- Representation
- Meaning 含义
- Word representation
- Word Representation (One-hot)
- Context-based Word Representation
- Word Co-occurrence Matrix
- Pointwise Mutual Information 逐点交互信息
- Similarity with Pointwise Mutual Information 逐点交互信息的相似性
- Drawbacks of a Sparse Representation 稀疏表示的缺点
- Singular Value Decomposition 奇异值分解
- Word2Vec
- Word2Vec as Logistic Regression
- Word2Vec: Model
- Word2Vec (Objective)
- Word2Vec: Practical considerations
- Better Document Representations
- Summary
Representation
Text represented as a string of bits/characters/words is hard to work with: 字符串文本很难用来机器学习
• Variable length 可变的长度
• High dimensional 高维
• Similar representations may have very different meanings How can we represent text a different way? 相似的表达可能含有不同的涵义,怎样用不同的方式表达
Meaning 含义
Meaning: what is meant by a word, text, concept, or action. (useless recursive definition from the dictionary) 一个词、文本、概念或行为的含义。 (字典中的无用递归定义)
Meaning in language is:
• Relational (based on relationships) 联系
• Compositional (built from smaller components) 成分
• Distributional (related to usage context) 分布
• Simple document representation 简单的文档表述
• Word representation
– Co-occurrence and Latent Semantic Analysis 共现与潜在语义分析
– Word2Vec 单词 —> 向量
Document Representation
Document:

Vector Model in IR 信息索引中的向量模型
Vector space model of retrieval (from IR)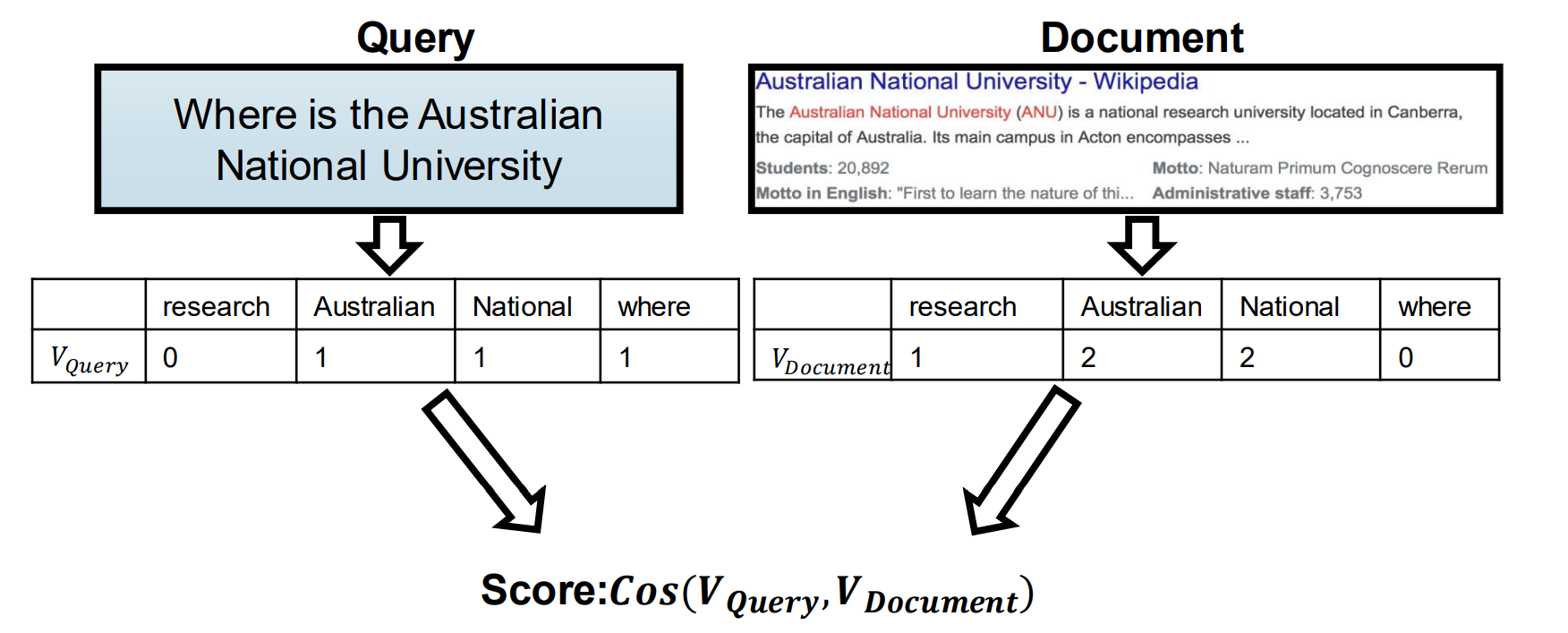
Representing documents
We can represent documents as vectors of the words/terms they contain (BoW model): 我们可以将文档表示为它们包含的单词/术语的向量(BoW模型):
Vector may be
• Binary occurrence
• Word count
• TFIDF scores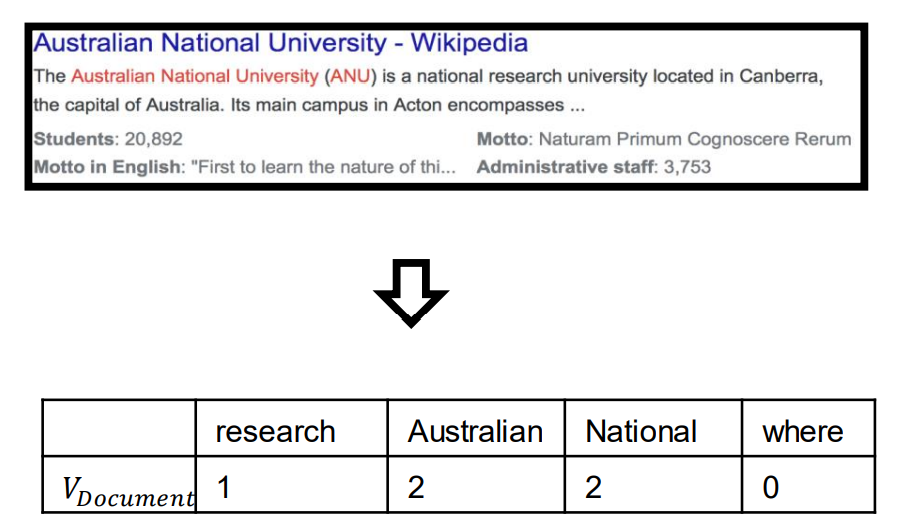
Representing documents
The vector representation may be the size of the vocabulary ~ 50000 words is common. 向量表示法可能是词汇量的大小~ 50000字是常见的。
Very inefficient for many documents. 对于很多文档来说,效率很低下
Fortunately, most documents do not contain most words so we can use a sparse representation with tuples of the form: (term_id, term_count) for tuples where term_count > 0 幸运的是,大多数文档不包含大部分单词,所以我们可以用tuple来稀疏表示,(term_id, term_count)
The above document: (0, 1), (1, 2), (2, 2), (4, 1) …
We can then use our ~50000 dimensional sparse vector for document classification and other tasks:
You typically do not have to roll your own sparse vector representation, there are many libraries. 通常不需要自己做稀疏向量,有许多第三方库可以直接应用。
sklearn returns a scipy sparse matrix when you call one of the vectorizers such as CountVectorizer 当您调用其中一个向量器(如CountVectorizer),sklearn返回一个scipy稀疏矩阵
The LogisticRegression class in sklearn will accept sparse matrices as input (it will also accept dense matrices) sklearn中的LogisticRegression类将接受稀疏矩阵作为输入(它也将接受密集矩阵)
Word representation
Word Representation (One-hot)
In traditional NLP, we regard words as discrete symbols:
hotel = 10 = [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0]
motel = 7 = [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0]
Vector dimension = number of words in vocabulary (e.g., 50,000)
Similar words do not have similar vectors 相似的单词表示成词向量后没有便没有相似
Context-based Word Representation
关注上下文语境
Context of a word: Sentence
I am a student at the Australian National University. Research school of Computer Science is part of our university. Our university is an organisation for education. …
The context words will represent ‘university’!
Context of a word: Window
Use k words on either side of the focal word as the context 使用目标单词前后的k个单词作为上下文
for example:
In Australia a large university will often have a big Campus. 在澳大利亚,大学通常有很大的校园
The university employs academics and professional staff. 这所大学雇佣的学术和专业人员。
Context-based Word Representation 基于上下文的单词表示

Word Co-occurrence Matrix
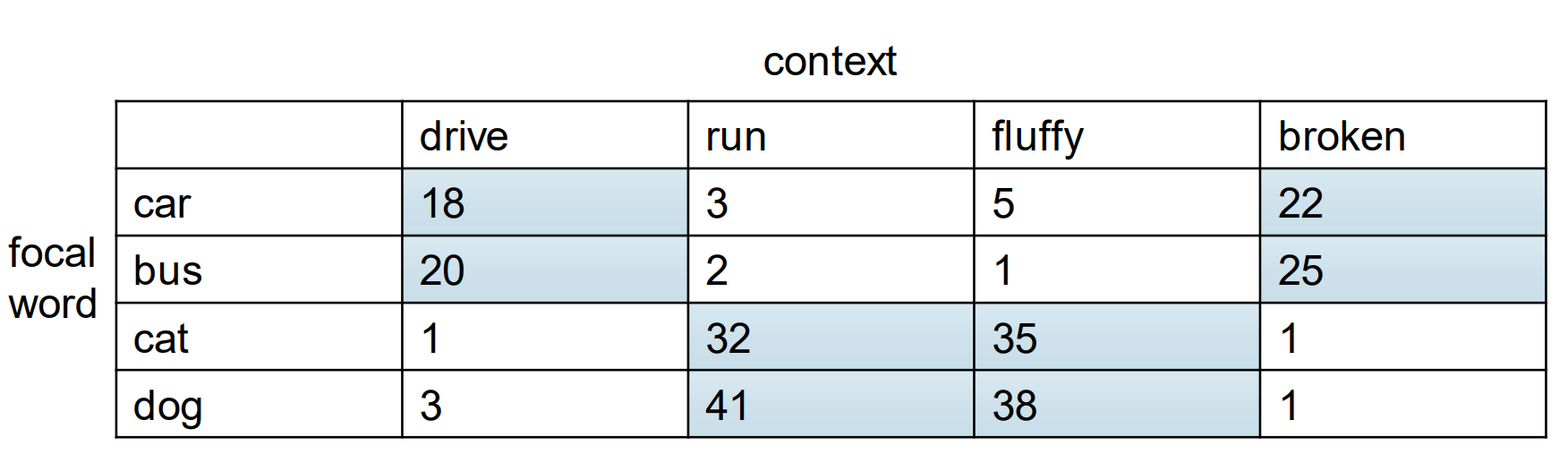
A co-occurance matrix of words gives a vector representation for each word.
- This gives equal importance to all context words 这里将所有的上下文单词赋予相同的权重,有相等的重要性。
Weighting 权重
We want to weight each of the terms in the vector. 我们相对向量中的词项进行权重赋值。
We can use tf-idf (refer to IR material)
To compute document frequency there are some alternatives: 有一些计算文档频率的变种
• Consider each context as a document 将上下文视作文档
• Use documents to compute df 使用文档来计算 文档频率
A more common method for co-occurance matrices is to weight by: 更通用广泛的共生矩阵权重方法
PPMI: Positive Pointwise Mutual Information 积极逐点互信息
**
Pointwise Mutual Information 逐点交互信息
The amount of information the occurrence of a word 𝑤𝑖 gives us about the occurrence of another word 𝑤𝑗 . (and vise versa) 一个词𝑤𝑖的出现给了我们关于另一个词𝑤𝑗的出现的信息量。(反之亦然)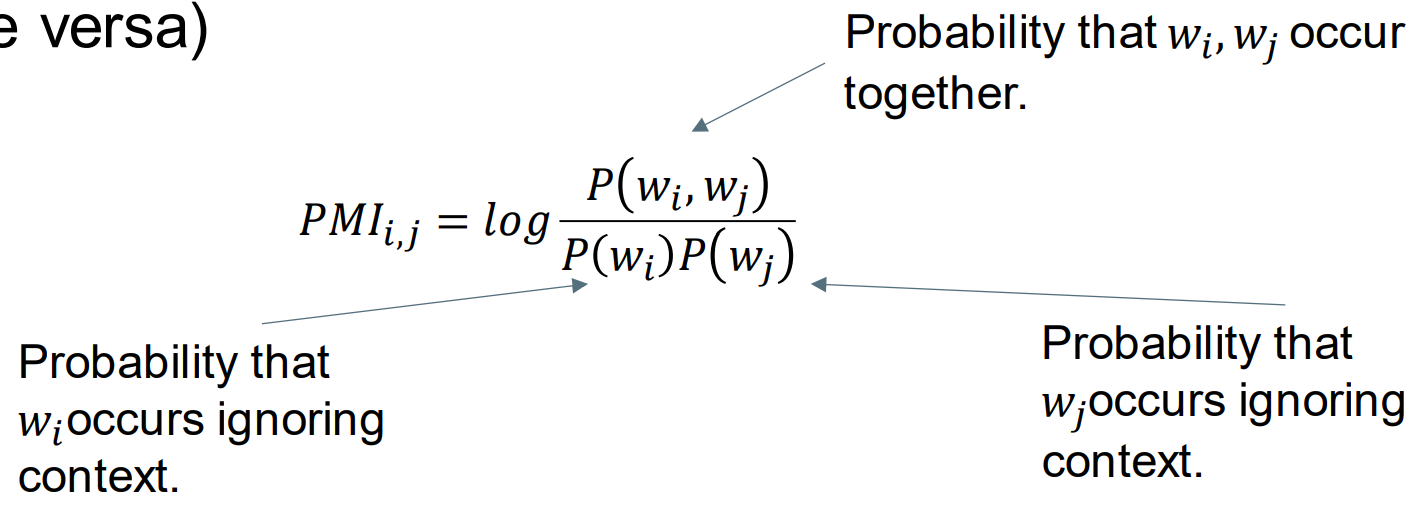
The ratio of the probability that the words occur together compared to the probability that they would occur together by chance. 单词一起出现的概率与它们偶然一起出现的概率之比。
Positive Pointwise Mutual Information 正 逐点交互信息
PMI can be negative when words occur together less frequently than by chance. 当单词一起出现的频率低于偶然出现的频率时,PMI可能为负
Typically, negative values are not reliable. 通常来说,负值并不可靠。
We set them to 0: 因此我们将这些数值设置为0
𝑃𝑃𝑀𝐼 = max(0,𝑃𝑀𝐼)
Similarity with Pointwise Mutual Information 逐点交互信息的相似性

Drawbacks of a Sparse Representation 稀疏表示的缺点
The raw count / tf-idf / PPMI matrix is: High dimensional, thus more difficult to use in practice. 原始计数/ tf-idf / PPMI矩阵为: 高维,因此更难在实践中使用。
Suffers from sparsity. For example, if: “puppy” occurs frequently with “training”, “food”, “woofing” “dog” occurs frequently with “working”, “eating”, “barking” 受到稀疏的困扰。例如,如果:“小狗”经常出现在“训练”、“食物”中,“狗”经常出现在“工作”、“进食”、“吠叫”中
We want to say “puppy” is similar to “dog” because the words that occur with each are similar (even if the words they occur with are not the same). 我们要说“小狗”和“狗”相似,是因为它们各自出现的词是相似的(即使它们出现的词不一样)。
Singular Value Decomposition 奇异值分解
Generalized eigen decomposition: 广义特征分解
1. Perform SVD
2. Take the top k vectors in U,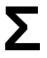
3. To get a dense word representation compute U,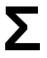
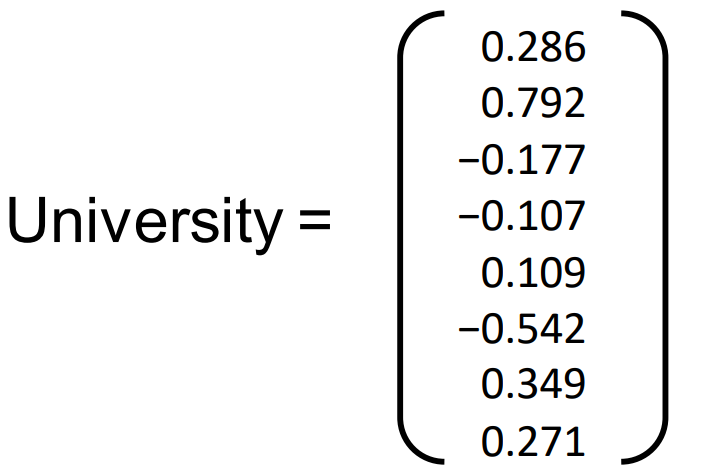
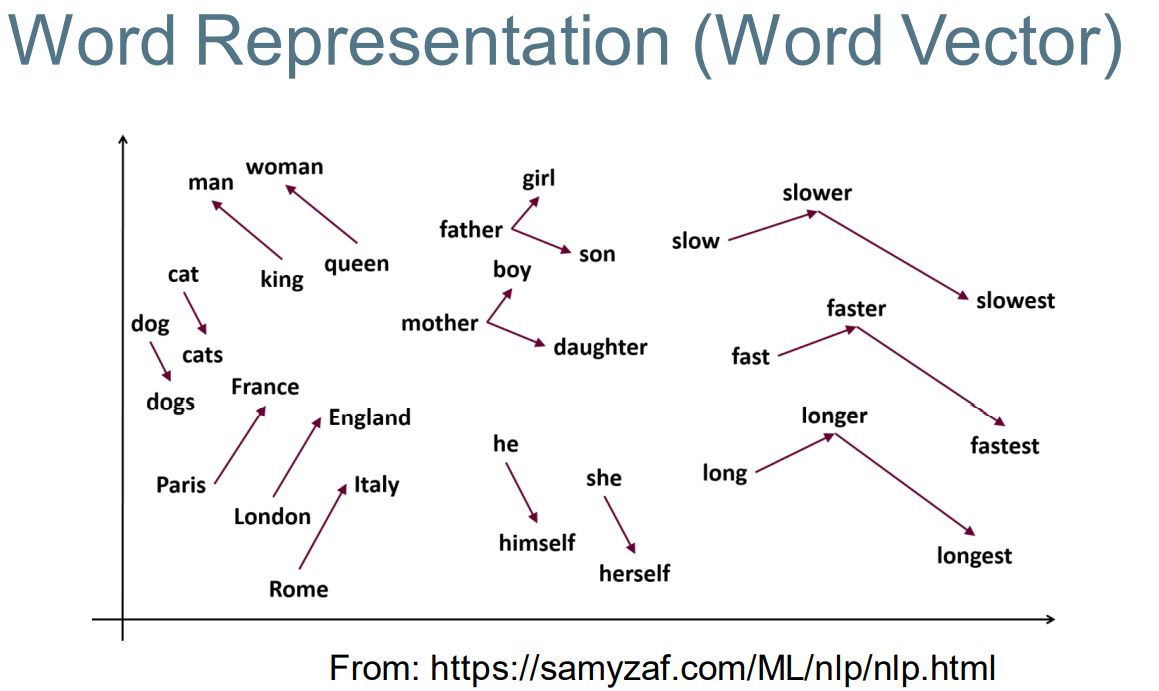
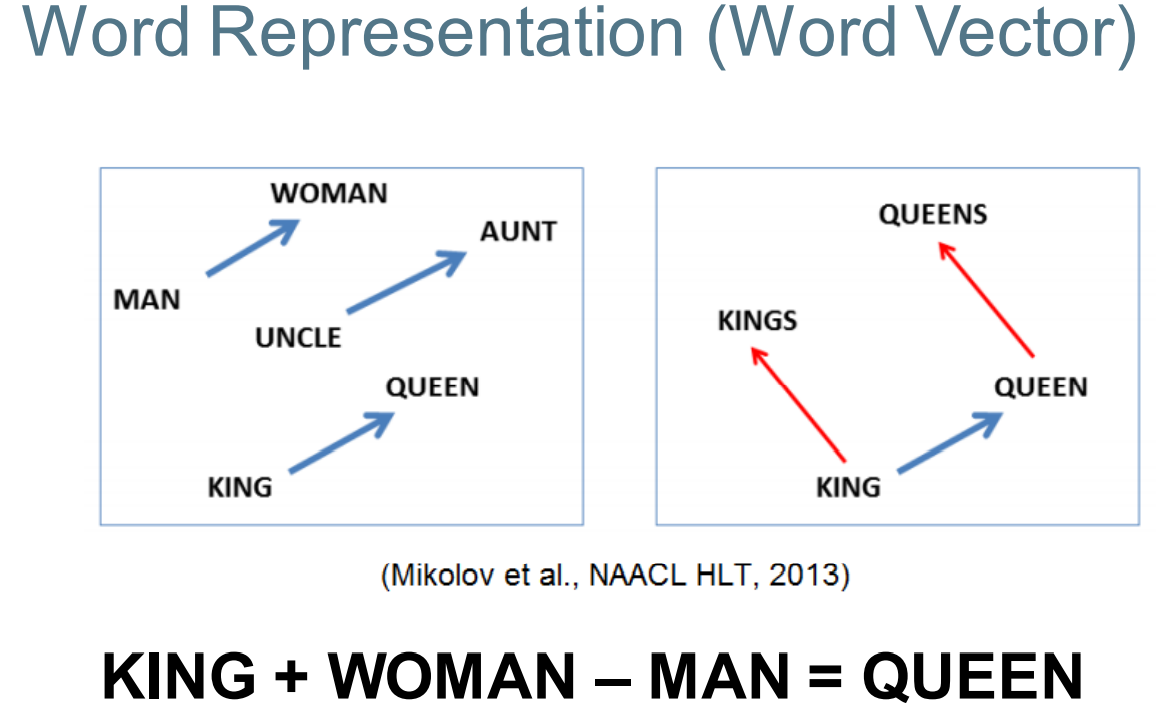
Note: dense word vectors are sometimes called word embeddings or word representations. They are distributed representations. 注意:密集的单词向量有时被称为单词嵌入或单词表示。它们是分布式表示。
Typical number of dimensions: 64, 128, 256, 300, 512, 1024 典型维度尺寸: 64、128、256、300、512、1024
Word2Vec
Several Word2Vec Algorithms: Most common is skip-gram with negative sampling 最常见的是负采样的skip-gram滑动窗口
Approach:
• A self-supervised classification problem 自我监督的分类问题
• We learn word embeddings to do classification 我们学习单词嵌入来进行分类
• In the end we care only about the embeddings 最终,我们只关心单词嵌入
Word2Vec: Skip-gram (Overview)
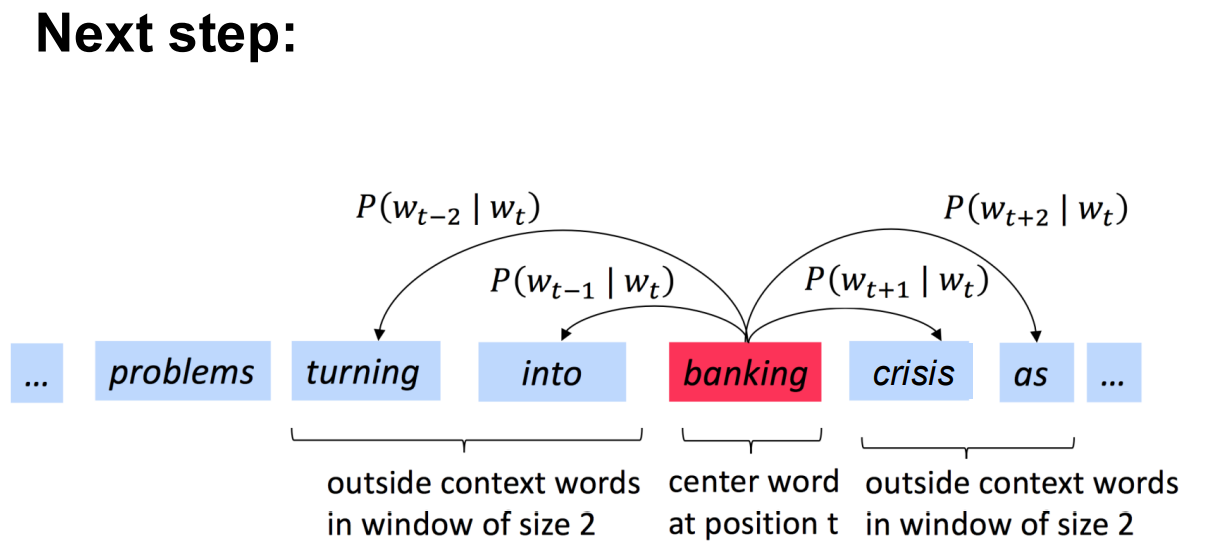
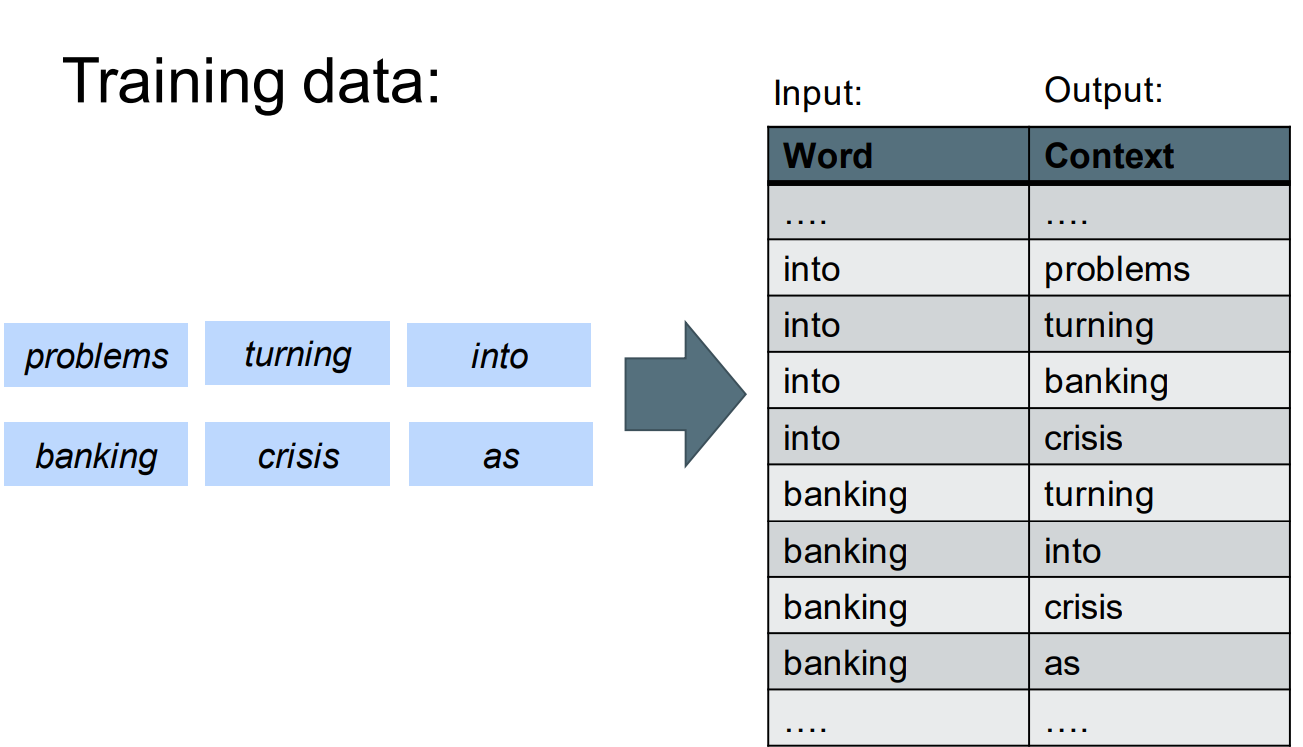
Given center word 𝒘𝒕 , predict context words in window 𝒋 ∈ [−𝒎, 𝒎], by 𝑷(𝒘𝒕+𝒋 |𝒘𝒕 ) 通过中心词去预测滑动窗口中的上下文单词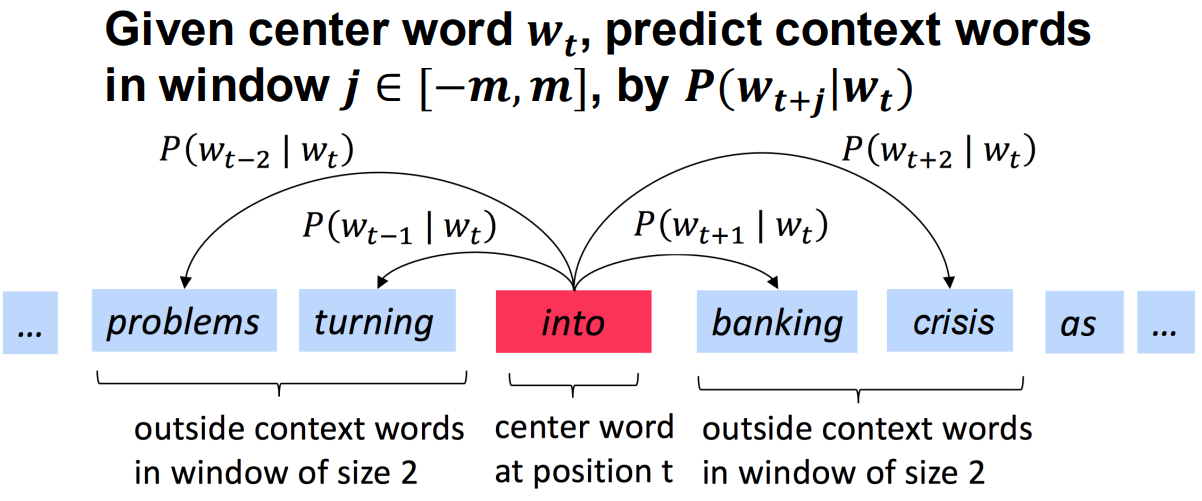
Word2Vec as Logistic Regression
Word2Vec uses a multinomial logistic regression classifier (without a bias term): Word2Vec使用多项逻辑回归分类器(无偏差项)
P(y | x) = softmax ( 𝑊𝒙 )
Here y is the context word and x is an embedding of the center word. 这里y是上下文单词, x是中心单词的词嵌入向量
In this model we can interpret the matrix W as being composed of embedding of the context words. 在该模型中,我们可以将矩阵W解释为由上下文单词的嵌入组成。
Word2Vec: Model
How to calculate 𝑷(𝒘𝒕+𝒋 |𝒘𝒕 ; 𝜽) ?
Once trained with cross-entropy loss we use 𝑣𝑐 as the word embedding and throw everything else away.
When we train word2vec we also train the center word embeddings. 我们通过训练word2vec模型,同时训练得到了中心单词的词嵌入向量
How:
• Start with random embeddings 从随机词向量开始
• Backpropagation to compute gradient (next lecture) 反向传导计算梯度
• Gradient descent 梯度下降
Word2Vec (Objective)
Loss function (average cross entropy) 损失函数(平均交叉熵): 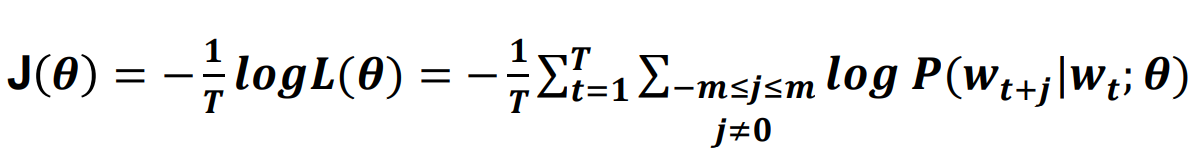
The normalizing factor in 𝑷(𝒘𝒕+𝒋 |𝒘𝒕 ; 𝜽) is often approximated by negative sampling.
See the textbook if you want to know more.
Word2Vec: Practical considerations
Context window size is very important: w2v randomly samples different sized windows. 滑动窗口的尺寸很重要
• This implicitly increases the weight of words that are close to the center word.
word2vec also down-samples common words
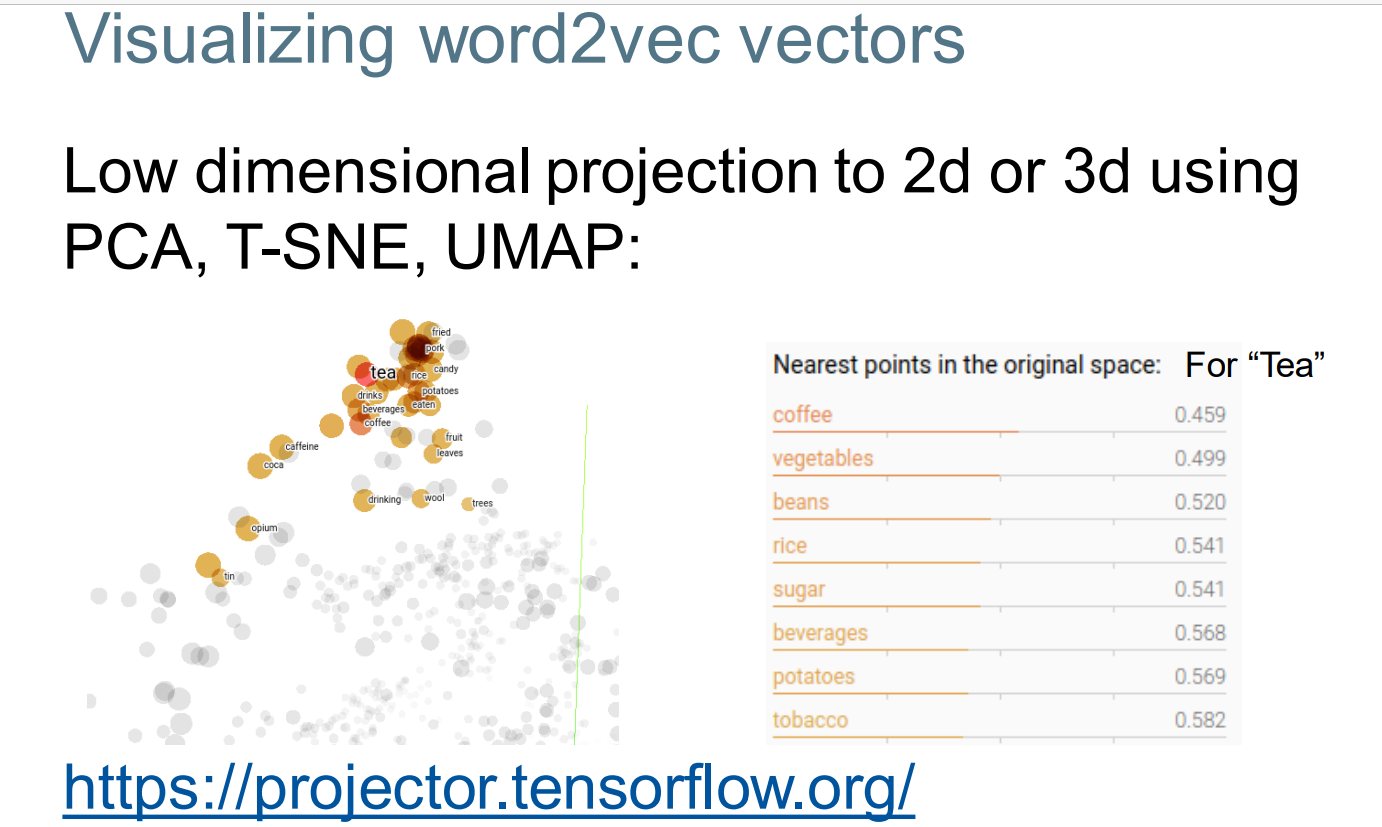
Better Document Representations
Meaning is compositional:
• Go for word embeddings to document embeddings by combining word embeddings 通过组合单词嵌入,从单词嵌入到文档嵌入
Methods for combining embeddings:
• Simple Aggregation (sum, mean, max …) 简单聚合(总和、平均值、最大值……)
• Convolutional Neural Network (CNN) 卷积神经网络
• Recurrent Neural Network (RNN) 递归神经网络(RNN)
• Transformer
Summary
• Represent documents using tf, idf, PPMI
• Word co-occurrence matrix (with matrix factorization)
• Word2Vec

若有收获,就点个赞吧
0 人点赞
