weights 注意力权重
Measure how important each encoding vector is the current step of the decoder. 衡量每个编码向量对解码器当前步骤的重要性。
We use a learnable score function. 我们使用可学习的函数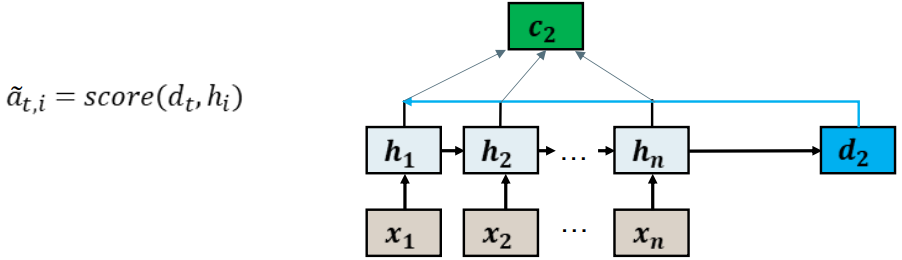
Attention Score Function 注意分数函数
There are several possible score functions, some of which have learnable parameters.
Examples below: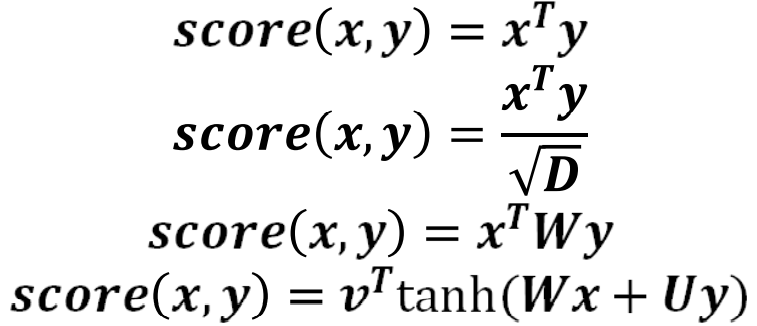
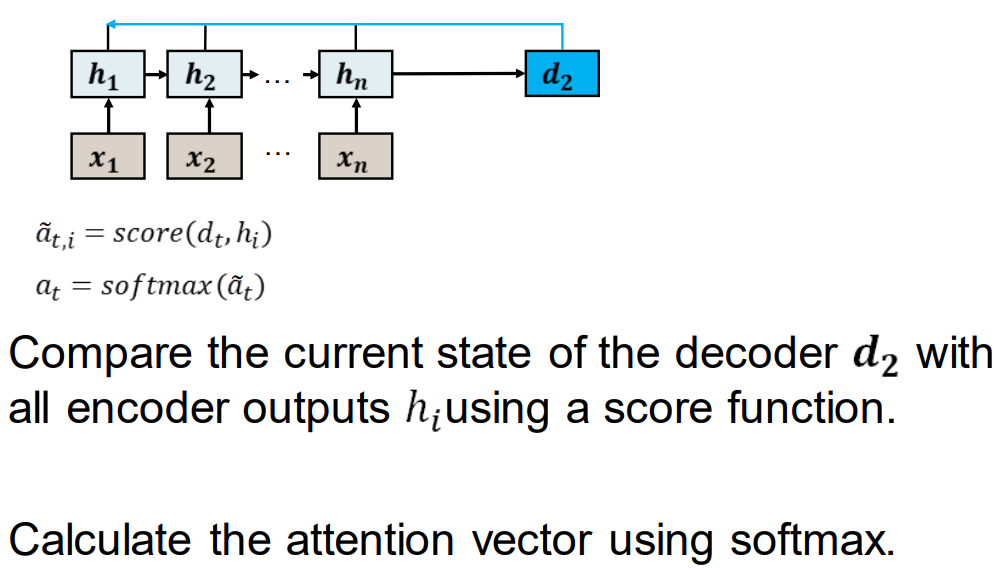
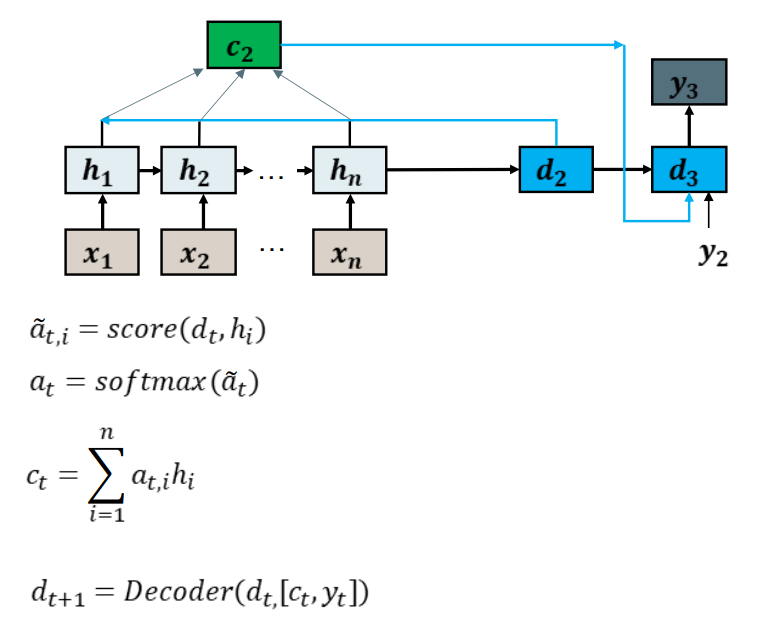
比较现在解码器d2和其他所有编码器输出hi的状态,使用分数函数。
使用softmax计算注意力向量
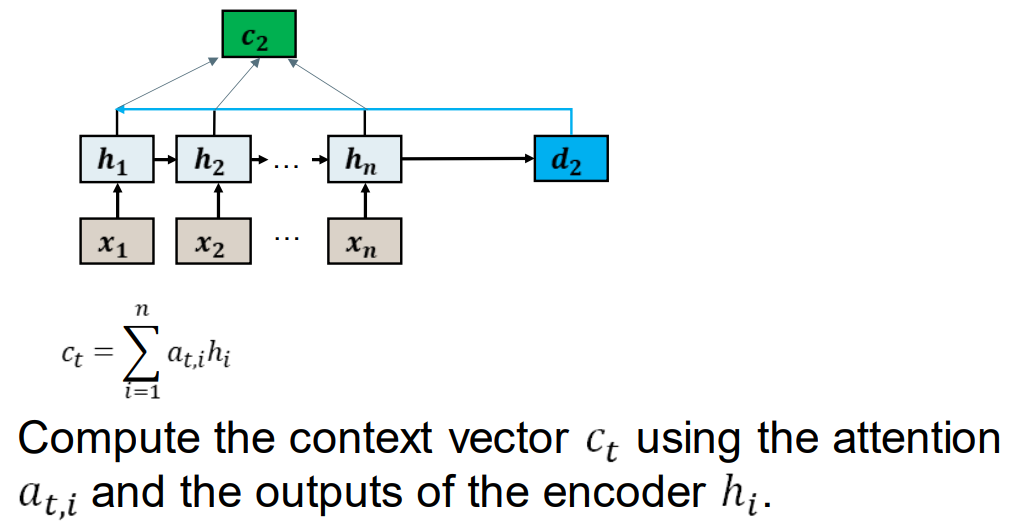
使用注意力权重at,i和编码器hi 来计算上下文向量Ct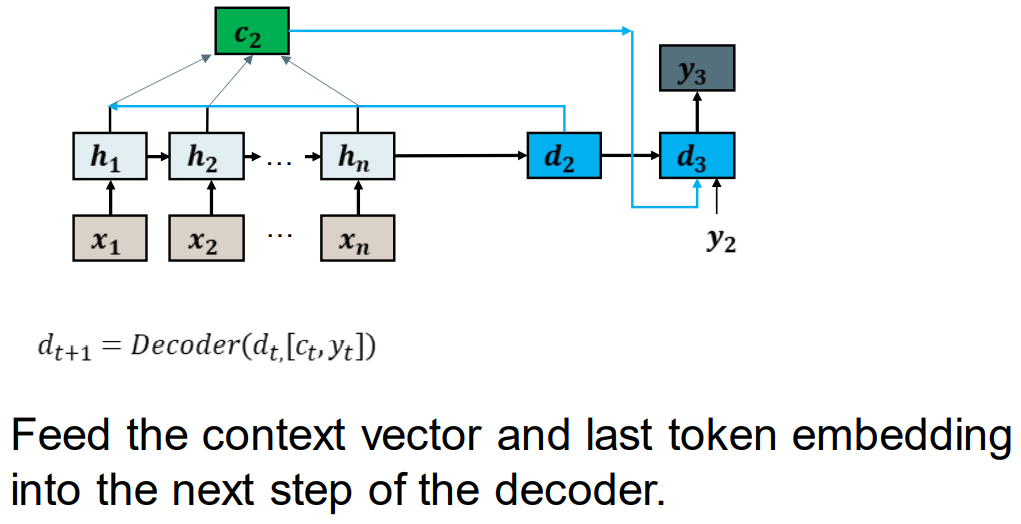
将上下文向量和最后一个token 嵌入向量 输入到解码器的下一步中。
Simple Attention Variations 简单的注意力机制变化
There are many slight modification on this attention scheme. 这个注意方案有很多细微的修改。
- Where the context vector is included in the decoder (input to the RNN Cell or used at the output step) 其中上下文向量包含在解码器中(输入到RNN单元或在输出步骤中使用)
- Guided attention, only apply attention to some of the encoder. 引导注意,只关注编码器的某些部分。
- Self attention on the decoder side 解码器侧的自我关注
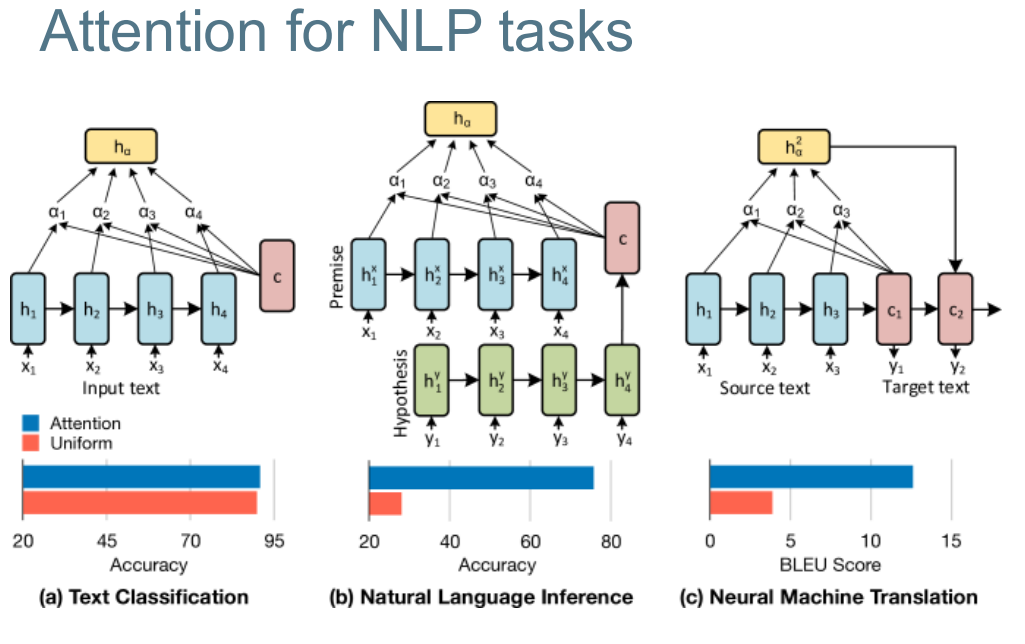
Key-Value Attention Mechanism 关键-价值 注意机制
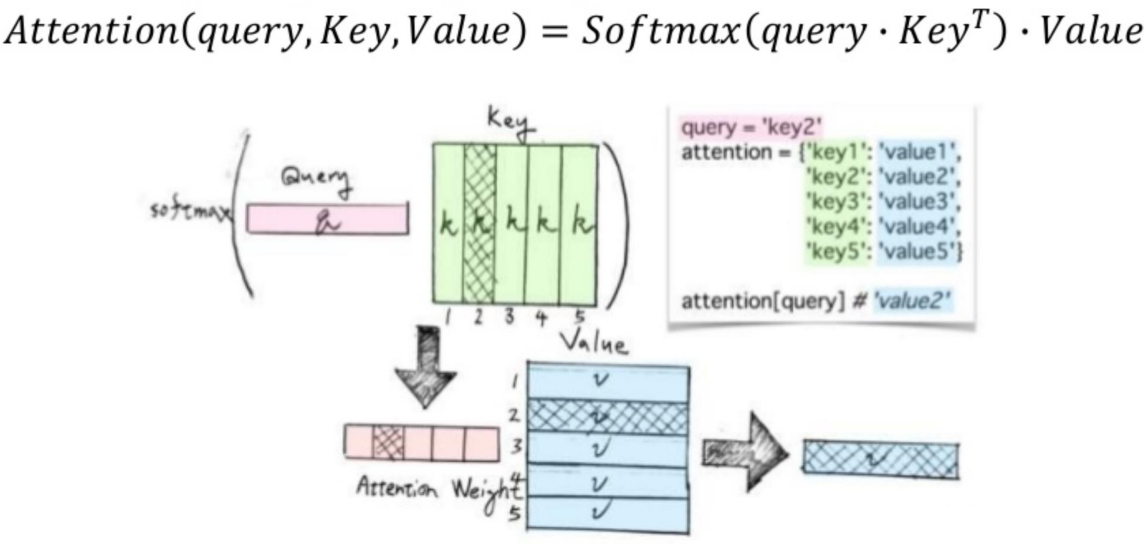
Summary
• Encoder-Decoders are needed to generate output sequences of varying length from variable length inputs 需要编码器-解码器从可变长度输入产生不同长度的输出序列
• The Attention mechanism allows the decoder to focus on the parts of the input relevant to the next decoding step.注意力机制允许解码器专注于与下一个解码步骤相关的输入部分。

若有收获,就点个赞吧
0 人点赞
