An object is a contextual outlier (or _conditional outlier) _if it deviates significantly with respect to a specific context of the object.
如果一个对象相对于该对象的特定上下文有显著的偏离,则该对象是上下文离群值(或条件离群值)。
The context is defined in the values of identified contextual attributes of the object, such as location, time or demographic. The remaining attributes of the object are called behavioural attributes. 上下文是在对象的已识别上下文属性的值中定义的,例如位置、时间或人口统计。对象的其余属性称为行为属性。
**
Applications:
- Detect a credit card holder with expenditure patterns matching millionaires in a context of low income
- Do not detect as an outlier a millionaire with high expenditure, given a context of high income
- Detect people with unusual spending or travelling patterns in a context of demographics and income for target marketing
- Detect unusual weather in a context of season and locality
Method 1: Transform into Conventional Outlier Detection 转化为传统的离群值检测.
- Use the context attributes to define groups 使用上下文属性定义组
- Detect outliers in the group based on the behavioural attributes alone, using a conventional outlier detection method 使用常规异常值检测方法,仅根据行为属性检测组中的异常值
Method 2: Model normal Behaviour wrt Contexts 在工作环境中模拟正常行为
Used when it is not so easy to choose a the significant set of contextual attributes from the data you have. 当从你的数据中选择一组重要的上下文属性不是那么容易的时候使用。
- Using a training data set, build a predictive model for the “normal” behaviour from all the context attributes 使用训练数据集,从所有上下文属性中为“正常”行为建立预测模型
- An object is a contextual outlier if its behaviour attribute values significantly deviate from the values predicted by the model 如果对象的行为属性值明显偏离模型预测的值,则该对象是上下文异常值
B. Collective Outliers 集体离群值
A group of data objects forms a collective outlier if the objects as a whole deviate from the entire data set, even though each individual is not an outlier alone.尽管每个数据点单独都不是离群值,但他们共同组成了集体离群值集合。 They are difficult to find because of the need to take into account the structure of the data set, ie relationships between multiple data objects, e.g. black dots in following diagram
很难找到,因为他们需要考虑到数据集中的具体结构。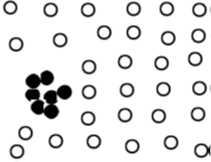
Each of these structures is inherent to its respective type of data 这些结构中的每一个都是其各自的数据类型所固有的
- For temporal data (such as time series and sequences), we explore the structures formed by time, which occur in segments of the time series or subsequences 对于时间数据,我们搜索由于时间形成的数据机构,它出现在时间序列或者子序列中。
- For spatial data, explore local areas 对于空间数据,我们探索本地区域。
- For graph and network data, we explore subgraphs 对于图、网结构,我们探索子图。
Difference from contextual outlier detection: the structures are often not explicitly defined, and have to be discovered as part of the outlier detection process. 和上下文异常值检测的区别: 结构通常没有被明确定义,需要作为异常检测过程的一部分被发现。
Method 1: Reduce the problem to conventional outlier detection 将问题简化为传统的离群点检测
- Identify structure units (e.g., subsequence, time series segment, local area, or subgraph) 识别结构单元(如子序列、时间序列段、局部区域或子图)
- Treat each structure unit, representing a group of original data objects, as a single data object 将代表一组原始数据对象的每个结构单元视为单个数据对象
- Extract or transform features into a conventional attribute type for that structured object 提取特征或将特征转换为该结构化对象的常规属性类型
- Use outlier detection on the set of “structured” data objects constructed using the extracted features 对使用提取的特征构建的一组“结构化”数据对象使用异常检测
- A structured object, representing a group of objects in the orginal data, is an outlier if that object deviates significantly from the others in the transformed space. 表示原始数据中的一组对象的结构化对象,如果该对象明显偏离变换空间中的其他对象,则是异常对象。
Method 2: Direct Modelling of the Expected Behaviour of Structure Units 结构单元预期行为的直接建模
Example
- Detect collective outliers in online social network of customers
- Treat each possible subgraph of the network as a structure unit
- Collective outlier: An outlier subgraph in the social network
- Small subgraphs that are of very low frequency
- Large subgraphs that are surprisingly frequent
Example.
- Detect collective outliers in temporal sequences 从序列中学习马尔可夫模型
- Learn a Markov model from the sequences 从序列中学习马尔可夫模型
- A sub-sequence can then be declared as a collective outlier if it significantly deviates from the model. 如果一个子序列明显偏离模型,那么它可以被宣布为集体异常值。
Strengths and Weaknesses
- Collective outlier detection is subtle due to the challenge of exploring the structures in data
- The exploration typically uses heuristics, and thus may be application dependent rather than generally applicable.
- The computational cost is often high due to the sophisticated mining process
- 由于探索数据结构的挑战,集体离群点检测很微妙
- 探索通常使用试探法,因此可能依赖于应用程序,而不是普遍适用。 由于复杂的采矿过程,计算成本通常很高

若有收获,就点个赞吧
0 人点赞
