- Word Representations 词汇表示
- Recap 概述
- Self-supervised Learning 自监督学习
- Neural Language Model 神经语言模型
- Context Specific Word Representations 特定于上下文的单词表示
- Feature Learning 特征学习
- Context Specific Word Representations 特定于上下文的单词表示
- Semi-supervised Learning 半监督学习
- For example: Named Entity Recognition 例如:命名实体识别
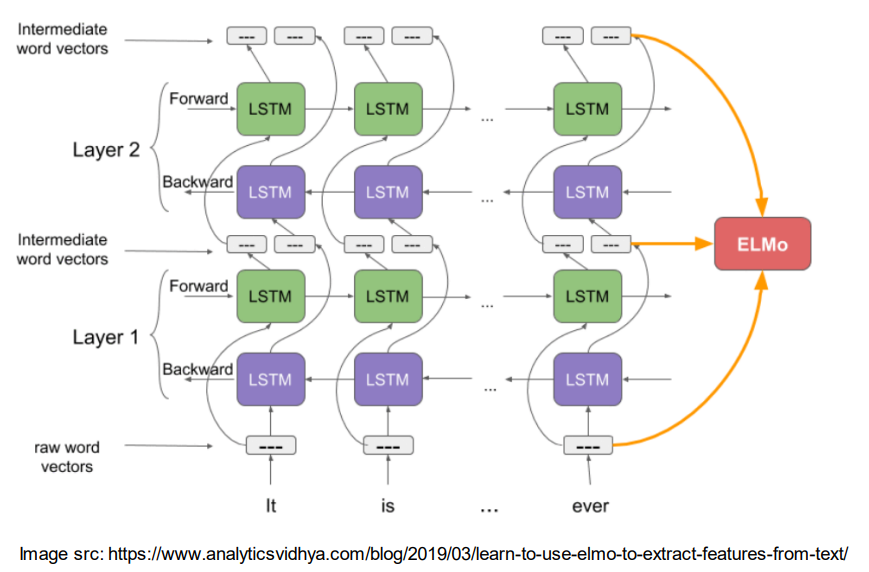
- ELMo
- Elmo results Elmo 结果
- Transformer Models Transformer 模型
- GPT
- Data
- GPT
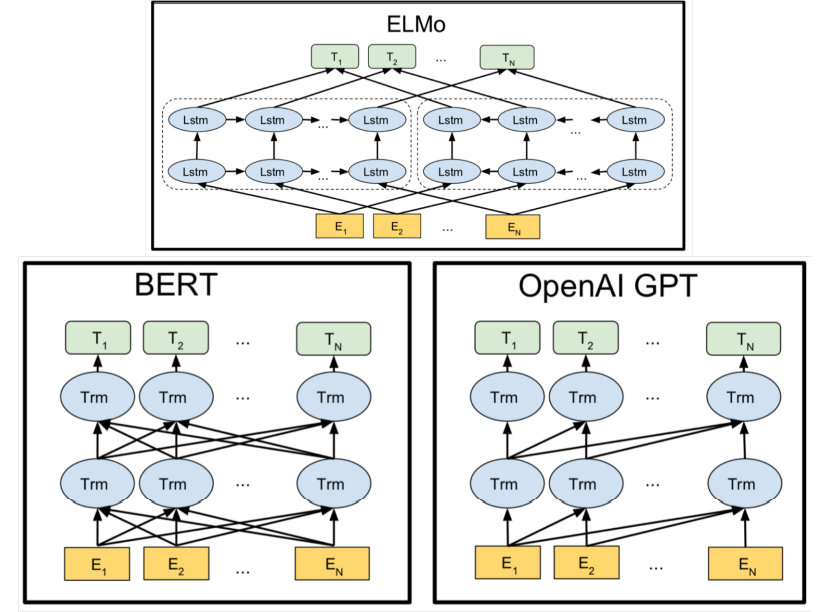
- Bidirectional 双向的
- Architecture Comparison
- Mask out 掩盖
- BERT: Next sentence prediction Bert:预测下一个句子
- BERT: Sentence pair encoding 句子对编码
- BERT model fine tuning
- Using BERT on multiple tasks
- BERT results on GLUE tasks
- XLNet
- Summary
- Self-supervised Learning 自监督学习
Word Representations 词汇表示
We have looked at word representation 我们已经研究了单词的表示法
– Learnt from context words: Word2Vec, LSA 从上下文词汇中学习: Word2Vec, LSA
This has limitations, because: 这是有局限的,因为:
– The representation doesn’t depend on the context in which the word instance occurs 表示不依赖于单词实例出现的上下文
– The same word can have different meanings, syntactic behavior and connotations which cannot be captured by a single representation 同一个单词可以有不同的含义、句法行为和内涵,这是单一的表示所不能捕捉到的
Recap 概述
We have used DNNs to capture context and structure in sentences 我们使用DNN网络去捕捉上下文和句子中的结构
– Sequential structure 词序结构
– Tree structure 树结构
–Unknown structure 未知结构
Training a DNN is expensive, in terms of: 但是训练DNN十分昂贵
– Computation 计算
– Data 数据
Self-supervised Learning 自监督学习
What is self-supervised learning?
– Use naturally existed supervision signals for training. 使用自然存在的监督信号来训练
• Examples: Predict the next word in the text. Predict the color of a nearby pixel in an image. 示例:预测文本中的下一个单词。预测图像中邻近像素的颜色。
– (Almost) no human effort to construct data 几乎不需要人工处理来搭建数据集
Why do we need it?
– To train large models without spending millions of dollars on training data 在不花费数百万美元培训数据的情况下培训大型模型
– To pre-train models for later fine-tuning on a data poor task 预先训练模型,以便以后在数据贫乏的任务中进行微调
Like unsupervised learning we don’t explicitly need to label our data. 像非监督学习一样,我们不需要去为我们的数据打标签
Like supervised learning we have labels (implicit in the data) 像监督学习意义,我们有标签数据
Self-supervised learning is more like supervised learning than unsupervised learning 自监督学习更像监督学习而不是非监督学习
How can we do self-supervised learning?
Word2Vec does self-supervised learning word2vec就是自监督学习
• It tries to predict context words given a central word 它通过给定一个中心单词,来预测上下文单词
• It doesn’t require labeled data 它不需要给数据打标签
• We can use any text we have lying around 我们可以使用身边的任何文本
Neural Language Model 神经语言模型
RNN language models are also self-supervised RNN语言模型也是自监督学习
• Predict the next word in the sentence given all previous words 给定句中之前所有的单词,来预测下一个单词
• Train using sentences from anywhere (Wikipedia, Reddit, Canberra times) 可以使用任何来源的句子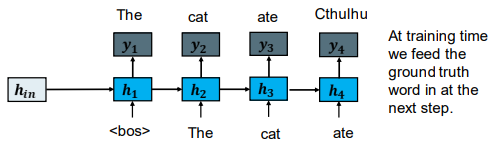
At training time we feed the ground truth word in at the next step.
在训练的时候,我们在下一步输入真实值。
Context Specific Word Representations 特定于上下文的单词表示
The RNN language models are producing context-specific word representations at each position. RNN语言模型在每个位置产生特定于上下文的单词表示。
We can use these representations for other tasks. 我们可以用这些表示来完成其他的任务。
Feature Learning 特征学习
Earlier in the course we said neural networks learn feature representations with each layer. 在课程的前面,我们说过神经网络学习每一层的特征表示。
We can use these learnt features by removing the last layer of the network. (we can also get features from other layers if available)我们可以通过移除网络的最后一层来使用这些学习到的特征。(如果可用,我们也可以从其他图层获取要素)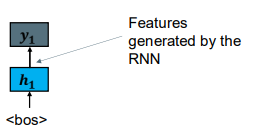
Context Specific Word Representations 特定于上下文的单词表示
Transformers for language also produce context specific word representations which we can use for other tasks. 语言transformer还产生特定于上下文的单词表示,我们可以将其用于其他任务。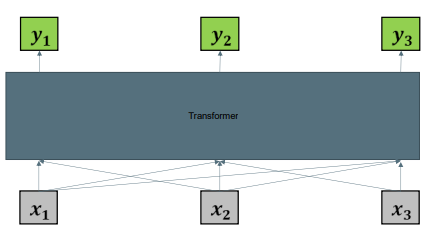
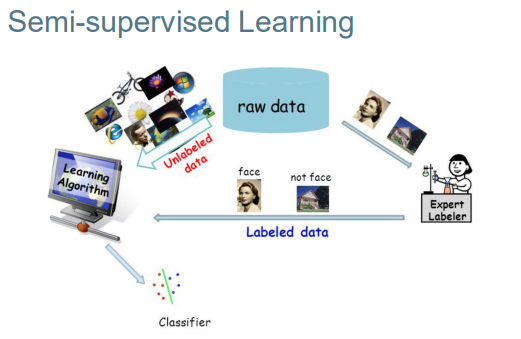
Semi-supervised Learning 半监督学习
We have an NLP task in mind (e.g. NER). Normally we would train an RNN on small labeled dataset. 我们有一个NLP任务(例如NER)。通常我们会在小的标记数据集上训练RNN。
Semi-supervised approach: 半监督学习方法:
1. Train an RNN (as a language model) on a large unlabeled text corpus, 在一个大的未标记文本语料库上训练一个RNN(作为一个语言模型)
2. Use the context specific word vectors from the RNN to train a model with a small amount of labeled data. 使用来自RNN的上下文特定的词向量来训练具有少量标记数据的模型。
For example: Peters et al. (2017): TagLM
https://arxiv.org/pdf/1705.00108.pdf
For example: Named Entity Recognition 例如:命名实体识别
• A very important NLP sub-task: find and classify names in text, for example: 一个非常重要的自然语言处理子任务: 在文本中查找和分类姓名,例如:
– The decision by the independent MP Andrew Wilkie to withdraw his support for the minority Labor government sounded dramatic but it should not further threaten its stability. When, after the 2010 election, Wilkie, Rob Oakeshott, Tony Windsor and the Greens agreed to support Labor, they gave just two guarantees: confidence and supply. 独立议员安德鲁·威尔基(Andrew Wilkie)决定撤回对少数党工党政府的支持,这听起来很戏剧性,但不应进一步威胁其稳定。当2010年大选后,威尔基、罗布·奥克肖特、托尼·温莎和绿党同意支持工党时,他们只给出了两个保证:信心和供应。
Person人员 Date日期 Location地点 Organization组织
Peters et al. (2018): ELMo: Embeddings from Language Models
Deep contextualized word representations. NAACL 2018. https://arxiv.org/abs/1802.05365
• Learns a deep Bi-RNN and uses all its layers to give contextual word vectors 学习深度双RNN,并使用其所有层给出上下文单词向量
• No fixed context window. Bounded by memory capacity of the network 没有固定的上下文窗口。受网络内存容量的限制
Applying to new problems: 应用于新问题:
Find a state-of-the-art model for your problem. Input ELMo embeddings rather than other word embeddings. 为你的问题找到一个最先进的模型。输入ELMo词嵌入,而不是其他单词嵌入。
ELMo
Elmo results Elmo 结果
Including contextual embeddings from ELMo in these existing state-of-the-art models significantly improves performance. 在这些现有的最先进的模型中包含ELMo的上下文嵌入可以显著提高性能。
Transformer Models Transformer 模型
These models are based on Transformers: 这些模型都是基于Transformers.
GPT
• GPT models are language models. GPT是语言模型
– They are trained to predict the next token in a sequence. 被训练来预测语句序列中的下一个token
• GPT did several things differently to previous models. GPT做了几件与之前模型不同的事情
1. Used Transformers. 使用Transformer
2. Used much more data. 使用了更多的数据
3. Used much more compute. 使用了更多的算力
4. A few other tricks. 一些其他技巧
Data
GPT:
Bookcorpus dataset ~1GB text
GPT-2:
Every web-page that has been linked to from Reddit with a rating of at least +3
– 3 people have deemed this link to be interesting/funny/informative.
Contains 40GB of raw text.
GPT-1,2,3 are pre-trained on next word prediction. GPT-1,2,3是预先训练的下一个单词预测。
GPT
Fine-tuning on new tasks. 对新的任务进行微调
- Modify the input structure depending on the task 根据任务修改输入结构
- Fine-tune the model on task specific data 根据任务特定数据微调模型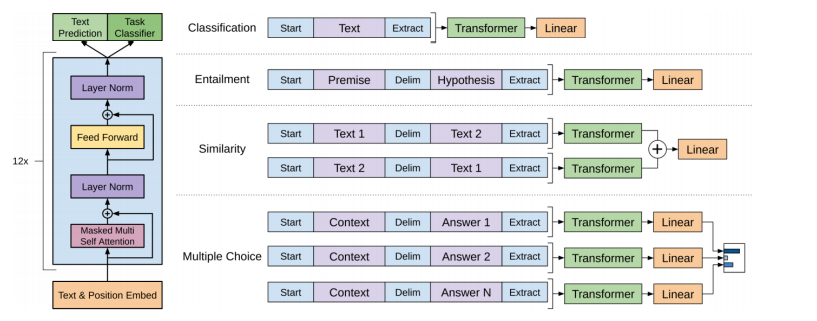
Radford, Alec, et al. “Improving language understanding by generative pre-training.” (2018).通过生成性预训练提高语言理解(2018).
Pre-Training vs Fine Tuning (GPT) 预训练和微调
Training: 训练
• Next word prediction. 下一个单词的预测
• Cross-entropy loss. 交叉熵损失
• Large amount of data (self-supervised) 大量数据供自监督学习
• Only needs to be done once. 只需要做一次
Fine-tuning: 微调
• Start the parameters from where training finished. 从训练结束开始设置参数
• Normally uses a small learning rate 通常用小的学习率
• Task specific loss 特定任务损失
• Task specific data 特定任务数据
• Needs to be done for every task 每次都需要完成为了特定的任务
• May add extra layers compared to training 与培训相比,可能会增加额外的层次
Bidirectional 双向的
• Problem: Language models only use left context or right context, but language understanding is bidirectional. 问题:语言模型只使用左语境或右语境,但语言理解是双向的。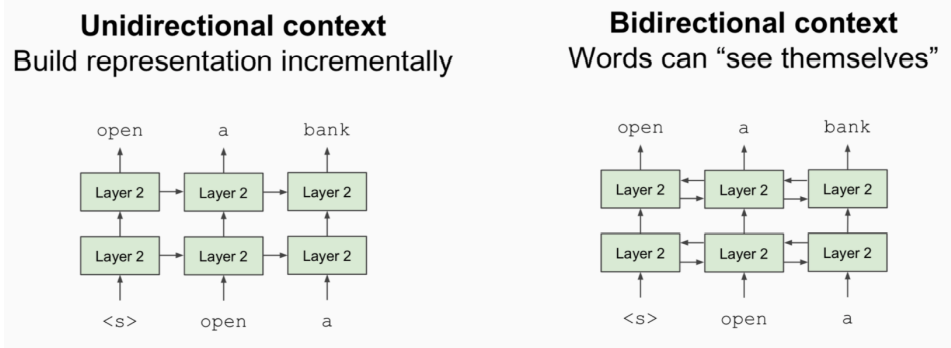
Architecture Comparison
Mask out 掩盖
• What is the probability of P(word|context)? 单词-上下文的概率
• Mask out k% of the input words, and then predict the missing words (15% in practice) 覆盖掉百分之k的输入单词,然后预测被覆盖掉的单词。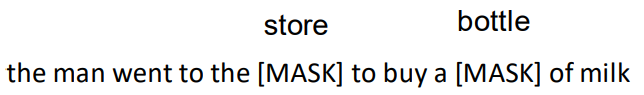
– 80% of masked words are replaced with [MASK] 百分之80的单词被替换成[mask]
– 10% are replaced with another random word 百分之10被替换成其他的随即单词
– 10% are left the same 百分之十仍然保持
BERT: Next sentence prediction Bert:预测下一个句子
• To learn relationships between sentences, predict whether Sentence B is actual sentence that proceeds Sentence A, or a random sentence. 要学习句子之间的关系,预测句子B是进行句子A的实际句子,还是随机句子。
BERT: Sentence pair encoding 句子对编码
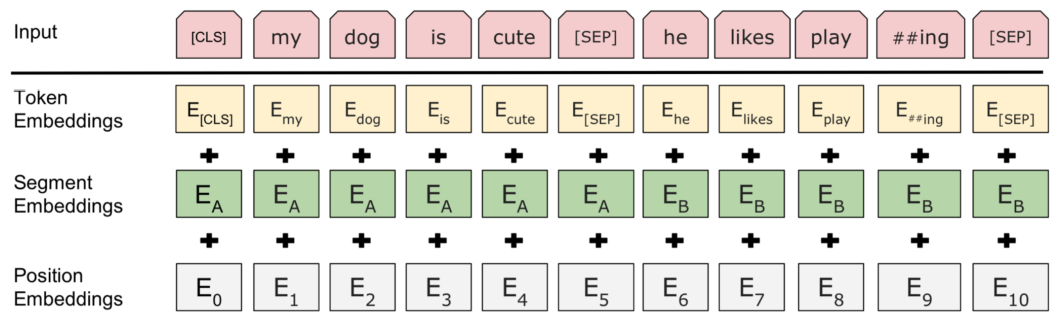
Token embeddings are word pieces Token 嵌入是单词片段
Learned segmented embedding represents each sentence 学习的分割嵌入代表每个句子
Positional embedding is as for other Transformer architectures 位置嵌入与其他Transformer的架构一样。
BERT model fine tuning
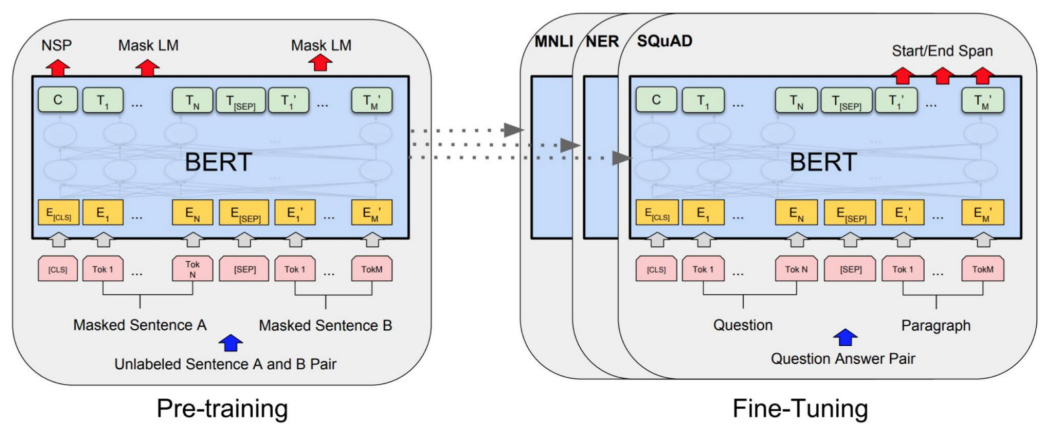
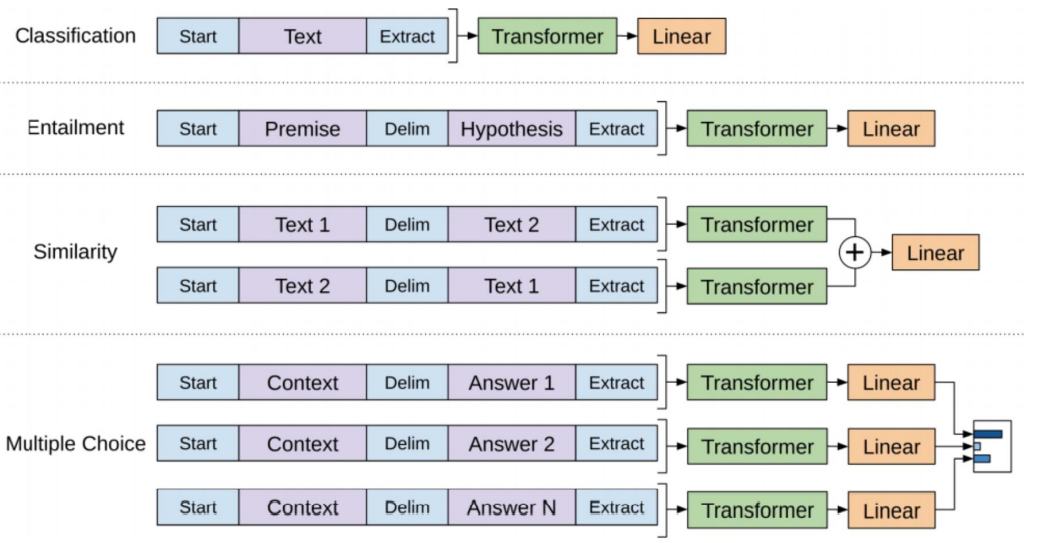
Using BERT on multiple tasks
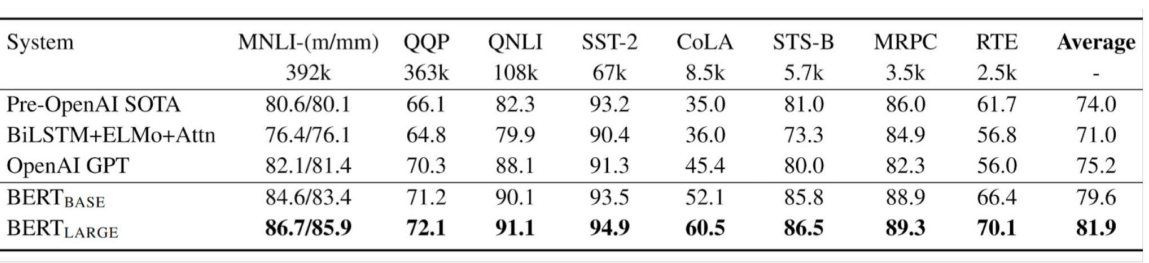
BERT results on GLUE tasks
XLNet
• A regular language model only predicts the next token in a sequence for one ordering. 常规语言模型只预测一个排序序列中的下一个标记。
• XLNet randomly samples an ordering then constructs the sequence in that order.XLNet随机采样一个顺序,然后按照该顺序构建序列。
• Given sentence “quick brown fox”
• Sample random order 2,1,3
• Given no information, try to predict the word at position 2. 在没有信息的情况下,尝试预测位置2的单词。
• Given that the word at position 2 is “brown”, try to predict the word at position 1. 假设位置2的单词是“棕色”,尝试预测位置1的单词。
• Given that the word at position 2 is “brown” and the word at position 1 is “quick”, try to predict the word at position 3.假设位置2的单词是“棕色”,位置1的单词是“快速”,尝试预测位置3的单词。
Summary
• We can train large language models using text on the web 我们可以使用网络上的文本来训练大型语言模型
• We can use the outputs of these models as drop-in replacements for other word-vectors. 我们可以将这些模型的输出作为其他单词向量的替代。
• Or we can make small modifications then fine-tune these models for specific tasks 或者我们可以做一些小的修改,然后针对特定的任务对这些模型进行微调

若有收获,就点个赞吧
0 人点赞
