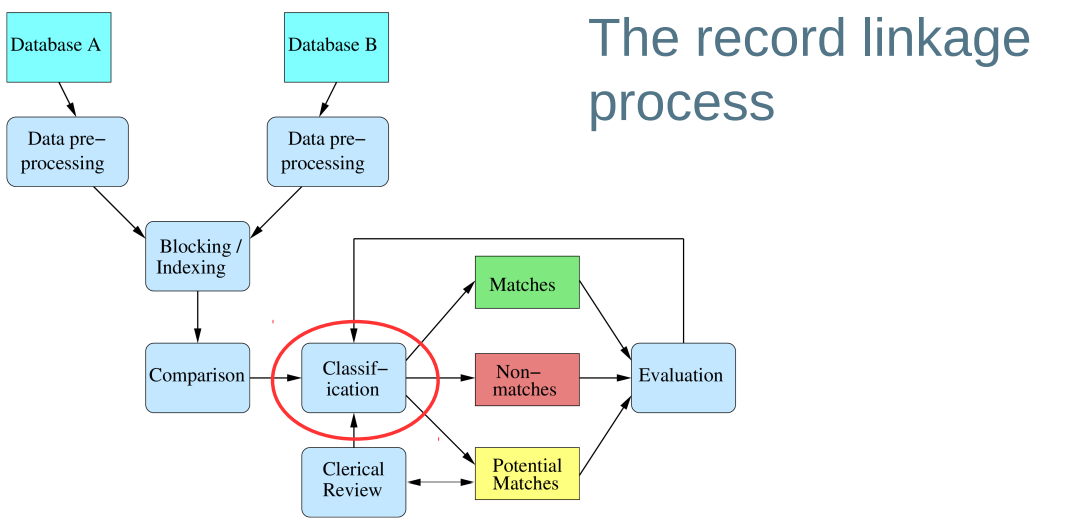
Classifying record pairs
● The comparison step generates one vector of similarities (also known as weight vector) for each of compared record pair 在比对步骤为每个比较的记录对生成了一个相似度向量(权重向量)
● The elements of such vectors are the calculated similarities (exact or approximate) 每个向量都是拿来计算相似度的,(精确或近似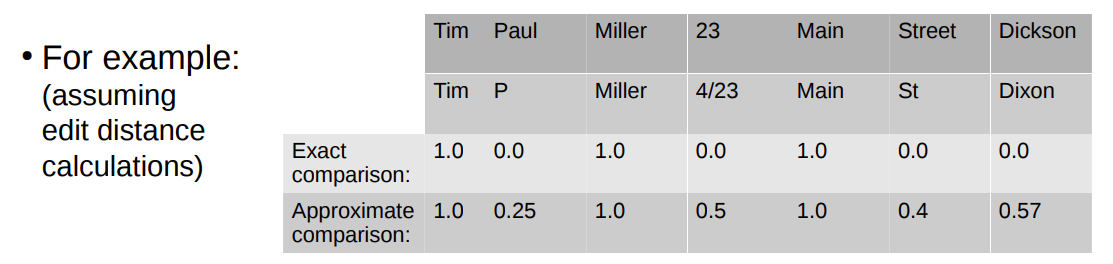
● Classifying record pairs can be based on 分类记录配对可以基于
(a) summing the calculated similarities into a single similarity values, or 累加相似度成一个相似值
(b) using the full vector of similarities 使用完整的相似向量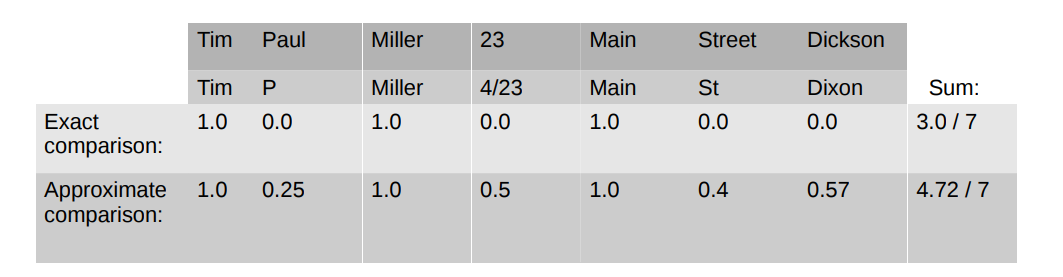
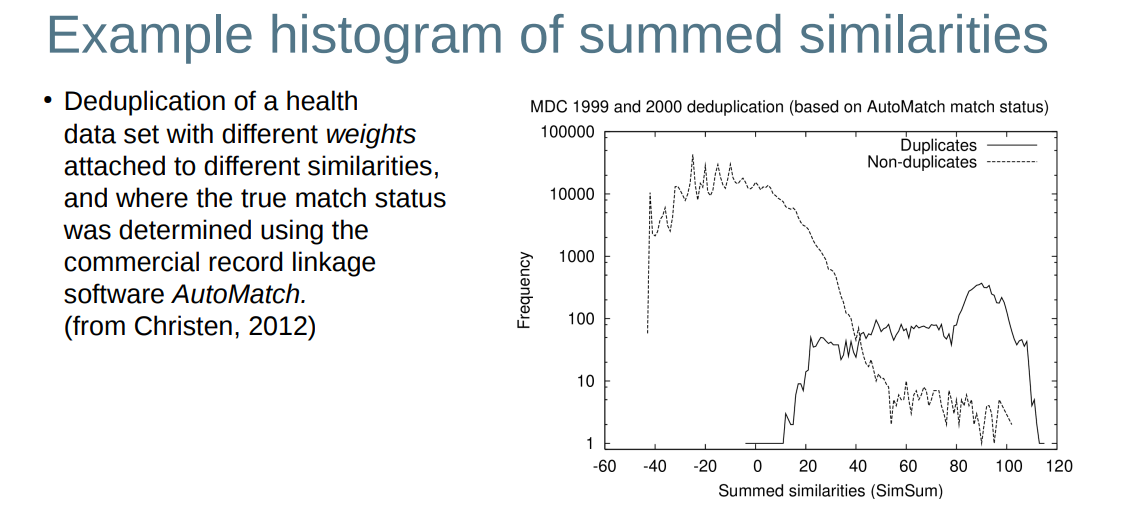
Threshold based classification 基于阈值的分类
● Is generally applied on summed similarities 通常应用于相似度总和
● Can either use one or two similarity thresholds 可以使用一到两个相似度阈值
– One threshold t(一个阈值t): 0 ≤ t ≤ sim(max) , where sim(max) is equal to the number of similarities in the vectors 相似度最大值等于向量中的相似性数量
(a) Record pairs with a similarity of at least t → Classified match 记录配对相似度有至少t ——> 分类匹配
(b) Record pairs with a similarity below t → Classified non-match 反之低于t,则不匹配。
– Two thresholds t(l) and t(u) : 0 ≤ t(l) < t(u) ≤ sim(max) 两个阈值,
(a) Record pairs with a similarity of at least t u → Classified match 若至少为t(u),则匹配
(b) Record pairs with a similarity below t l → Classified non-match 低于t(i),则不匹配
(c) Record pairs with a similarity between t l and t u → Classified potential match 介于之间,则部分匹配
● If similarities are simply summed then each attribute has the same importance (or same weight) 如果相似度被简单的累加起来,则意味着每个属性都有相同的权重
– Does having the same gender say as much about two records being about the same person as having the same postcode? 相同的性别和相同的邮编中的含义不同
● A weighted sum approach provides more weight to attributes that contain more information 带权重的累加可以提供更多的信息
– Weights can be based on domain knowledge 权重可以基于定义域知识
– Or they can be calculated based on the number of unique values in an attribute a:
w(a) = log(number of unique attribute values)
也可以用属性中的唯一值数量来计算
● Total similarity is then a weighted sum: 相似度总和就成为带权重的累计和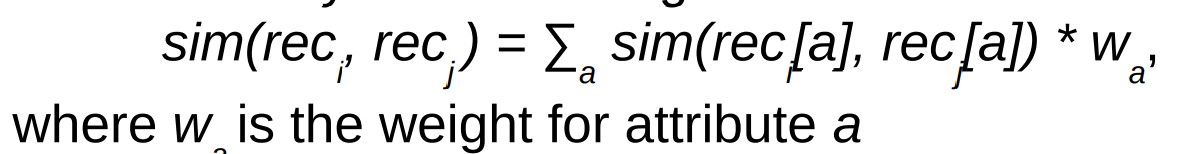
● To normalise this similarity into the 0..1 interval we can divide 为了标准化相似度到0-1的范围内,我们可以除以权重的总和
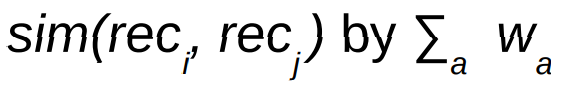
● Further weight calculations take the frequencies of values into account 进一步的权重计算将数值的频率也计入考虑
– Two records with the common surname “Smith” are less likely to refer to the same person compared to two records with the rare surname ‘Dijkstra’
比如说,相比于一个更罕见的名,smith是个很普遍的名,不一定能确认有这样的名是一个人。
Probabilistic classification 可能性分类
● Known as probabilistic record linkage 可以理解为概率记录链接
– Basic ideas were introduced by Newcombe and Kennedy in 1962
– Theoretical foundation by Fellegi and Sunter in 1969
● Basic idea 基础思想:
– Compare common record attributes (or fields) using approximate (string) comparison functions 相较于普通的记录属性配对,更倾向于使用近似配对函数
– Calculate matching weights based on frequency ratios (global or value specific ratios) and error estimates 基于出现频率或者错误估计,计算匹配权重
– Sum of the matching weights is used to classify a pair of records as a match, non-match, or potential match (using two thresholds) 匹配权重的总和将记录配对分为 匹配,不匹配和部分匹配(两个阈值)
● Problems: Estimating errors, find optimal thresholds, assumption of independence, and manual clerical review
估计错误、找到最佳阈值、假设独立性和人工文书审核
● A ratio R is calculated for each compared record pair r = (a,b) in the product space A × B: 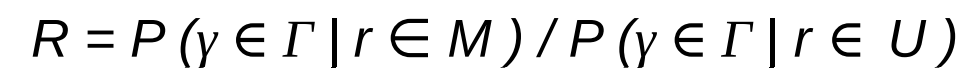
where M and U are the sets of true matches and true non-matches, and γ (gamma) is an agreement pattern in the comparison space Γ (Gamma), with:
A × B = {(a, b) : a ∈ A, b ∈ B} for files (data sets) A and B
M = {(a, b) : a = b, a ∈ A, b ∈ B} True matches
U = {(a, b) : a ≠ b, a ∈ A, b ∈ B} True non-matches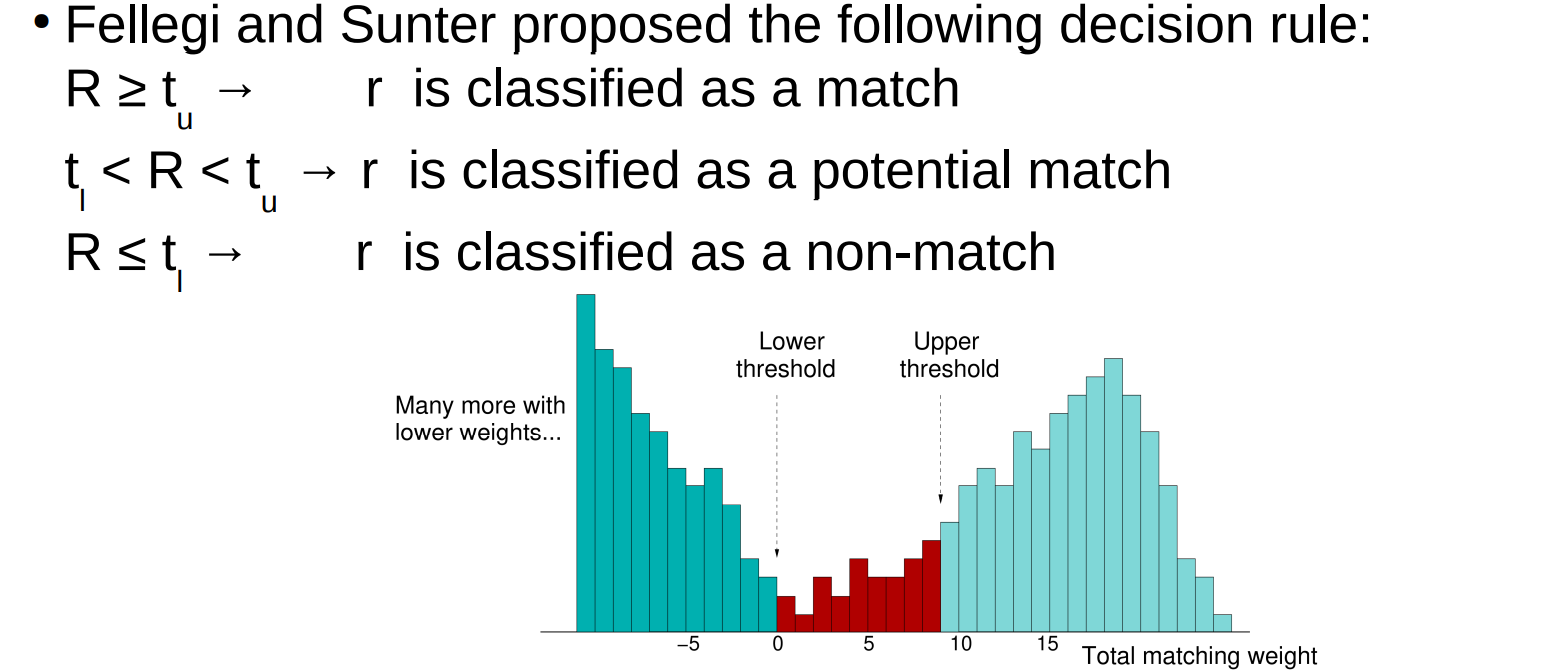


Cost Base classification 基于错误成本的分类匹配
● In record linkage classification we can make two types of mistakes 记录连接分类的过程中 我们可能会犯以下的错误。
(1) A record pair that is a true match (same entity) is classified as a non-match (false negative) 误判true match 成 non-match 假阴
(2) A record pair that is a true non-match (different entities) is classified as a match (false positive) 假阳
● Traditionally it is assumed both types of errors have the same costs 一般假设这两种错误有相同的cost
● Question: In which applications / situations do these two types of errors have different costs? 不同的环境任务,这两种错误有不同的影响
● If costs for mis-classification are known (or can be estimated), a cost-optimal decision can be made 如果错误分类的成本是已知的(或者是可以估计的),就可以做出成本最优的决策
● Based on the probabilistic record linkage approach (previous lecture), 基于概率记录链接方法,我们可以对记录配对r计算总的错误成本
for record pair r we can calculate the overall cost c as: 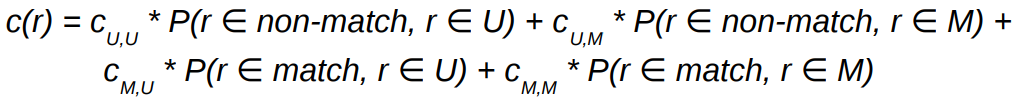
where the record pair is classified as a match or non-match while its true match status is M or U 其中记录对被分类为匹配或非匹配,而其真实匹配状态是M或U
● The aim is to minimise the overall costs c for all record pairs 目标是最小化总和c
Rule based classification 基于规则的分类匹配
● A different approach compared to probabilistic record linkage 与概率记录链接不同的方法
● A set of rules is used to classify a record pair as a match or non-match (and possibly a potential match) 有一套规则来判定记录是匹配,不匹配或者部分匹配
● Rules are applied on the calculated attribute similarities, where individual tests are combined using logical operations (AND, OR, NOT) 规则应用于计算出的属性相似性,其中使用逻辑运算(与、或、非)组合各个测试
● The ordering of rules is important if different rules in a rule set classify a record pair into matches and non-matches (i.e. which rules are applied first)
(several rules might trigger (be true) for a given record pair) 如果规则集中的不同规则将记录对分为匹配和不匹配(即首先应用哪些规则),则规则的排序很重要
(对于给定的记录对,可能会触发(为真)几个规则)
● Rules should have high accuracy and high coverage 规则应该具有高准确性和高覆盖率
– High accuracy means they correctly classify record pairs that are covered by the rule into their correct class (of matches and non-matches) 高准确性意味着他们能够正确分类以下记录对 被规则覆盖到它们正确的类别(匹配和 不匹配)
– High coverage means a rule covers a large number of all record pairs (not just a few) 高准确性意味着他们能够正确分类以下记录对 被规则覆盖到它们正确的类别(匹配和 不匹配)
● Rule sets can be build manually or they can be learned 规则可以手动制定,也可以通过学习
– Manually based on domain knowledge (time-consuming and expensive) 手动基于领域知识(耗时且昂贵)
– Learning based requires training data in the form of true matching and non-matching record pairs 基于学习需要真实匹配和非匹配记录对形式的训练数据
Machine learning based classification 基于机器学习的分类
● Machine learning algorithms learn patterns, classes, rules, or clusters from data 机器学习算法从数据中学习模式、类、规则或聚类
● Supervised techniques require training data in the form of ground truth (for record linkage: record pairs of true matches and true non-matches) 监督学习需要真实的训练集(真实匹配、不匹配的记录对)
– These are classification and regression techniques 有分类、回归方法
– Example techniques are decision trees, support vector machines, neural networks, logistic regression, Bayesian classifiers, etc. 决策树、支持向量机、神经网络、逻辑回归、贝叶斯分类。
● Unsupervised techniques do not require training data 非监督学习不需要训练集
– They cluster similar data points, or extract frequent patterns and rules from data 将相似的数据点聚类分析,或提取数据频率模式,规则等。
– Example techniques are clustering and association rule mining 聚类分析、相关规则挖掘
● Many machine learning techniques have been used / adapted for record linkage
● A major challenge for supervised techniques is to obtain training data of good quality and variety 许多机器学习技术已经被用于/适用于记录链接
– Actual truth often not known (for example it is impossible to call all individuals that correspond to true matches) 实际真相往往不为人知(例如,不可能调用所有符合真实匹配的个人)
– Easy to get clear true matches and non-matches 易于区分真实匹配和非匹配
– Difficult to get borderline cases (such as same or similar name and different address) 难以区分的情况(例如相同或相似的姓名和不同的地址)
● Another challenge is the class imbalance (many more non-matching record pairs compared to matching ones) 另一个挑战是类别不平衡(与匹配的记录对相比,不匹配的记录对更多)
● Example: Decision trees learned using a small training data set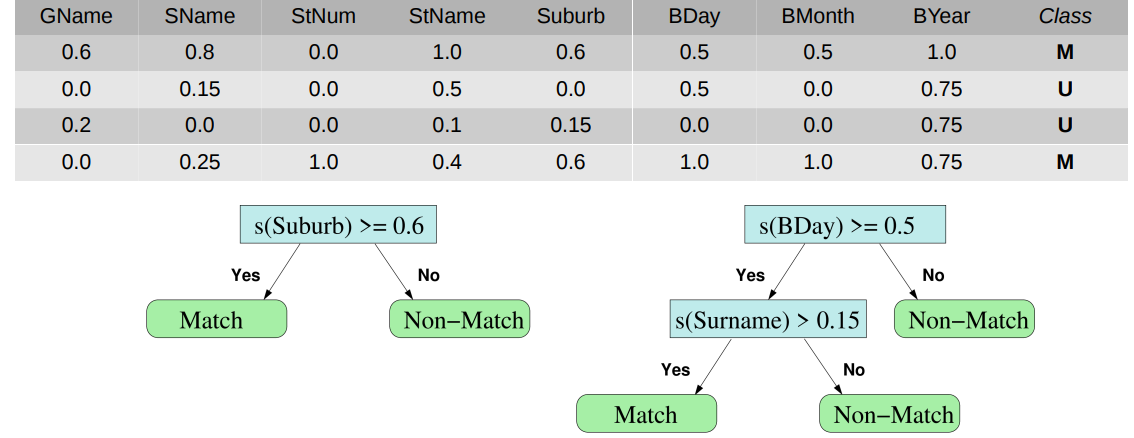
● When record pairs are classified individually, the result might be inconsistent with regard to transitivity 当记录对被单独分类时,结果可能在传递性方面不一致
● If record a1 is classified as a match with record a2, and a2 is classified as a match with record a3, then a1 and a3 must also be a match 如果记录a1被归类为与记录a2匹配,而a2被归类为与记录a3匹配,那么a1和a3也必须匹配
● Special post-processing and clustering techniques need to be applied 需要应用特殊的后处理和聚类技术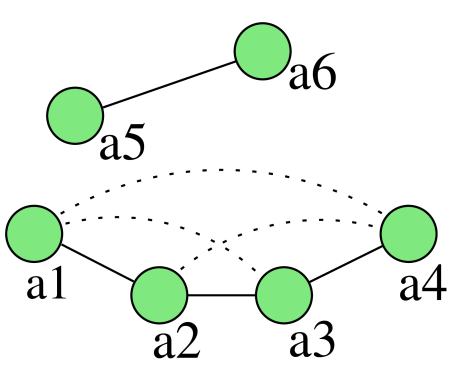

若有收获,就点个赞吧
0 人点赞
