The words in the document are selected for indexing by preprocessing, typically:
(1) Tokenising — separate based on spaces and other punctuation and remove punctuation 标记化-根据空格和其他标点符号进行分隔,并删除标点符号
(2) Normalisation and Stemming — reduce the word to a canonical form to remove syntactic variance 规范化和词干化——将单词简化为规范形式,以消除句法差异
(3) Remove Stop Words — these are typically very common words of little meaning, (e.g. the, of, for, to, with) but can also be chosen to suit the problem domain (e.g. “law” in a legal database). 删除停用词——这些词通常意义不大,但也可以根据问题领域(如法律数据库中的“法律”)进行选择。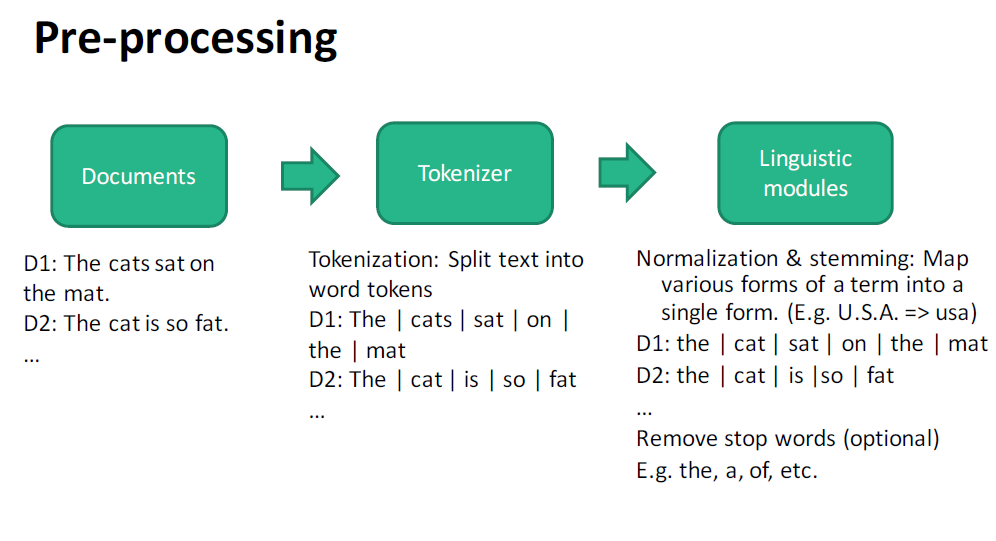

若有收获,就点个赞吧
0 人点赞
