● Given a set of two or more records that have been classified to refer to the same entity, create a single record (representation) by resolving conflicting data values 给定一组两个或多个记录,它们被分类为引用同一个实体,通过解决冲突的数据值来创建单个记录(表示)
● Various difficulties, including 困难
– Missing values in some source attributes 属性中的缺失值
– Contradicting attribute values 冲突的属性值
– Uncertainty in the actual source values 不确定的值
– Use of metadata (such as confidence in data sources, recency of data, and accuracy of data) 元数据的使用(如对数据源的信心、数据的新近性和数据的准确性)
– Implementation of fusion into database and data warehouse systems 数据库和数据仓库系统融合的实现
Three main tasks of data integration
● Schema mapping and matching
– Identify which attributes or attribute sets across database tables contain the same type of information 确定跨数据库表的哪些属性或属性集包含相同类型的信息
● Record linkage / data matching / entity resolution 记录链接/数据匹配/实体解析
– Identify which records in one or more databases correspond to the same real-world entity (person, business, product, etc.) 确定一个或多个数据库中的哪些记录对应于同一个真实世界的实体(个人、企业、产品等)。)
– A special case is deduplication (or duplicate detection) in a single database 一个特殊情况是在单个数据库中进行重复数据消除(或重复检测)
● Data fusion
– Merge pairs or groups of records that correspond to the same entity into one clean, up-to-date, and consistent record that represents the entity 将对应于同一实体的记录对或组合并成一个代表该实体的干净、最新和一致的记录
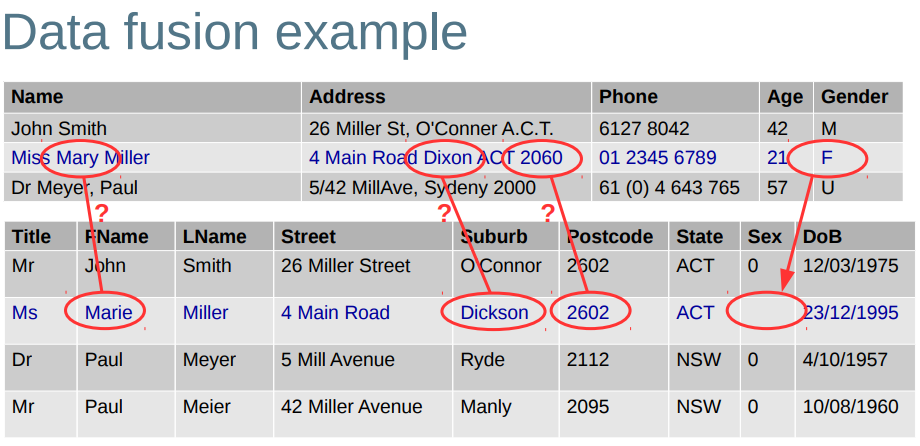
Data fusion goals
The field of data fusion
Conflict types: Uncertainty versus contradiction 冲突类型:不确定性与矛盾
● Uncertainty: Missing values versus non-missing value 不确定性:缺失值与非缺失值
● Contradiction: Two different non-missing values 矛盾:两个不同的非缺失值
● Semantics of ‘missing’ “缺失”的语义
1) unknown – There is a value, but we don’t know it (for example, an unknown date of birth) 未知–有一个值,但我们不知道(例如,未知的出生日期)
2) not applicable – There is no meaningful value (for example, spouse for singles, occupation for children) 不适用–没有有意义的价值(例如,单身者的配偶,儿童的职业)
3) withheld – There is a value, but we are not authorised to see it (for example a private telephone number or bank account number)扣留-有一个值,但我们无权查看它(例如私人电话号码或银行账号)
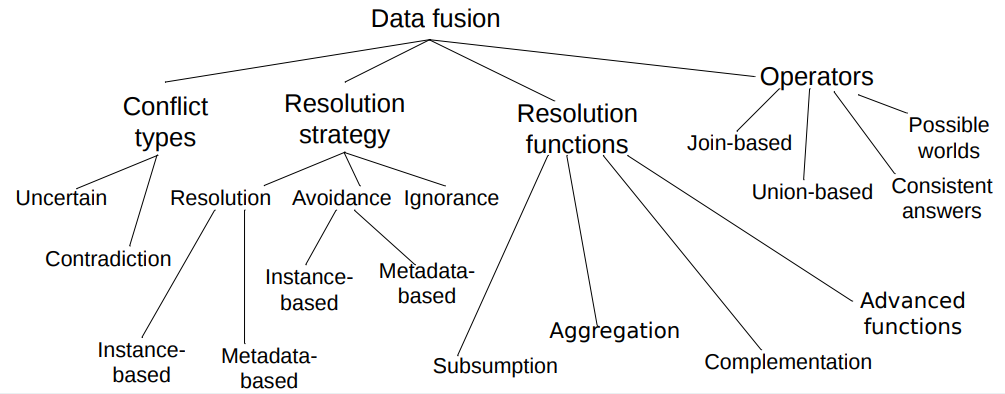
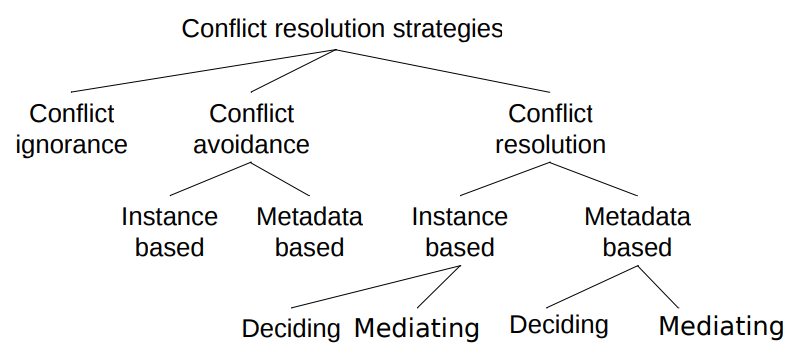
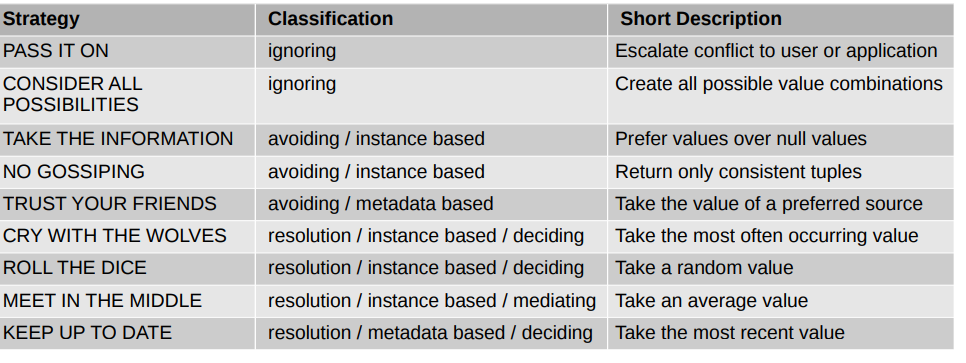
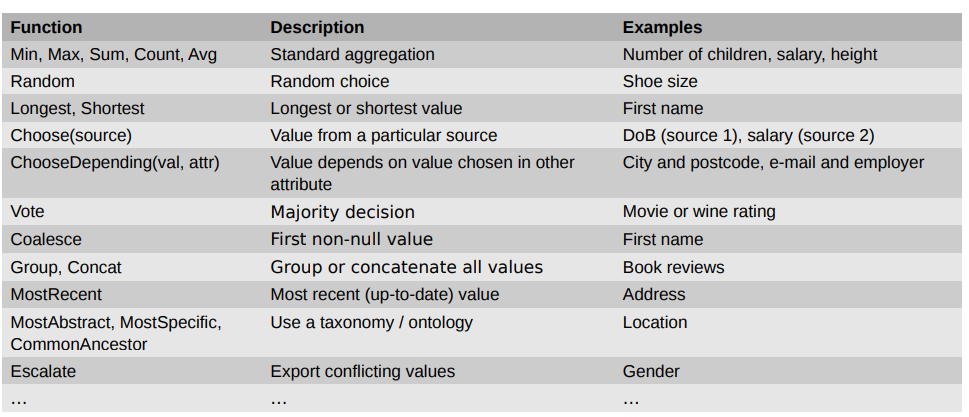
Classification of conflict resolution strategies
Conflict resolution functions
Operators
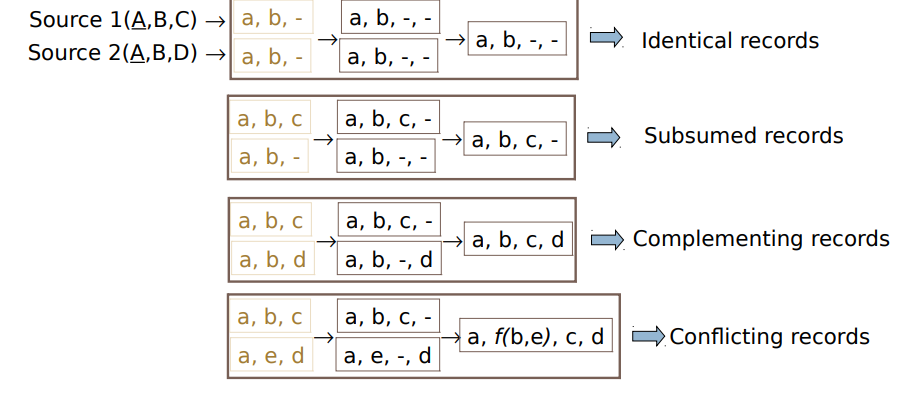
● Identical records: UNION and OUTER UNION 相同的记录:联合和外部联合
● Subsumed records (uncertainty): MINIMUM UNION 包含的记录(不确定性):最小联合
● Complementing records (uncertainty): COMPLEMENT UNION and MERGE 补充记录(不确定性):补充联合和合并
● Conflicting records (contradiction) 冲突记录(矛盾)
– Relational approaches: Match, Group, Fuse, … 关系方法:匹配、分组、融合……
● Other approaches
– Possible worlds, probabilistic answers, consistent answers可能的世界、概率答案、一致答案
Minimum union 最小联合
● Union: Elimination of exact duplicates 联合:消除完全重复
● Minimum Union: Elimination of subsumed records 估计h包含记录
● A record r1 subsumes a record r2 if it has the same schema, has less missing values, and coincides in all non-missing values 如果记录r1具有相同的模式,具有较少的缺失值,并且与所有非缺失值一致,则记录R1包含记录r2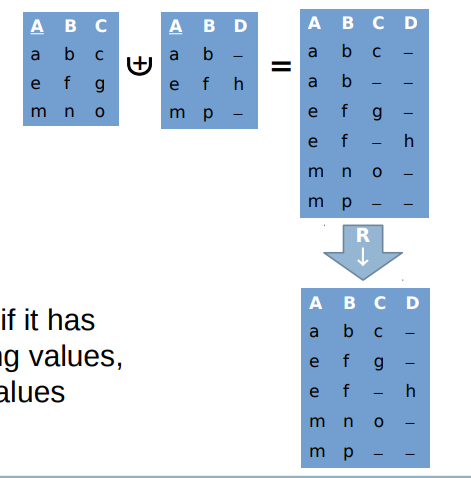
Complement union 补充记录
● Elimination of complementing records
– Outer union 外连接
– Complementation
● Includes duplicate removal and subsumption 包含重复移除和包含
● A record r1 complements a record r2 if it has the same schema and coincides in all non-missing values 如果记录r1与记录r2具有相同的模式,并且在所有非缺失值上一致,则记录R1与记录R2互补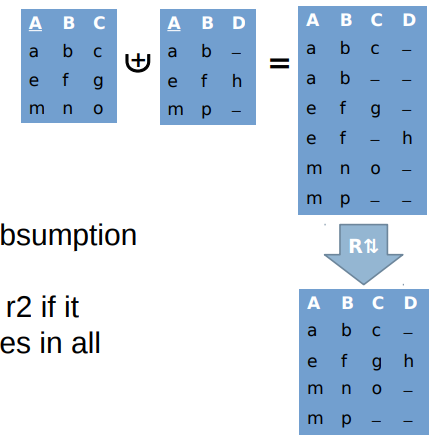
Full disjunction 完全析取
● Represents all possible combinations of source records 表示源记录的所有可能组合
– Full outer join on all common attributes 所有公共属性的完全外部连接
– Minimum union over results 结果的最小联合
– Combines complementing records (only inter-source) 组合补充记录(仅源间)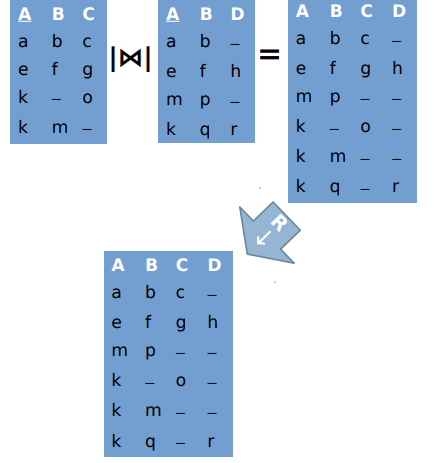
Other approaches for operators
● Consistent Query Answering 一致的查询回答
– Avoid conflicts and report only certain records (those that do not have conflicts) 避免冲突,只报告某些记录(没有冲突的记录)
● “Possible worlds” models
– Build all possible solutions, annotated with likelihood (Yes/No/Maybe, or a probability value) 构建所有可能的解决方案,并标注可能性(是/否/可能,或概率值)
● Probabilistic databases 概率数据库
– Extend relational algebra to produce probabilities 扩展关系代数以产生概率
– Extend query language to query and export probabilities 扩展查询语言以查询和导出概率
Some practical aspects
● Different data sources are likely of different data quality, and so we should trust records from accurate sources more 不同的数据源可能具有不同的数据质量,因此我们应该更加信任来自准确来源的记录
● Real world data are dynamic, and true values can change over time 真实世界是动态的,真实值可能随时间变化
– Therefore more recent data might be more accurate and useful 越新的数据越准确,有效
● Values might be copied from one data source to another 值可能从一个数据源拷贝到另外一个
– Including errors!
● Therefore, in practice, we need to consider:
(1) Accuracy of data sources 数据来源的准确性
(2) Freshness (timeliness) of data sources 时效性
(3) Dependencies between data sources 依赖关系
Open problems in data fusion
● The accuracy of fusion 融合的准确性
– At the attribute and record level (requires truth data for evaluation) 在属性和记录级别(需要真实数据进行评估)
● The efficiency of fusion 融合的效率
– For example incremental fusion as new data arrives (real-time fusion) 例如,新数据到达时的增量融合(实时融合)
● The usability of fusion 融合的可用性
– Adaptive to the needs of a user and/or application 适应用户和/或应用的需求
– Legal requirement with regard to data provenance and data lineage 关于数据来源和数据谱系的法律要求
● Interaction between data fusion and other data integration tasks 数据融合和其他数据集成任务之间的交互
– Such as the Swoosh entity resolution system as developed by Stanford University例如斯坦福大学开发的Swoosh实体解析系统

若有收获,就点个赞吧
0 人点赞
