Privacy, confidentiality, and security
● Three important and related concepts of data protection
● Privacy 隐私
– Right of individual entities (e.g. customers or patients) to make decisions about how their personal data are shared and used 个人实体(如客户或患者)有权决定如何共享和使用其个人数据
● Confidentiality 保密性
– Obligation or responsibility of professionals and organisations who have access to data to hold in confidence 有权保密数据的专业人员和组织的义务或责任
● Security 安全性
– Means or tools used to protect the privacy of entities’ data and to support professionals / organisations in holding data in confidence用于保护实体数据隐私和支持专业人员/组织保密数据的手段或工具
Privacy by design
● Personal data are valuable for various applications, but are at risk of being used, stored, shared, exchanged, or revealed due to growing privacy concerns 个人数据对各种应用都很有价值,但由于日益增长的隐私问题,个人数据有被使用、存储、共享、交换或泄露的风险
– Important to have proper systems in place that provide data protection 重要的是要有适当的系统来提供数据保护
– But allow applications and research studies utilise available information in data 但允许应用和研究利用数据中的可用信息
● Standards and regulations are required 需要有标准和法规
– Safe environments to handle them in 处理他们的安全环境
– Proper handling procedures and output 正确的处理程序和输出
– Safe storage 安全储存
– Privacy laws, such as recent European Union GDPR (General Data Protection Regulation)隐私法
Privacy in data wrangling 数据清洗中的隐私
● Preserve privacy and confidentiality of entities represented by data during the data wrangling pipeline 在数据清洗过程中,保护数据所代表的实体的隐私和机密性
● Privacy and confidentiality concerns arise when data are shared or exchanged between different organisations 当数据在不同组织间共享或交换时,隐私和保密问题就会出现
– Mainly the task of data integration / record linkage in the pipeline that requires data to be integrated from multiple sources held by different organisations主要是管道中的数据集成/记录链接任务,需要从不同组织持有的多个来源集成数据
– Require disclosure limitation to protect the privacy and confidentiality of sensitive data (such as personal names, addresses, etc.)要求披露限制,以保护敏感数据(如个人姓名、地址等)的隐私和机密性。)
Disclosure limitations 披露限制
● Filter or mask (encode or encrypt) raw data to block what is revealed or disclosed 过滤或屏蔽(编码或加密)原始数据,以阻止披露或披露的内容
● Disclosure-limited masking: 披露受限屏蔽:
– Using masking (encoding) functions to transform data such that there exists a specific functional relationship between the masked and the original data 使用屏蔽(编码)功能来转换数据,以便在屏蔽数据和原始数据之间存在特定的功能关系
– Budget-constrained problem 预算受限问题
– the goal of masking functions is to achieve the maximum utility under a fixed privacy budget 屏蔽功能的目标是在固定的隐私预算下实现最大效用
– Examples include noise addition, generalisation, and probabilistic filters 示例包括添加噪声法、一般化和概率滤波器
Privacy-preserving record linkage (PPRL) 隐私保护记录链接(PPRL)
● Objective of PPRL is to perform linkage across organisations using masked (encoded) records PPRL的目标是使用屏蔽(编码)记录在组织间建立联系
– Besides certain attributes of the matched records no information about the sensitive original data can be learned by any party involved in the linkage, or any external party 除了匹配记录的某些属性之外,任何参与关联的一方或任何外部一方都无法获知有关敏感原始数据的信息
PPRL: Example applications
● Health outbreak systems 卫生爆发系统
– Early detection of infectious diseases before they spread widely 在传染病广泛传播之前及早发现
– Requires data to be integrated across human health data, travel data, consumed drug data, and even animal health data 需要将数据整合到人类健康数据、旅行数据、消费药物数据甚至动物健康数据中
● National security applications 国家安全应用
– Integrate data from law enforcement agencies, Internet service providers, and financial institutions to identify crime and fraud, or terrorism suspects 整合来自执法机构、互联网服务提供商和金融机构的数据,以识别犯罪和欺诈或恐怖主义嫌疑人
● Business applications 商业应用
– Compile mailing lists or integrate customer data from different sources for marketing activities and/or recommendation systems 为营销活动和/或推荐系统编制邮件列表或整合来自不同来源的客户数据
● Neither of the parties is willing or allowed by law to exchange or provide their data between/to other parties 任何一方都不愿意或不允许在其他方之间交换或向其他组织提供其数据
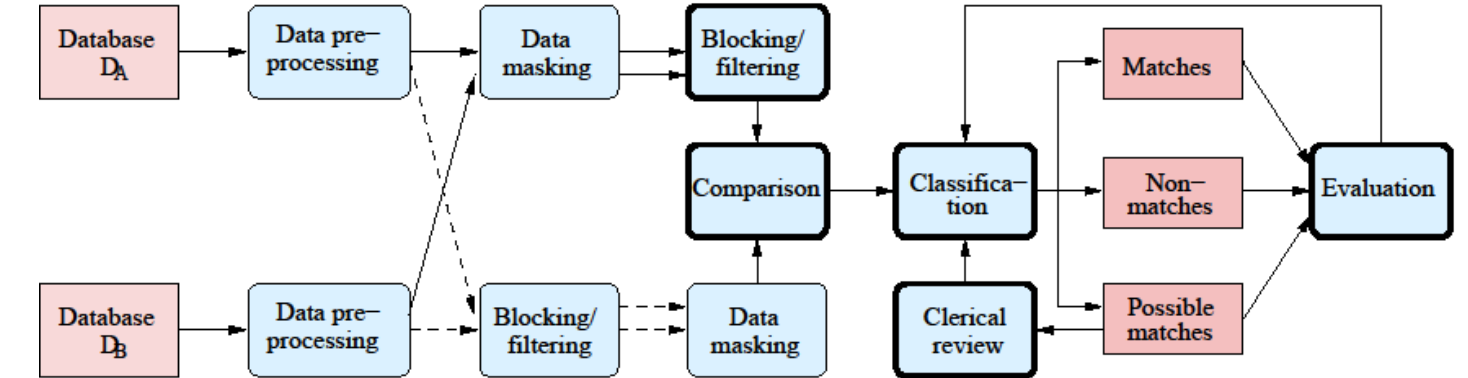
PPRL taxonomy PPRL分类学
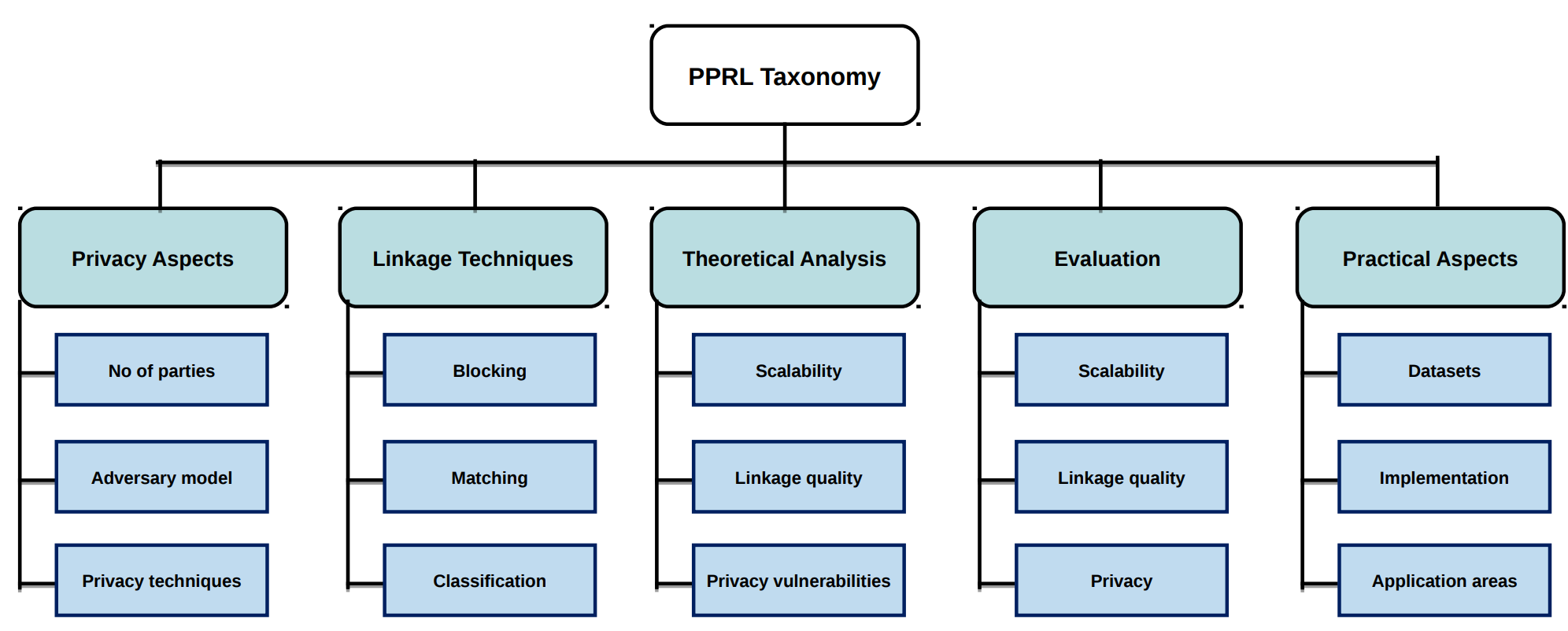
PPRL protocols PPRL议定书

• Three-party protocols: Use a linkage unit (LU) to conduct/facilitate linkage 三方协议:使用链接单元进行/促进链接
• Two-party protocols: Only two database owners participate in the linkage 双方协议:只有两个数据库所有者参与链接
• Multi-party protocols: Linking records from multiple databases (with or without a LU) with the additional challenges of scalability and privacy risk (collusion between parties) 多方协议:将来自多个数据库(有或没有逻辑单元)的记录与可扩展性和隐私风险(各方之间的共谋)的额外挑战联系起来
PPRL adversary modelsPPRL对手模型
● Honest-but-curious (HBC) or semi-honest model – Parties follow the protocol while being curious to learn about another party’s data 诚实但好奇(HBC)或半诚实模式——缔约方遵循协议,同时好奇了解另一缔约方的数据
– Most existing PPRL protocols assume HBC model 大多数现有的PPRL协议都采用HBC模式
● Malicious model 恶意模型
– Parties may behave arbitrarily, not following the protocol 各方可能任意行事,不遵守协议
– Evaluating privacy under malicious model is difficult 在恶意模式下评估隐私很困难
● Advanced models 高级模型
– Accountable computing and covert model allow to identify if a party has not followed the protocol with a certain probability 负责任的计算和隐蔽模型允许确定一方是否以一定的概率没有遵守协议
– Lower complexity than malicious and more secure than HBC 比恶意软件更低的复杂性,比HBC更安全
Attack models 攻击模型
● Dictionary attack 字典攻击
– Mask a list of known values using existing masking functions until a matching masked value is identified (SHA or MD5) 使用现有屏蔽函数屏蔽已知值列表,直到识别出匹配的屏蔽值(SHA或MD5)
– Keyed masking approach, like HMAC, can overcome this attack 键控掩蔽方法,如HMAC,可以克服这种攻击
● Frequency attack 频率攻击
– Frequency distribution of masked values is matched with the distribution of known values 屏蔽值的频率分布与已知值的分布相匹配
● Cryptanalysis attack 密码分析攻击
– A special type of frequency attack applicable to Bloom filters 适用于bloom filters的特殊类型的频率攻击
● Collusion 串通
– A set of parties (in three-party and multi-party protocols) collude with the aim to learn about another party’s data 一组当事人(在三方和多方协议中)相互勾结,目的是了解另一方的数据
PPRL techniques PPRL技术
● Several techniques developed
– Generalisation such as k-anonymity, noise addition and differential privacy; secure multi-party computation (SMC) such as homomorphic encryptions and secure summation; and probabilistic filters such as Bloom filters and variations
一般化,例如k-匿名、噪声添加和差别隐私;
安全多方计算,如同态加密和安全求和;
以及诸如bloom过滤器和变体的概率过滤器
● First generation (mid 1990s): Exact matching only 第一代(90年代中期):仅精确匹配
● Second generation (early 2000s): Approximate matching but not scalable 第二代(2000年代初):近似匹配,但不可扩展
● Third generation (mid 2000s): Take scalability into account 第三代(2000年代中期):考虑可扩展性
Secure hash encoding 安全哈希编码
● First generation PPRL techniques 第一代PPRL技术
● Use a one-way hash-encoding function (like SHA) to encode values and then compare the hash-encoded values to identify matching records 使用单向哈希编码函数,并通过对比哈希值来识别匹配记录
– Only exact matching is possible 可能只有精确匹配
– Single character difference in two values results in a pair of completely different hash-encoded values (for example, “peter” → “1010…0101”, and “pete” → “0111…1010”) 两个值中的单个字符差异导致一对完全不同的哈希编码值(例如,“Peter”→“1010…0101”和“Pete”→“0111…1010”)
● Having only access to hash-codes will make it nearly impossible to learn the original values 只能访问散列码将使学习原始值几乎不可能
– Frequency attacks are still possible 频率攻击仍然是可能的
Noise and differential privacy 噪音和差别隐私
● Add noise to overcome frequency attack at the cost of loss in linkage quality 添加噪声以克服频率攻击,代价是链接质量下降
● Differential privacy is an alternative to random noise addition 差分隐私是随机噪声添加的替代方案
– The probability of holding any property on the perturbed database is approximately the same whether or not an individual value is present in the database 无论数据库中是否存在单个值,在受干扰的数据库中保存任何属性的概率都大致相同
– Magnitude of noise depends on privacy budget and sensitivity of data 噪音大小取决于隐私预算和数据敏感度
Generalisation techniques 概括技术
● Generalises the records to overcome frequency attacks 概括记录以克服频率攻击
● Example: k-anonymity 示例:k-匿名
– Ensure every combination of attribute values is shared by at least k records 确保属性值的每个组合至少由k条记录共享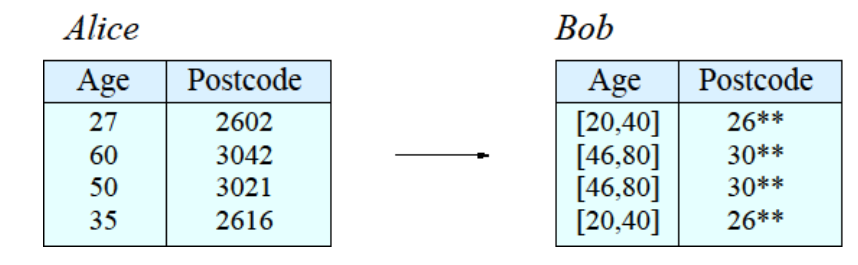
● Other techniques
– value generalisation hierarchies and binning (as covered earlier in the course) 价值概括层次结构和bing(如本课程前面所述)
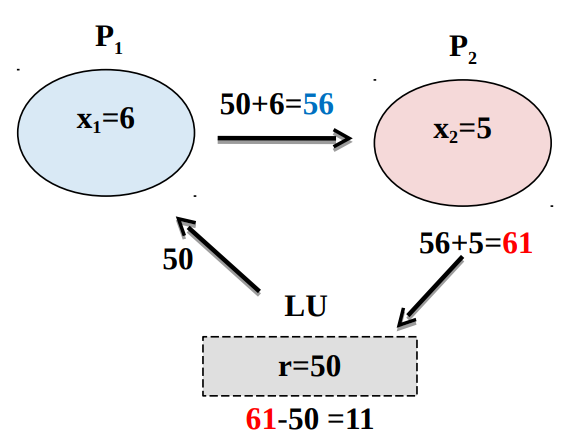
Encryption and SMC 加密和SMC
● Commutative and homomorphic encryptions are used 加密和SMC
● Computationally expensive 计算成本高
● Secure scalar product, secure set intersection, secure set union, and secure summation are the most commonly used SMC techniques 安全标量积、安全集合交集、安全集合并集和安全求和是最常用的SMC技术
● Example:
Secure summation of values x1 = 6 and x2 = 5 using a LU
Bloom filters
Probabilistic data structure 概率数据模型
– Bit vector of l bits (initially all set to 0) 向量初始化都为0
– k independent hash functions are used to hash-map each element in a set S into a Bloom filter by setting the corresponding bits to 1 k个独立的散列函数用于通过将相应的位设置为1来将集合S中的每个元素散列映射到Bloom过滤器中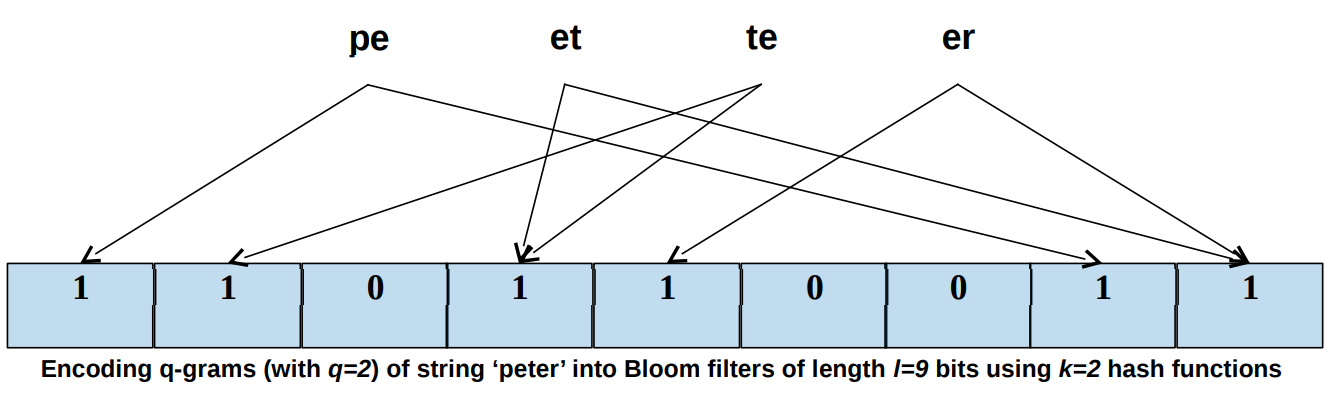
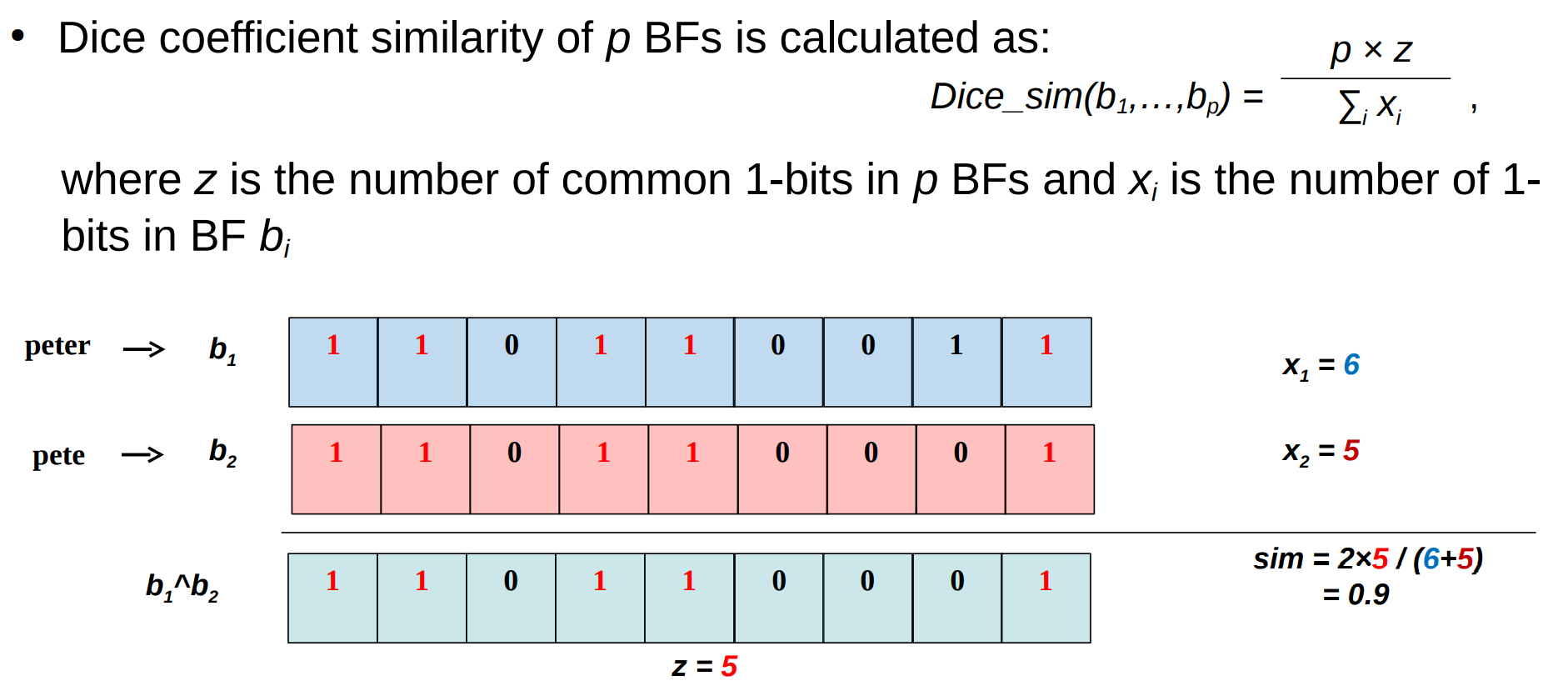
● Bloom filter-based matching 基于bloom的匹配
– Similarity of Bloom filters can be calculated using a token-based similarity function, such as Jaccard, Dice, and Hamming 布隆过滤器的相似性可以使用基于token的相似性函数来计算,例如 Jaccard、Dice和Hamming
– Dice is mostly used, as it is insensitive to many matching zeros dice是最常用的,因为它对许多匹配的零不敏感
– Similarity of Bloom filters ≥ similarity of input values (due to false positive rate of Bloom filters) bloom过滤器的相似性≥输入值的相似性(由于布隆过滤器的假阳性率)
● False positive rate determines privacy and accuracy 假阳性率决定了保密率和准确度
– The larger the false positive rate, the higher the privacy but lower the accuracy 假阳性率越高,保密性越好,但是准确度越低
● Attacks on Bloom filters 对bloom过滤器的攻击
– Susceptible to cryptanalysis attacks 易受密码分析攻击
– mapping bit patterns to q-grams and values based on frequency and co-occurrence information 根据频率和同时出现现信息,将位模式映射到q图和值
– Several attack methods on basic Bloom filters have been developed 已经开发了几种针对基本布隆过滤器的攻击方法
● We have recently developed a new efficient attack method that allows re-identification of frequent attribute values 我们最近开发了一种新的高效攻击方法,允许重新识别频繁出现的属性值
– Patterns in Bloom filter bit positions that have co-occurring patterns are identified using pattern mining 使用模式挖掘识别布隆过滤器位位置中具有共存模式的模式
– The most successful attack method so far 今为止最成功的攻击方法
● Advanced Bloom filter hardening techniques are required 需要先进的布隆过滤器硬化技术


若有收获,就点个赞吧
0 人点赞
