- Non-linear Relationships 非线性关系
- Neural Networks: Bio-Inspired 神经网络:生物启发
- MLP Neural Network: Key Idea MLP神经网络:关键思想
- Notation
- Why use a non-linearity? 为什么要使用非线性
- Other non-linearities 其他的 非线性关系
- Notation
- Hidden Dimensions
- Network with 2 ReLU Neurons 两个relu的神经网络
- Network with 50 ReLU Neurons 50个ReLU的神经网络
- Recap
- Recap: Gradient Descent 概述:梯度下降
- Summary
Non-linear Relationships 非线性关系
• What do we do if the target does not have a linear relationship with the input? 如果输入输出是非线性关系我们怎么办?
• We need to fit a non-linear function to our data 我们需要用非线性函数拟合我们的数据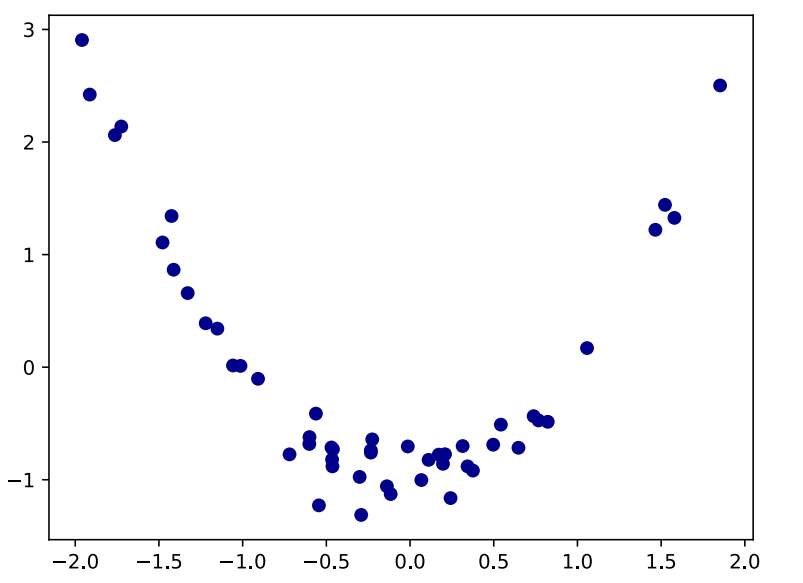
Neural Networks: Bio-Inspired 神经网络:生物启发
Initially inspired by models of the brain 被大脑的模型所启发
We keep some of the ideas and terminology, but it is not a current model of the brain 我们保留了一些想法和术语, 但它不是目前的大脑模型
A better way to think of modern neural networks: Differentiable vector cascades 思考现代神经网络的更好方法:可微向量级联
MLP Neural Network: Key Idea MLP神经网络:关键思想
• MLP = Multi-Layer Perceptron 多层感知器(a simple type of neural network, also called a feed forward network) (一种简单的神经网络,也称为前馈网络)
– Stack multiple linear models on top of each other 将多个线性模型堆叠在一起
– Output of one model after a non-linearity is used as input to next model. 非线性后一个模型的输出用作下一个模型的输入。
• Note: Superscript [#] notation denotes layer number.注:上标[#]表示层数。
• The intermediate models learns to output a ‘useful representation’ of the input. 中间模型学会输出输入的“有用表示”。
• The final model still learns to predict the desired output 最终模型仍然学会预测期望的输出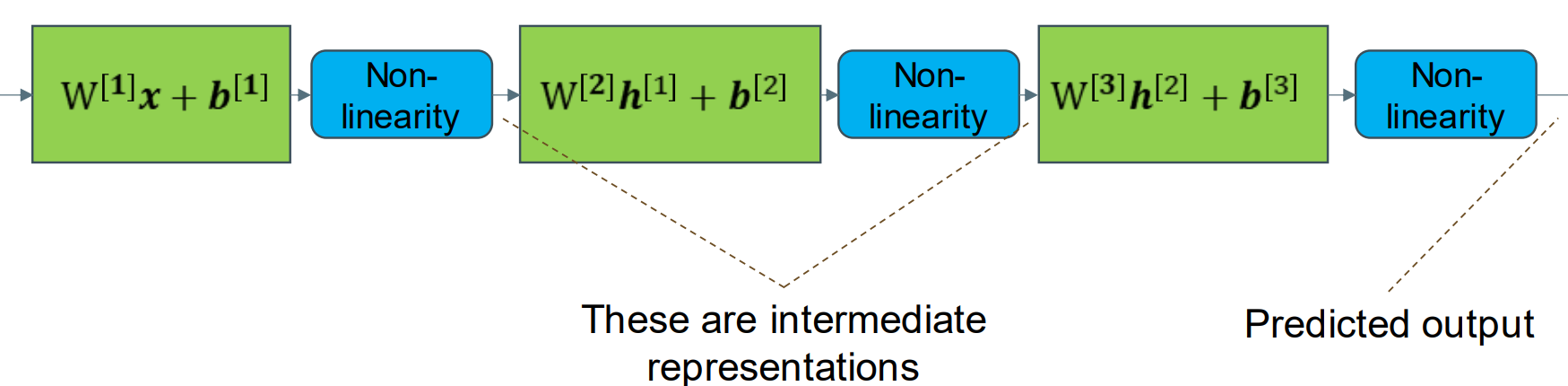
Notation
Sometimes written without the bias since we can absorb it into W by adding an extra dimension of value 1 to the x vector 有时写起来没有偏差,因为我们可以通过在x向量上加一个额外的维度值1来把它吸收到W中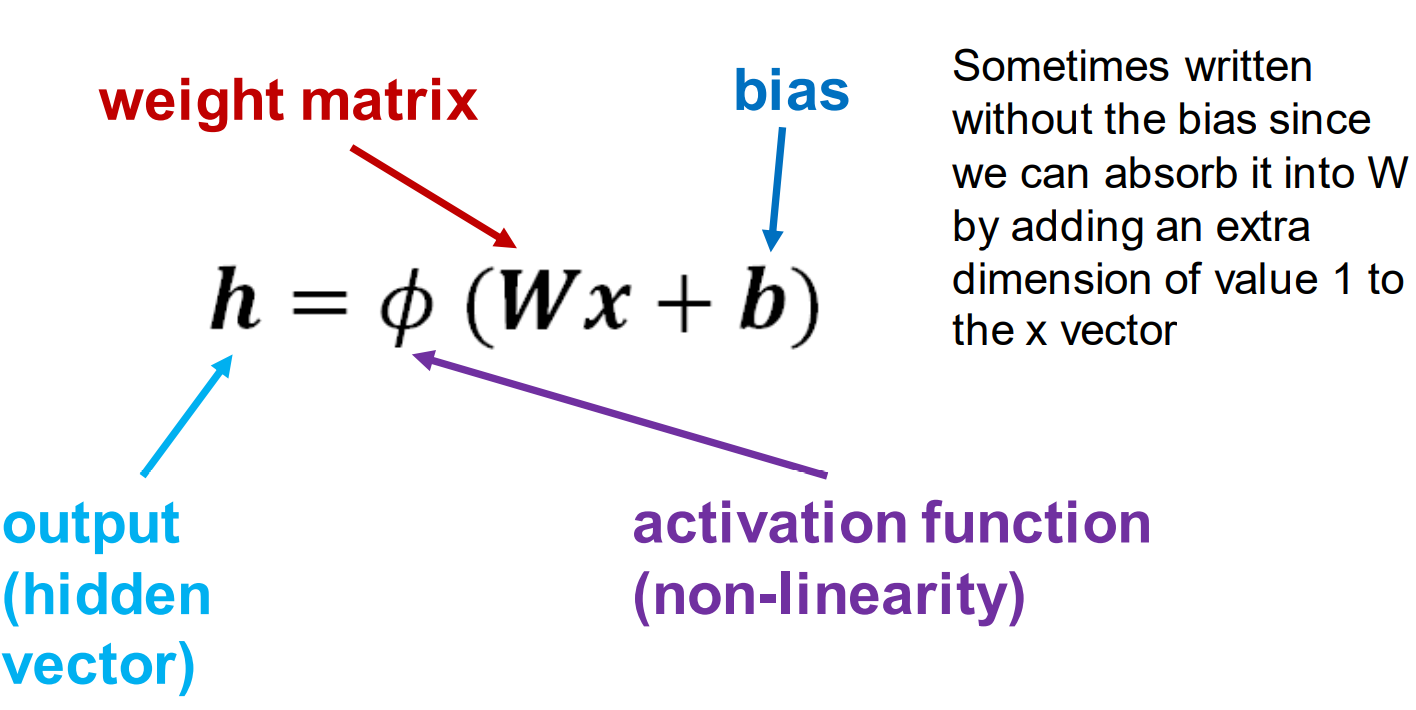
Why use a non-linearity? 为什么要使用非线性

If you compose two linear functions, you just get another linear function, we are still fitting a straight line. 如果你简单将两个线性函数合并,你只能得到另外一个线性函数,仍然在拟合一条直线
其他尝试
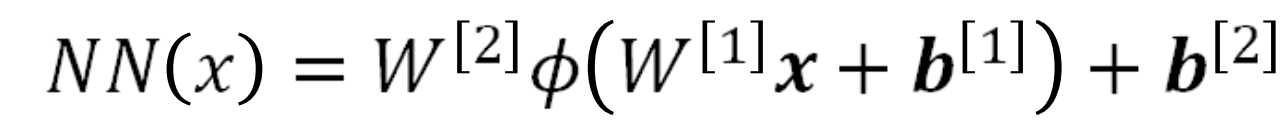
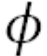 is some function that is non-linear and (mostly) differentiable. seita 是非线性函数且一般可求导。
is some function that is non-linear and (mostly) differentiable. seita 是非线性函数且一般可求导。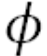 is called the ‘activation function’. 称作激活函数。
is called the ‘activation function’. 称作激活函数。
Rectified Linear Unit (ReLU) 整流器线性单元
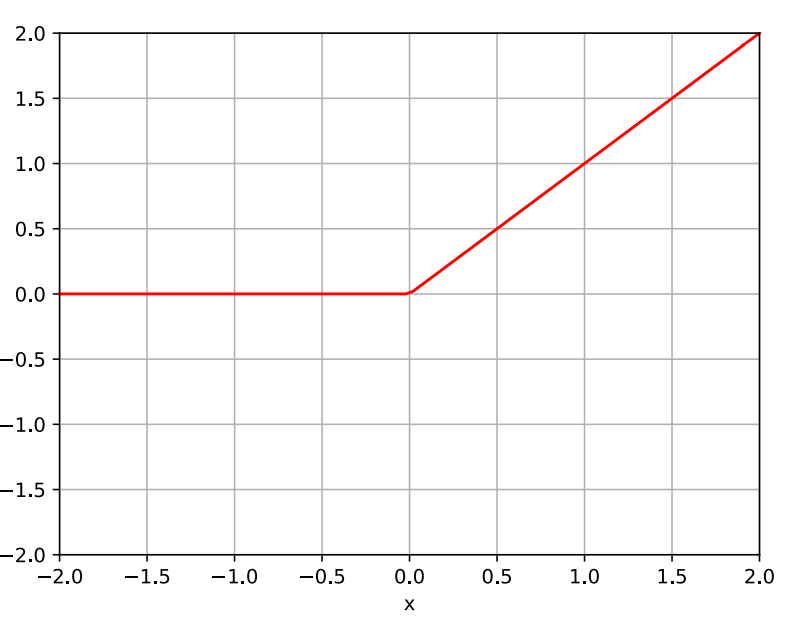
• In principle we can use any non-linear (mostly) differentiable function as the activation function. 原则上,我们可以使用任何非线性(大部分)可微函数作为激活函数。
• Commonly used in practice:
• 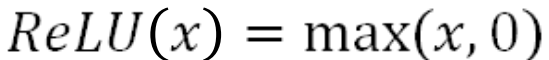 0或最大值
0或最大值
• Fast to compute. 计算快速
• Works well 效果好
Other non-linearities 其他的 非线性关系
Sigmoid was popular for a long period of time. Sigmoid流行了很长一段时间。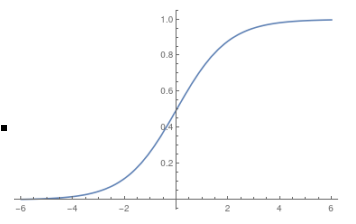
Tanh was also often used.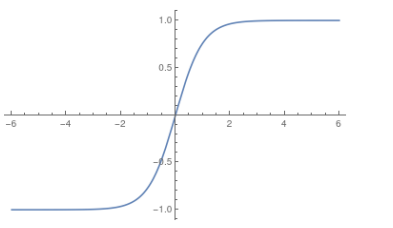
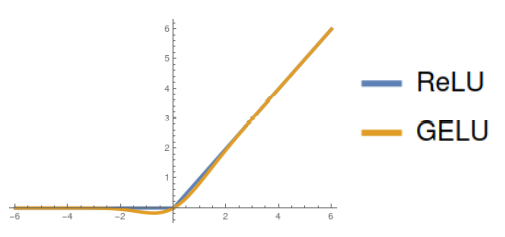
Various smooth approximations to ReLU are common ReLU的各种平滑近似是常见的
For the output layer: 对于输出层
For classification use softmax 经常使用softmax来做分类任务
For regression use a linear last layer. 使用线性层做回归
Notation
For an MLP we typically think of each composition of an activation function with a linear function as a ‘layer’. 对于MLP,我们通常把具有线性函数的激活函数的每个组成部分看作“层”。
• Input layer is the first layer. 输入层是第一层
• Output layer is the last layer. 输出层是最后一层
• All other layers are ‘hidden layers’. 其他的都是隐藏层
In general:
Almost anything, regardless of complexity, can be called a layer, much like almost anything can be called a function. The term is used to conceptually distinguish between different components. 几乎任何东西,不管复杂程度如何,都可以称为层,就像几乎任何东西都可以称为函数一样。该术语用于在概念上区分不同的组件。、
Hidden Dimensions
• The size of the input layer is defined by the number of input features. 输入层的尺寸由输入特征数量定义
• The size of the output layer is defined by the number of output targets. 输出层尺寸由输出目标的数量定义
• The size of the hidden layers can be anything, this is a hyper-parameter for you to choose. 隐藏层的尺寸不固定,可以是你选择设置的超参数
• The dimension of the output of a hidden layer is called the ‘number of hidden neurons’ in that layer. 隐藏层输出的维度称为该层中的“隐藏神经元数量”。
Network with 2 ReLU Neurons 两个relu的神经网络
• What does it look like if we fit a neural network with one layer of 2 hidden neurons with ReLU activations? 如果一个神经网络的一层有两个具有ReLU激活的隐藏神经元
• Each hidden neuron learns a linear function then applies ReLU. 每一个隐藏神经元学习一个线性函数然后应用ReLU
• Output is then a linear function of the hidden outputs. 输出是隐藏层后的一个线性函数。
• Resulting graph is equivalent to scaling, shifting and flipping two ReLU graphs then adding them. 结果图相当于缩放、移动和翻转两个ReLU图,然后将它们相加。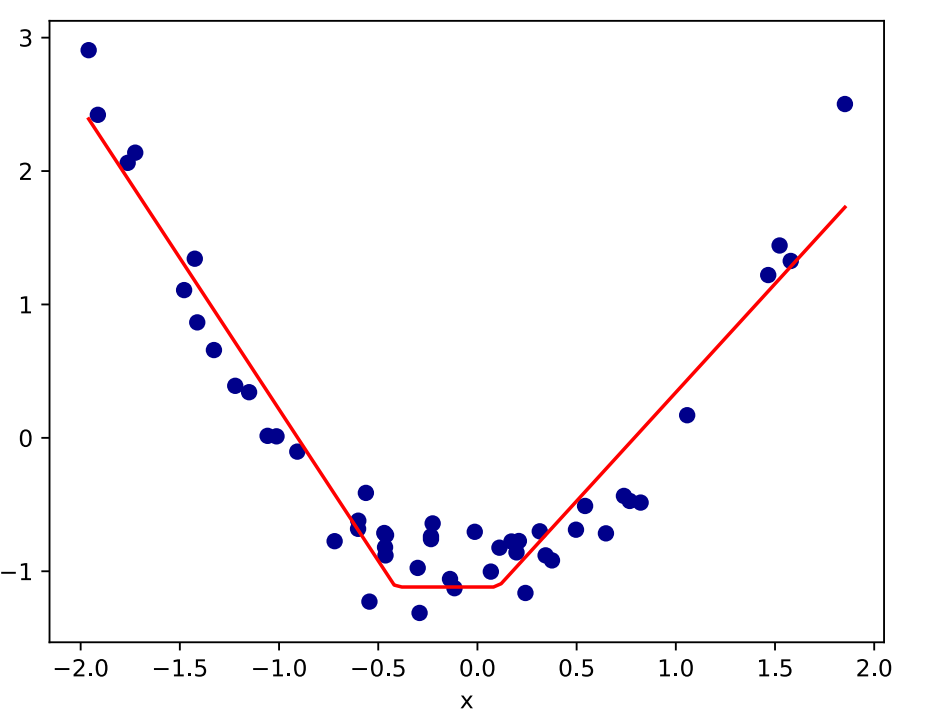
Network with 50 ReLU Neurons 50个ReLU的神经网络
• Increasing the number of hidden neurons means we add together more (scaled) versions of the activation function. 更多的隐藏神经元意味着我们增加了更多的激活函数
• As we add more neurons we can approximate more complicated functions. 随着我们增加了越多的神经元,我们可以拟合更复杂的函数。
• As we add more neurons, our model becomes more capable of fitting noise in the training dataset – overfitting. 但是,随着我们添加更多神经元,我们的模型变得更有能力拟合训练数据集中的噪声——过拟合。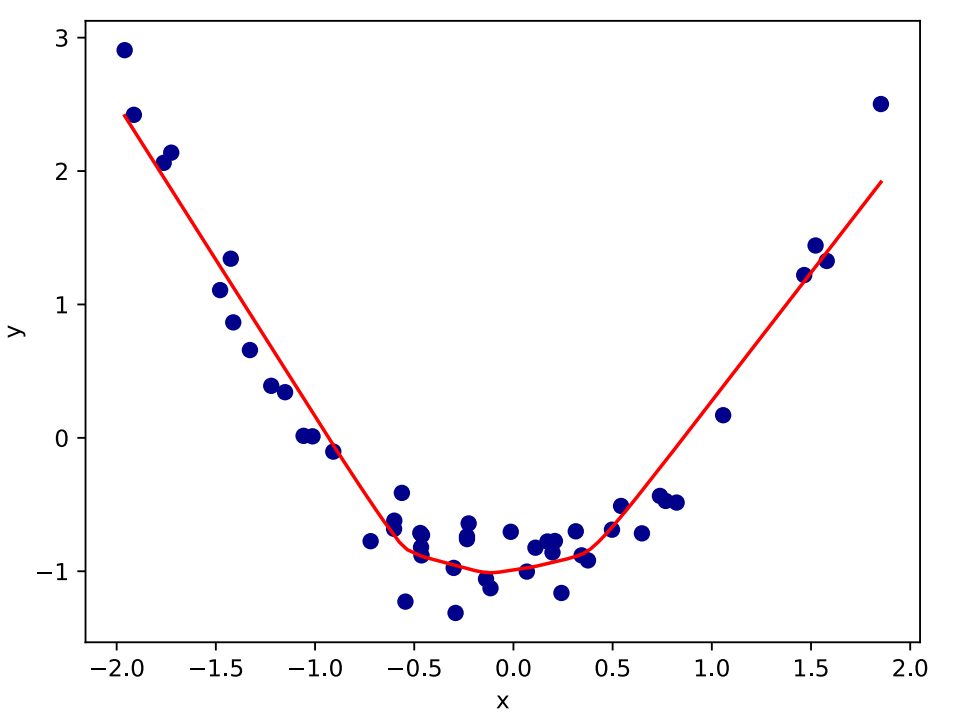
Recap
Multinomial Logistic Regression (Classification) 多项式逻辑回归(分类)
Multi-Layer Perceptron 多层感知器
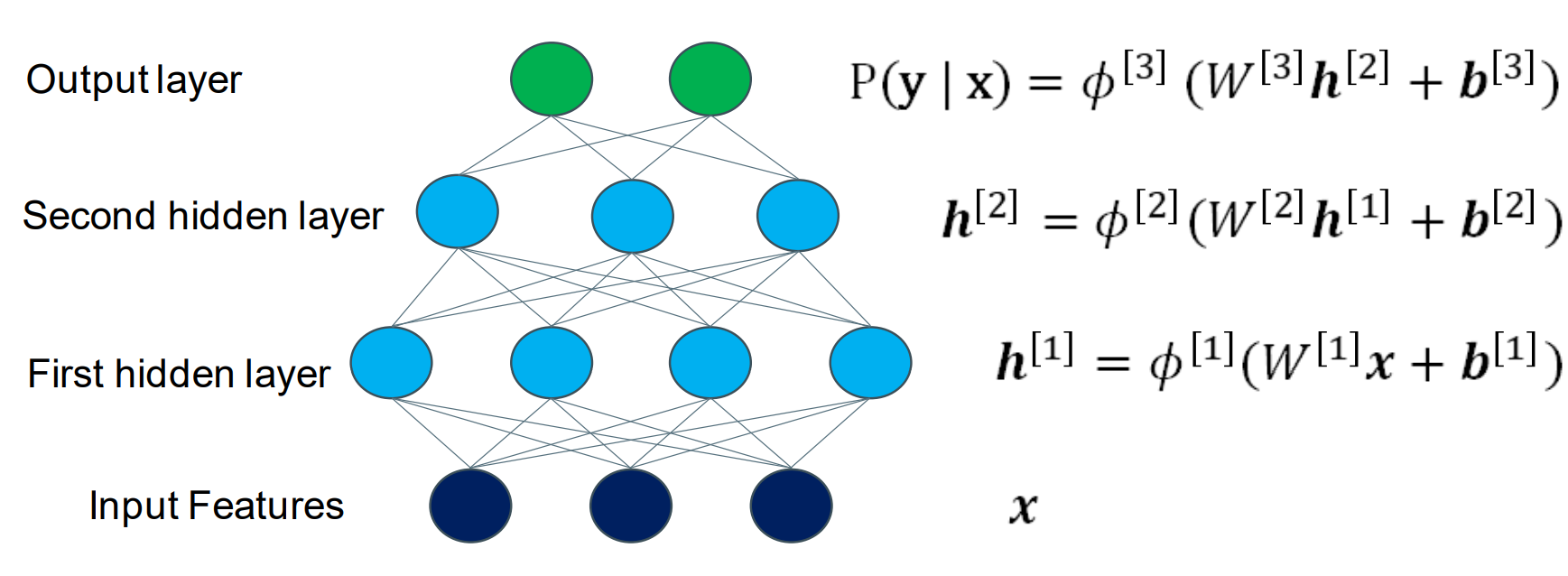
This MLP has 2 hidden layers, with 4 and 3 neurons. 这个多层感知器由两个隐藏层,分别有4个和3个神经元
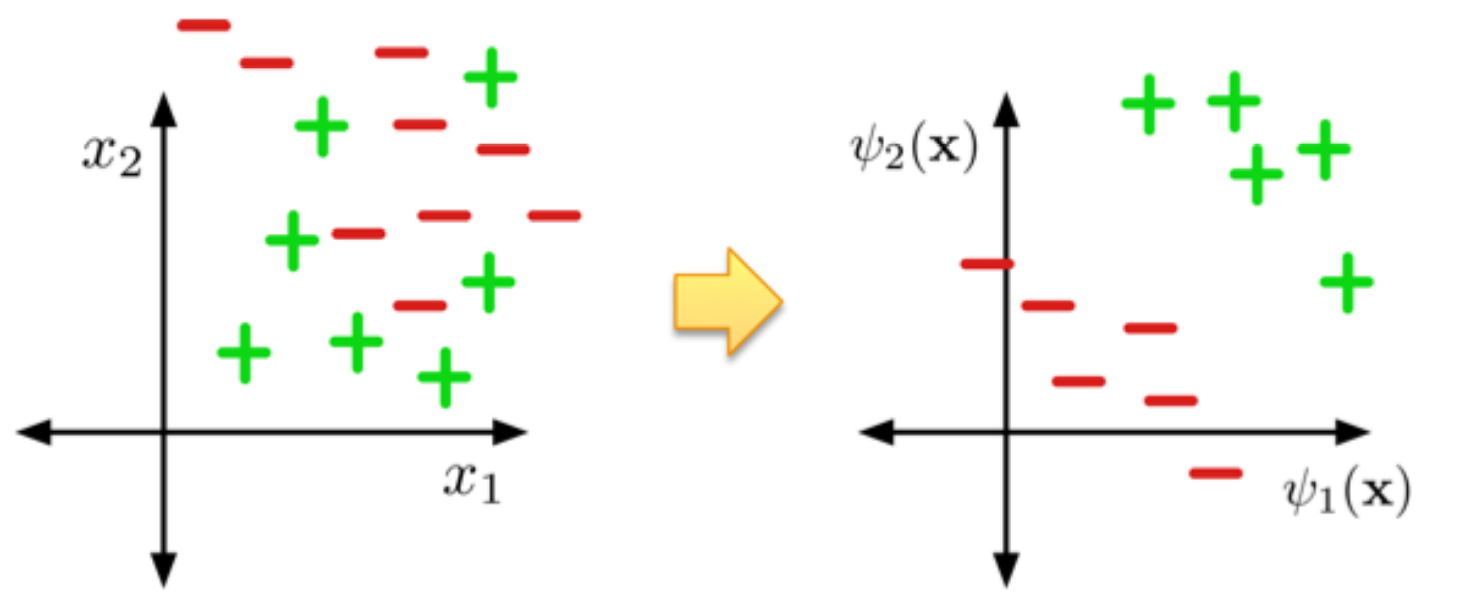
Feature Learning 特征学习
Neural nets can be viewed as a way of learning features: 神经网络可以被看做一种学习特征值的方式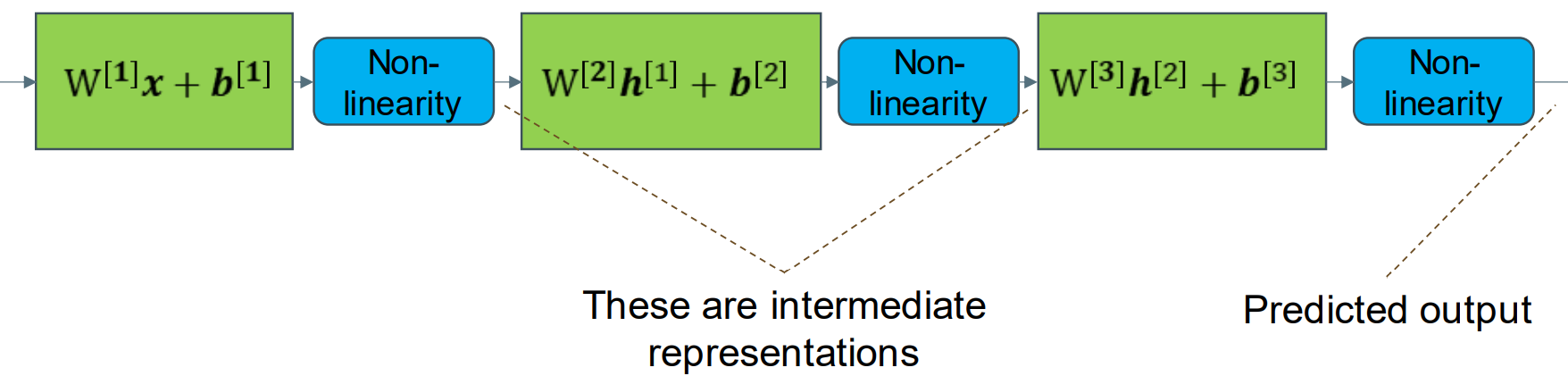
Recap: Gradient Descent 概述:梯度下降
A simple linear regression model with non-linearity and square loss: 下图是具有非线性和平方损失的简单线性回归模型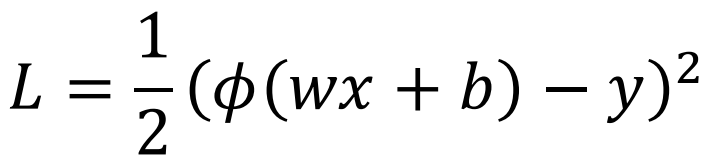
For gradient descent we need numerical values of the following derivatives at the current w and b: 对于梯度下降,我们需要当前w和b处的下列导数的数值: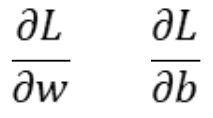

Backpropagation 反向传导
We need the derivative of the loss with respect to the parameters. We want a systematic way of doing this:
- Forwards pass: compute the loss and store the output of each layer.
- Backwards pass: compute the derivatives layer by layer using the chain rule and the results stored from the forward pass.
Chain Rule 链式法则
Given the expression: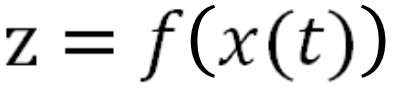
We have the derivative: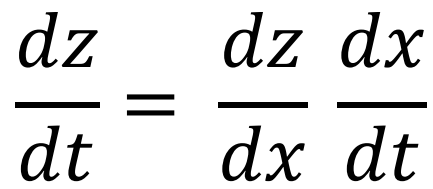
When a function has two parameters, we will need to use the chain rule in this form: 当一个函数有两个参数时,我们需要对其使用链式求导法则

Backpropagation 反向传导
Full model with loss function: 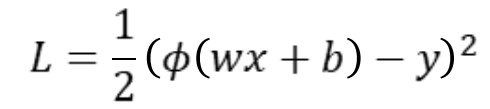
We can introduce intermediate variables中间变量 z, h to give: 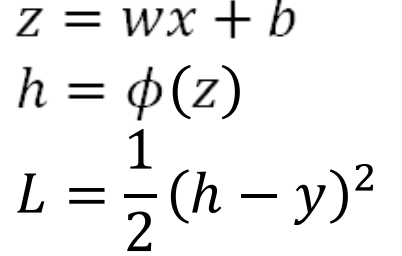
Backpropagation: Forward Pass 反向传导:向前传播
Compute and store z, h, L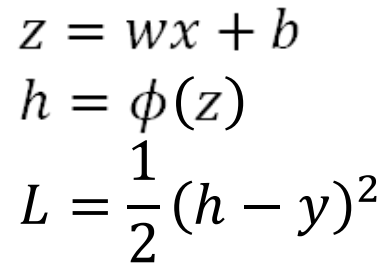
Backpropagation: Backward pass 反向传导:反向传播
Compute the derivative of the loss wrt h 计算L对于h的导数、

Note that both h, y are known (h is stored during the forward pass, y is the ground truth) 请注意,h和y都是已知的(h存储在前向传播期间,y是真实值)


Using Backpropagation Algorithm
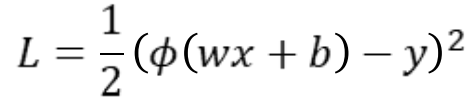<br />
Computation Graph 计算图
• We can diagram out the computations using a computation graph. 我们可以用计算图来画出计算结果。
• The nodes represent all the inputs and computed quantities, and the edges represent which nodes are computed directly as a function of which other nodes. 节点代表所有输入和计算量,边代表哪些节点是根据哪些其他节点直接计算的。
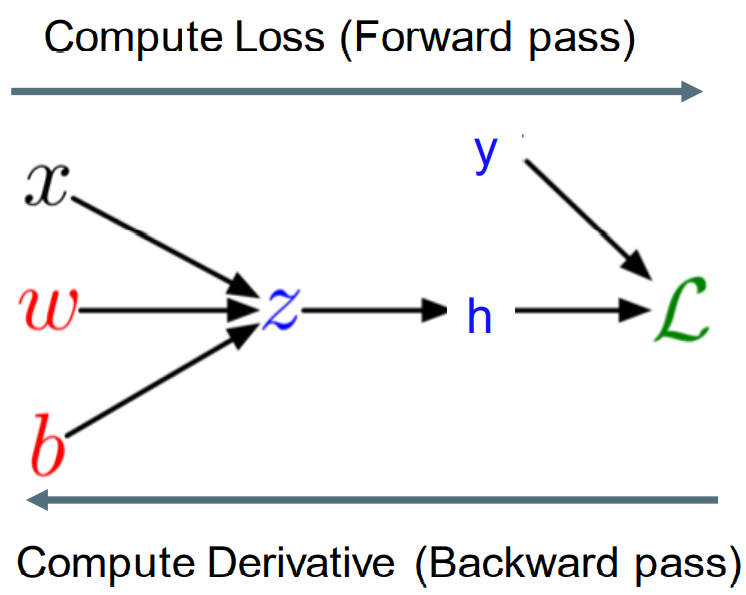
Backpropagation Algorithm 反向传播算法
Full backpropagation (BP) algorithm:
Let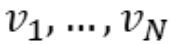 be a topological ordering of the computation graph (i.e. parents come before children.)
be a topological ordering of the computation graph (i.e. parents come before children.) 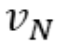 denotes the variable we’re trying to compute derivatives of (e.g. loss).
denotes the variable we’re trying to compute derivatives of (e.g. loss).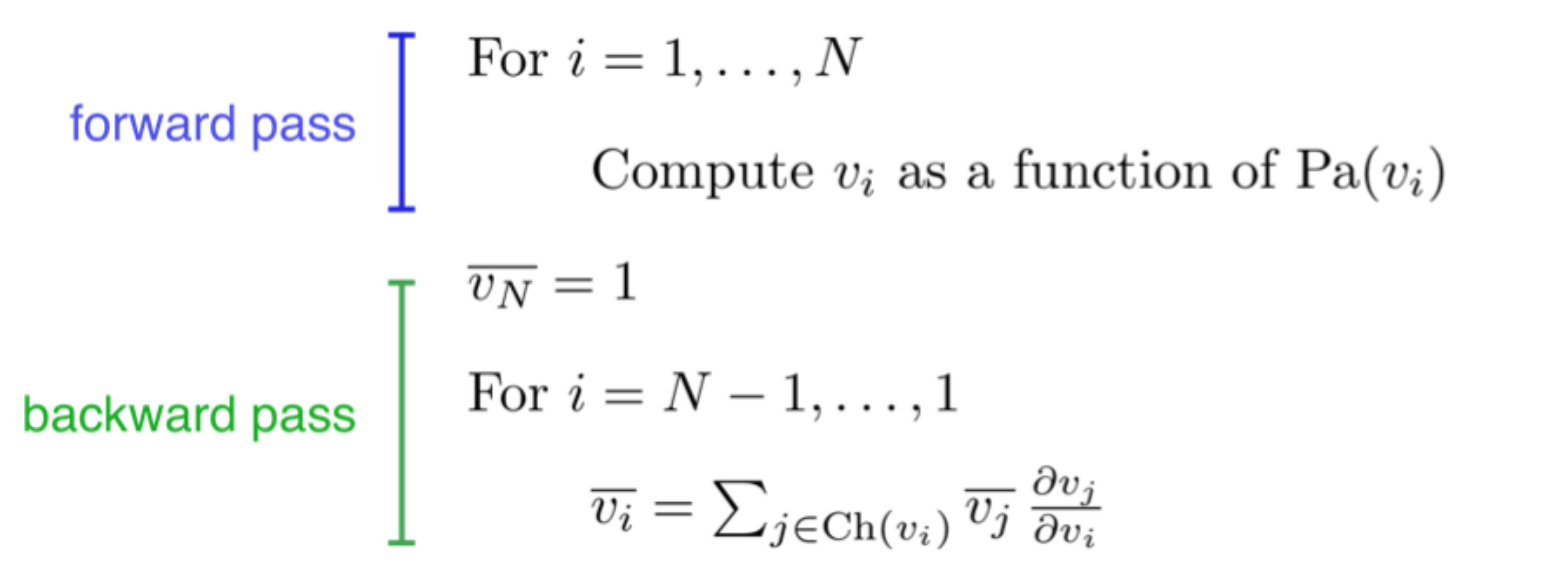
Automatic Differentiation: Pytorch
Calculus is hard! Use Autograd Tools such as Pytorch (more in next week’s lab), TensorFlow, JAX: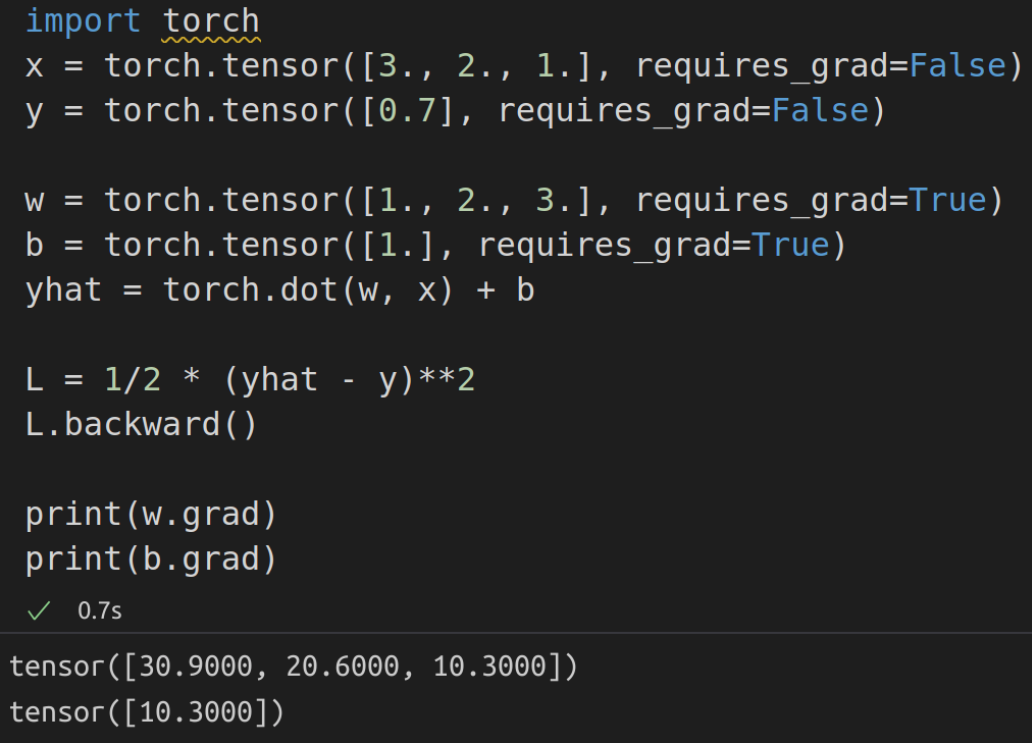
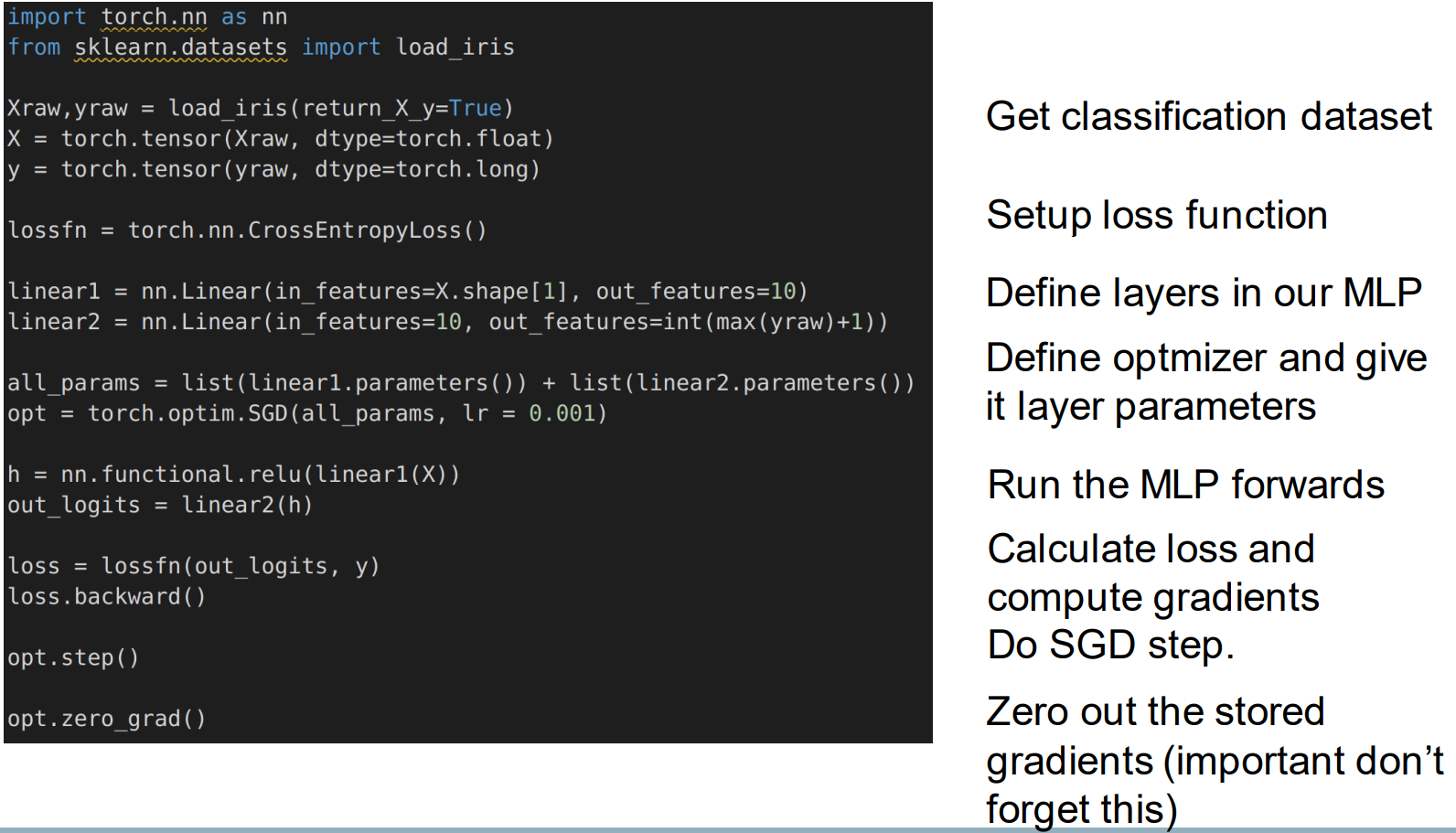
Pytorch: Neural Network
Stochastic Gradient Descent 随机梯度下降
• For standard GD, the gradients are computed on the loss of the entire training dataset. 对于标准的梯度下降,梯度是根据整个训练数据集的损失来计算的。
– Slow if the dataset is very large. 如果数据集非常大,则速度较慢。
• For SGD, at each update we randomly sample a batch of data points and compute gradients only of the loss on these points. 对于SGD,在每次更新时,我们随机抽取一批数据点,并仅计算这些点的损失梯度。
– The batch size is a hyper-parameter. 批次大小是一个超级参数。
– Usually is one of 32, 64, …, 512. 通常是32,64,…,512中的一个。
• SGD is much faster to compute per step. 每一步计算SGD要快得多。
• SGD acts as a regularizer: models trained with SGD usually generalize better. SGD充当正则化器: 用SGD训练的模型通常能更好地概括。
Summary
• A neural network is a stack of linear and non-linear functions
• Neural networks build up intermediate feature representations
• Neural networks are commonly trained using backpropagation and SGD

若有收获,就点个赞吧
0 人点赞
