- Comparing record pairs
- Similarities and distances 相似度和差异度(距离)
- Basic comparison functions 基本匹配函数
- Numerical comparison functions
- Date and time comparison
- Comparing strings for record linkage 对比字符串
- Q-gram based string comparison Q-gram 字符串配对
- Edit distance
- Bag distance
- Jaro-Winkler string comparison
- Statistical linkage key SLK-581
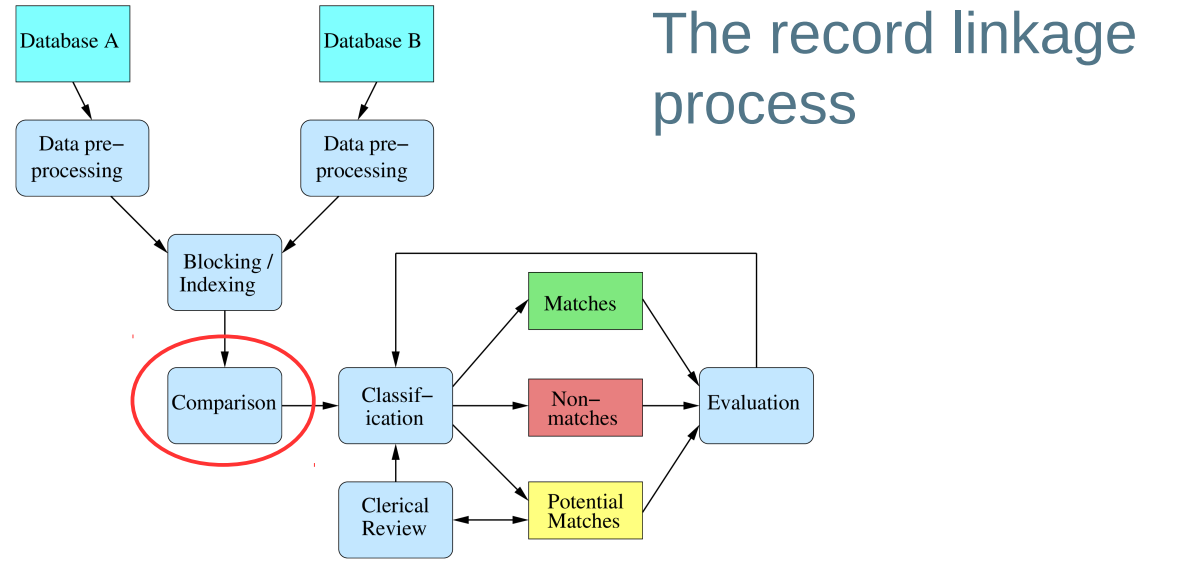
Comparing record pairs
● The blocking process generates groups / clusters of records. Blocking方法生成了记录组或者记录簇。
● From each block, record pairs are generated. 每个Block 都会生成 记录配对。
– For a linkage of two databases, all records from database A are paired with all records from database B from blocks that have the same BKV. 有相同BKV的 block中的所有记录会被相互配对。
– For the deduplication of a single database, all unique record pairs are formed from each block (a record is not compared with itself) 记录配对由不同block配对形成 (记录不会与其自身进行比较)
● Record pairs are compared based on their common available attributes (fields) 记录的配对要基于其定义域
– These are commonly names, addresses, dates, phone numbers, etc. 经常为名字、地址、日期、电话号码等..
– They contain variations and errors (even after cleaning), or can be missing or out-of-date 尽管经过数据清洗,但仍要考虑错误数据或者丢失数据。
● Exact comparison of attribute values will not provide good linkage results 属性的精确比较并不能提供很好的配对结果
– Even true matching record pairs often contain different attribute values 很多实际上一致的配对记录,会包含不一样的属性值。
– For example: [‘peter’, ‘paul’, ‘meier’, ‘2/21 main st’, ‘acton’, ‘act’, ‘ 2601’] [‘peter’, ‘p’, ‘meyer’, ‘21 main street’, ‘acton’, ‘act’, ‘ 2602’]
● Approximate comparison functions are required 需要近似配对
– To calculate similarities between attribute values, not only ‘is the same or is different’ 计算属性之间的相似度,而不仅是判断相同,或者不同。
– They need to be appropriate for the content of a certain attribute (text: names, addresses, dates, phone numbers; numerical: ages, salaries) 他们需要适合特定的属性。
Similarities and distances 相似度和差异度(距离)
● Approximate matching functions generally calculate a numerical similarity value 近似匹配函数会生成相似度数值。
– sim = 0: Two values are completely different (‘peter’ and ‘david’) 相似度 0: 完全不同
– sim = 1: Two values are exactly the same (‘peter and peter’) 相似度 1: 完全相同
– 0 < sim < 1: Two values are somewhat similar (‘peter’ and ‘pedro’) 0到1之间: 部分相似。
● For the same pair of values, different functions calculate different similarities. 对于同一对值,不同的函数计算得到不同的相似度。
● Some functions calculate distances.
● Distances can be converted into similarities 距离可以转化为相似程度
– sim = 1/dist, with sim = 1 if dist = 0 distance 大于 1的时候。
– dist = 1-sim, if 0 ≤ dist ≤1 distance 大于0 小于1时。
● Distance functions (or distance metrics) have several properties:
– dist(val1, val1) = 0 Distance from an object to itself is always 0. 自己相对于自己的distance 永远为0
– dist(val1, val2) ≥ 0 Distances are always positive. distance永远为正
– dist(val1, val2) = dist(val2, val1) Distances are symmetric distance 是对称的
– dist(val1, val2) + dist(val1, val3) ≥ dist(val2, val3) Triangular inequality must hold 必须遵守三角形法则(两边和大于第三边)
● Not all approximate matching functions are proper metric distances 并非所有近似匹配函数都是合适的度量距离
– Triangular inequality does not hold for certain functions 三角形不等式法则有的函数不一定能满足
– Some functions are not symmetric (for example, those that calculate if one attribute value is included in another, like ‘pete’ and ‘peter’) 有一些函数是不对称的
Basic comparison functions 基本匹配函数
● Exact comparison: 精确匹配
– s exact (val1, val2) = 1 if val1 = val2, 0 otherwise 如果 val1 = val2 则相似度为1, 否则为0.
– val1 and val2 can be strings, numbers, etc. 可以是字符串,也可以是数值等..
● Truncate string comparison (x characters the same at beginning) 截断字符串比较
– For string values only 只能用于字符串
– s trunc (val1, val2) = 1 if val1[:x] = val2[:x], 0 otherwise 如果字符串的前x个字符相同,则相似度为1,否则为0.
– Similar for testing if the end is the same 从后向前截取算法一致
● Phonetic encoded comparisons 语音编码比较
– For strings only 只能用于字符串
– s encode(val1, val2) = 1 if encode(val1) = encode(val2), 0 otherwise 如果编码后val1=val2,则相似度为1,否则为0
– encode() is a phonetic encoding function as discussed previously 和之前讨论过的语音编码方法相同
Numerical comparison functions
● For numerical values, we also want to have a comparison that calculates a similarity between 0 and 1 对于数值,我们也想作比较得到介于0-1之间的相似度。
● We set a maximum absolute difference allowed, or a maximum percentage difference allowed 规定可接受的绝对差异,或者最大差异百分比
– If two values differ more their similarity will be 0 如果两个数值的不同比相似很多,则相似度为0
● For absolute maximum difference of d max and two values n 1 and n 2 :
– If abs(n 1 – n 2 ) ≥ d max : simnum_abs = 0
– If abs(n 1 – n 2 ) < d max : simnum_abs = 1 - (abs(n 1 – n 2 ) / d max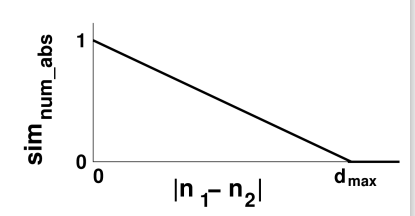
● Similar for maximum percentage difference 最大差异百分比
– Similarity for income (salary) differences of maximum 5% is more suitable compared to a maximum difference of $10,000
– Similarity of age difference by 10% is better than maximum age difference of 5 years (young compared to old people)
● Question: Calculate similarities for absolute maximum difference of d max = 5, n 1 = 42 and n 2 = {37, 38, 40, 41, 49} Then calculate percentage differences assuming these are ages
Date and time comparison
● Dates are often used when records are compared
– Comparing dates as strings is not a good idea: 31/12/1999 versus 01/01/2000, 24/11/2017 versus 24/01/2017 将日期作为字符串比较不是好的选择
– Dates can be converted into number by counting the number of days since a certain fix date, then calculate numerical similarity between day numbers 日期可以被转换成距离某个特定日期的天数,然后比较天数
● Specific issue with how dates are recorded
– Sometimes day and month numbers are swapped: US versus (almost) the rest of the world, for example 12/07/2000 versus 07/12/2000
● Time values also are modulo
23:59 is more similar to 00:01 than to 13:59
Comparing strings for record linkage 对比字符串
● Strings (text) are the most commonly used attributes (fields) when comparing records
– Names: Title; first, middle, and last name; name suffix and prefix, etc. 姓名
– Addresses: Street name and type, postcode/zipcode (e.g. in the UK: “CB3 0EH”), suburb/town name, state/territory and country names – Telephone numbers, emails, credit card numbers, drivers license numbers, etc. 地址
● The aim is to calculate a normalised similarity between two strings with 0 ≤ sim approx ≤ 1
● Many different techniques available
– Some general to any types of strings, others specific to certain types (such as personal names or long genome sequences) 有些通用于任何类型的字符串,另一些则专用于某些类型(姓名、基因组序列)。
Q-gram based string comparison Q-gram 字符串配对
● Convert a string into its set of q-grams 将字符串转换成q-gram set
– Often with q = 2 (bigrams) or q = 3 (trigrams)
– For example, with bigrams: “peter” → [“pe”, “et”, “te”, “er”]
● Calculate the similarity between two strings based on counting the number of q-grams that occur in both strings 计算相似度
● For example, with s 1 = “peter” and s 2 = “pete” and q = 2:
– Q1 = [“pe”,“et”,“te”,“er”], Q2 = [“pe”,“et”,“te”], |Q1 | = 4, |Q2 | = 3
– intersection(Q1 ,Q2 ) = [“pe”,“et”,“te”] and union(Q1 ,Q2 ) = [“pe”,“et”,“te”,“er”]
– sim Jacc (s 1 , s 2 ) = | [“pe”,”et”,”te”] | / | [“pe”,”et”,”te”,”er”] | = 3 / 4 = 0.75
– simDice (s 1 , s 2 ) = 2*3 / (3+4) = 6 / 7 = 0.857
● Questions: Which one is correct? Which one is better? What are the Jaccard and Dice similarities between s 1 = “peter” and s 2 = “pedro” for q = 1, 2, and 3 ?
Edit distance
● Idea: Count how many basic edit operations are needed to convert one string into another (known as Levenshtein edit distance)
– Insertion of a character: “pete” → “peter”
– Deletion of a character: “miller” → “miler”
– Substitution of a character: “smith” → “smyth”
– Transpositions of two adjacent characters: “sydney” → “sydeny” (known as Damerau-Levenshtein edit distance)
● Questions: What is the Levenshtein edit distance between “peter” and “petra”, and between “gayle” and “gail”?
● Convert an edit distance into a similarity 0 ≤ simedit_dist ≤ 1 by calculating
simedit_dist(s 1 , s 2 ) = 1 – edit_dist(s 1 , s 2 ) / max(len(s 1 ), len(s 2 ))
● For example, with s 1 = “peter” and s 2 = “petra”:
simedit_dist (s 1 , s 2 ) = 1 – 2 / max(5, 5) = 1 – 2 / 5 = 3 / 5 = 0.6
● Edit distance can be calculated using a dynamic programming algorithm based on the edit matrix
– Which has a quadratic complexity in the lengths of the two strings (i.e. requires len(s 1 ) * len(s 2 ) computational steps)
● Matrix shows the number of edits between sub-strings (for example, between “ga”’ and “gayle” → 3 inserts) “gail” → substitute “i” with “y”, then insert “e” → “gayle” (final edit distance is 2)
● Question: Calculate edit distance between s 1 = “peter” and s 2 = “petra”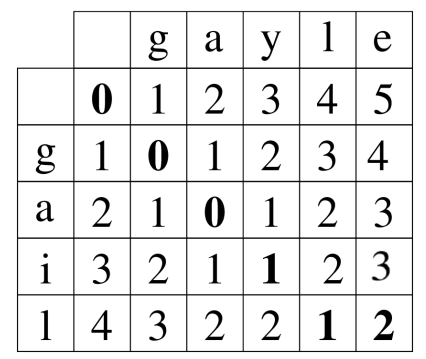
Bag distance
● Main drawback of edit distance is its quadratic complexity in the lengths of the two strings, i.e. len(s 1 ) * len(s 2 ) computational steps
● A fast approximation of edit distance is bag distance
– A bag is a multi set of the characters in a string: “peter” → [“e”,”e”,”p”,”r”,”t”]
● Bag distance is defined as:
bag_dist(s 1 ,s 2 ) = max(|x - y|, |y - x|), where x = bag(s 1 ) and y = bag(s 2 )
● It has been shown that always: bag_dist(s 1 , s 2 ) ≤ edit_dist(s 1 , s 2 ), and therefore: simbag_dist (s 1 , s 2 ) ≥ simedit_dist (s 1 , s 2 )
– If simbag_dist (s 1 , s 2 ) is below a threshold then edit distance does not need to be calculated
Jaro-Winkler string comparison
● Developed by the US Census Bureau specifically to compare personal name strings, taking various heuristics into account that are based on extensive practical experiences of name matching
● A combination of q-gram and edit distance string comparison q-gram和 编辑距离的合并
● Basic idea of the Jaro comparison function:
– Count c, the number of agreeing (common) characters within half the length of the longer string 较长字符串一半长度内的一致(通用)字符数
– Count t, the number of transposed characters (‘pe’ versus ‘ep’) in the set of common strings 计数t,公共字符串集合中的转置字符数(“pe”对“ep”)
– Calculate sim Jaro (s 1 , s 2 ) = (c / len(s 1 ) + c / len(s 2 ) + (c – t) / c) / 3
● Further modifications, named Jaro-Winkler, aim to improve name matching further
– Increase similarity if the first few characters (p, with p ≤ 4) are the same: 名为Jaro-Winkler的进一步修改旨在进一步改进名称匹配–如果前几个字符(p,p ≤ 4)相同,则增加相似性:
simJaro_Winkler (s 1 , s 2 ) = = sim Jaro (s 1 , s 2 ) + (1 - sim Jaro (s 1 , s 2 )) * p/10
For example, for s 1 = “peter” and s 2 = “petra”: p = 3 (“pet”)
– Further increase the similarity if both strings are at least 5 characters long and contain two common characters besides the prefix 如果两个字符串的长度都至少为5个字符,并且除前缀外还包含两个公共字符,则进一步增加相似性
– Adjust similarity if certain similar character pairs (like in Soundex) occur in two strings (for example “w” ↔ “v” or “s” ↔ “z”) 如果发音相似度匹配,则进一步调整相似度
Statistical linkage key SLK-581
● Developed by the Australian Institute for Health and Welfare http://meteor.aihw.gov.au/content/index.phtml/itemId/349895
● Aims to identify records that likely correspond to the same person 识别大概率为一个人的记录
● Combines blocking and comparison functionalities 结合了blocking和comparison函数
● Basic idea:
– Take the 2nd, 3rd, and 5th letters of a record’s family name (surname) 取姓的第二三五位字符,
– Take the 2nd and 3rd letters of the record’s given name (first name) 取名字的第二第三位字符
– Take the day, month and year of the person, concatenated in that order (ddmmyyyy) to form the date of birth
– Take the gender of the person (1=male, 2=female, 9=unknown) 提取性别
– If names too short use 2, if full name component missing use 999 如果名字太短则取2, 如果名字缺失则为999
● Examples: (spaces added for illustration only)
– “marie miller”, 13/04/1991, “f” → “ile ar 13041991 2”
– “john smith”, 31/03/2001, “m” → “mih oh 31032001 1”
– “ashley lee”, 11/12/1963, “u” → “ee2 sh 11121963 9

若有收获,就点个赞吧
0 人点赞
