Clustering tendency assessment determines whether a given data set has a non-random structure, which may lead to meaningful clusters.
- Assess if non-random structure exists in the data by measuring the probability that the data is generated by a uniform data distribution
- Test spatial randomness by statistical test: Hopkins Statistic 通过统计检验检验空间随机性:霍普金斯统计
- Given a dataset
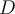 regarded as a sample of a random variable
regarded as a sample of a random variable 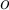 , determine how far away
, determine how far away 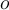 is from being uniformly distributed in the data space
is from being uniformly distributed in the data space - Sample
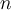 points,
points, 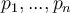 , uniformly from the range of
, uniformly from the range of 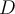 . For each
. For each 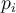 , find its nearest neighbour in
, find its nearest neighbour in  where
where 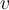 in
in 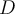
- For example, if
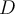 consists of real valued observations whose minimum value is 0.5 and maximum value is 6.2, then
consists of real valued observations whose minimum value is 0.5 and maximum value is 6.2, then 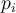 is a random value sampled uniformly between 0.5 and 6.2.
is a random value sampled uniformly between 0.5 and 6.2.
- For example, if
- Sample
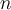 points,
points,  , uniformly from
, uniformly from 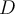 (
(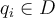 ). For each
). For each 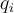 , find its nearest neighbour in
, find its nearest neighbour in 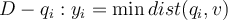 where
where 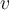 in
in  and
and 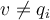
- Unlike
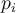 ,
, 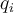 is one of the existing values in
is one of the existing values in 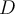 (i.e.
(i.e. 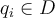 ).
).
- Unlike
- Calculate the Hopkins Statistic:
- Given a dataset

- If [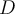](https://wattlecourses.anu.edu.au/filter/tex/displaytex.php?texexp=D) is uniformly distributed, [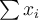](https://wattlecourses.anu.edu.au/filter/tex/displaytex.php?texexp=%5Csum%20x_i) and [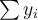](https://wattlecourses.anu.edu.au/filter/tex/displaytex.php?texexp=%5Csum%20y_i) will be close to each other and [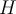](https://wattlecourses.anu.edu.au/filter/tex/displaytex.php?texexp=H) is close to 0.5.
- If
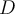 is highly skewed,
is highly skewed, 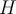 is c lose to
is c lose to 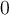
- If
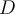 is uniformly distributed 均匀分布 then it contains no meaningful clusters.
is uniformly distributed 均匀分布 then it contains no meaningful clusters.
- If

若有收获,就点个赞吧
0 人点赞
