1. 信道编码概念
1.1 基本概念
- 目标是提高通信的可靠性
- 信道编码就是按照规则为信源编码后的码符号序列添加冗余信息,具有一定的数学规律
- 信道编码,纠错编码,抗干扰编码,可靠性编码,就是用于克服噪声和干扰,提高通信系统可靠性的编码
- 信道译码按照相同的数学规律去掉冗余信息
- 冗余符号越多,检错纠错能力越强,但传输效率会下降
通过冗余码元,增加码字距离,在随机噪声信道上,在误码率为小概率事件的前提下提高系统可靠性
1.2 译码规则
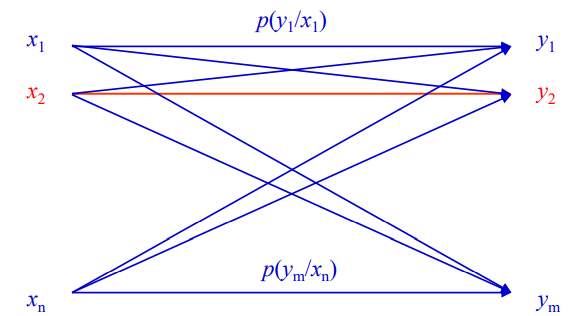
信道模型

译码规则对每一个输出符号
 都有一个确定的函数
都有一个确定的函数 使其对应唯一一个输入符号
使其对应唯一一个输入符号- 函数
 则为译码规则
则为译码规则
-
1.3 译码概率
译码规则

- 如果此时输入符号为
 ,则译码正确
,则译码正确 如果此时输入符号为除
 之外的(r-1)种符号则译码错误
之外的(r-1)种符号则译码错误正确译码的概率
 种译码规则,存在最佳译码规则
种译码规则,存在最佳译码规则

- 错误译码的概率

- 平均错误译码概率

- 平均正确译码概率

1.4 最大后验概率译码规则

- 使
 最小,则
最小,则 最大
最大 - 则在信道的转移矩阵中,每一列寻找最大的
 作为译码规则
作为译码规则

- 信源概率矩阵 乘上 信道转移矩阵 得到 联合概率矩阵
- 去掉 后验概率矩阵 中每一列的最大项对应的 联合概率矩阵 的项后求和
- 存在问题:后验概率往往未知,不知道最大后验概率是哪一项
最大后验概率译码是从后验概率的每一列中寻找最大项
- 由平均错误译码概率的表达式可以看出,错误译码概率与信道输出端随机变量Y的概率分布p(yj)有关,也与译码准则有关。对于给定的信源统计特性p(xi),如果信道转移概率p(yj/xi)确定,信道输出端的p(yj)也就确定了。在这种情况下,平均错误译码概率只与译码准则有关了。
- 通过选择译码准则可以使平均译码概率达到最小值。
- 可以看到:当式中的每一项的后验概率p(x*/yj)为最大值时,平均错误译码概率就可以为最小值
最大后验概率译码准则是一种最小错误译码概率准则,也称为最佳译码准则
1.5 极大似然译码规则
适用范围
- 当输入符号 等概分布 ,极大似然译码等价于最大后验概率译码规则
- 不等概分布时,极大似然译码不一定使PE最小

- 注意此时由 信道转移概率 即可计算错误概率
极大似然译码是从信道转移矩阵中的每一列寻找最大项
最大似然准则不是要求先验等概,而是按先验等概计算误码概率
[x] 例题



1.6 Fano不等式

- 假设知道随机变量Y,我们希望通过Y来猜测另外一个与其相关的随机变量X
- Fano不等式给出了猜测错误(估计误差)的概率与后验熵H(X/Y)之间的关系
- Fano不等式指出:当且仅当后验熵H(X/Y)=0,我们就可以0误差地根据Y估计X
后验熵H(X/Y)越小,估计误差就越小(通信误码率就越小)
对于一个单符号的离散信道(信道的输入输出为一维离散随机变量)
- 信道的输入(随机变量X)为: X: {x1, x2, …… xn}
- 信道的输出(随机变量Y)为: Y: {y1, y2, ……ym}

- 信道的转移概率(X与Y的关联)为:
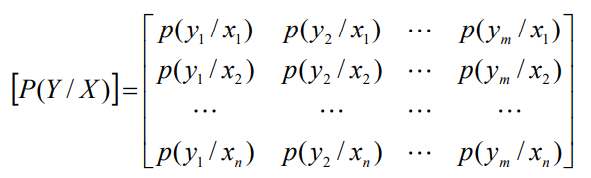
- 译码准则表示为:
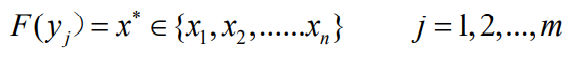
- 例如,收到y2,译码为x*=x2,这时的错误译码概率为:
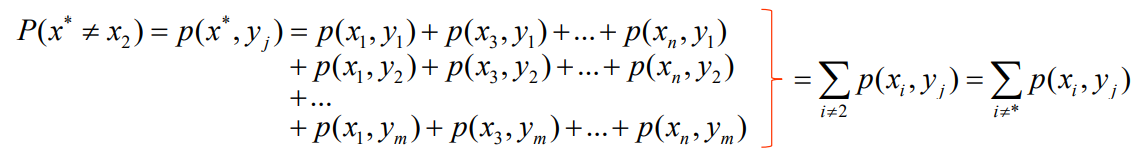
- 如果考虑收到所有的yj,错误译码概率为:
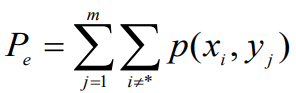
- Fano不等式定理
- 对于一个离散信道,输入随机变量为X,输出随机变量为Y,信道转移概率为P(Y/X),且有
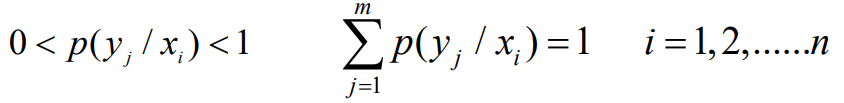
- 如果按照某种译码准则进行译码(估计方法进行估计),即
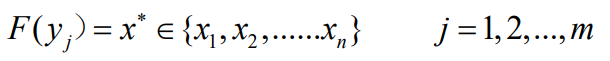
- 则传输错误概率(估计误差)Pe和后验熵H(X/Y)之间的关系为:

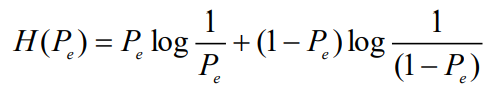
- 物理意义:
- 接收到Y后的X的平均不确定性可以分为两个部分
- 接收到Y后是否会产生错误的不确定性
-
1.7 简单重复编码
输出符号集中符号的个数多于输入符号集符号个数
- 如输入符号信源000,111,输出符号集000,001,010,011,100,101,110,111
- 即增加重复次数,添加冗余码,让多个输出符号对应一个输入符号

- 减小了
 的求和,减小了错误概率
的求和,减小了错误概率 - 但是同样会减小信息传输率

在重复序列中选择不同的排列作为信源符号会得到不同的错误概率,存在一种选取使错误概率最小
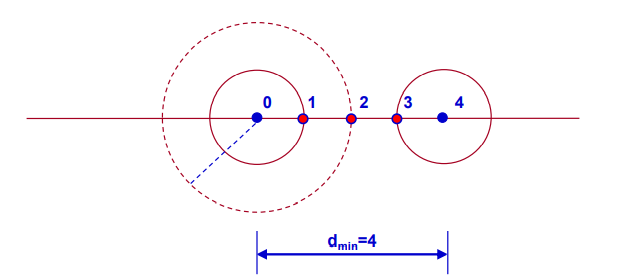
1.8 汉明距离
码字空间
- 码字空间可以理解为一个向量空间,向量空间的元素是向量,码字空间中的元素为码字
- 如果原始信源空间有M个消息符号,对其进行q元编码,码长为N,那么码字空间中码字的个数为
 ,理论上讲,这些码字都是可用的码字,典型的是二元编码
,理论上讲,这些码字都是可用的码字,典型的是二元编码 - 编码器在码字空间中
 个码字中选择M个码字分别代表原始信源中的M个消息符号,这M个码字称为许用码字,而剩下的
个码字中选择M个码字分别代表原始信源中的M个消息符号,这M个码字称为许用码字,而剩下的 个码字称为禁用码字
个码字称为禁用码字 - 为了实现编码,一定有
 。这M个许用码字也称为一个码组,或称为信道编码的码字集合(子空间)
。这M个许用码字也称为一个码组,或称为信道编码的码字集合(子空间) 编码的问题就是在码字空间中找到一个具有某种特性的子空间。
汉明距离
- 两个长度为n的码符号序列
 ,定义汉明距离
,定义汉明距离

按位异或,即求两个码字不同的位数
码的最小距离
- 任意两个码字之间的汉明距离的最小值
码的最小距离越大,平均译码错误的概率越小
汉明重量
在码字集合X中,码字α中非零码元的个数称为这个码字的汉明重量,记为W(α)
码的最小距离与极大似然译码准则
- 设两个码字的汉明距离为

- 对于平稳无记忆信源

 为单比特错误概率,
为单比特错误概率, 为单比特正确概率,
为单比特正确概率, 较小
较小 较大
较大 越大,
越大, 越小,即
越小,即 越大,“越似然”
越大,“越似然”

- 则
 越小
越小 - 极大似然译码准则就等价于,当接受到一个长为n的码符号序列时,在输入码字集中寻找一个码符号序列使两个序列距离最小,即为最小距离译码准则
2. 有噪信道编码定理
2.1 香农第二定理
- 离散无记忆信源,信道容量为C,只要待传送的信息传输率R <C,当码长n足够大时,则至少存在一种编码,使译码错误概率任意小

- 定理只说明了存在性
- 有噪信道编码逆定理:如果R >C,无论码长多长,也不能使译码错误概率任意小
- 信道容量是在信道中可靠传输信息的最大信息传输率
2.2 有噪信道本质
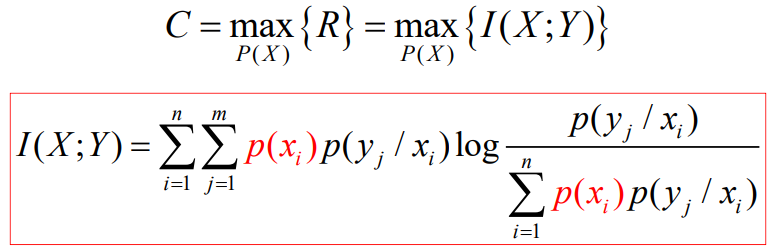
- 信道容量就是给定信道的最大互信息量(等同熵速率),给定一个信道,就有一个信道容量,可大可小
- 第二编码定理并不是提高信道容量,而是尽可能地达到信道容量,但是要保证无差错(或很小的差错)
它是可靠性编码定理,目的是实现无差错的信道容量传输能力。只要找到一个办法,既能无差错,又能是R接近于C,就可以了
[x] 打字机信道举例
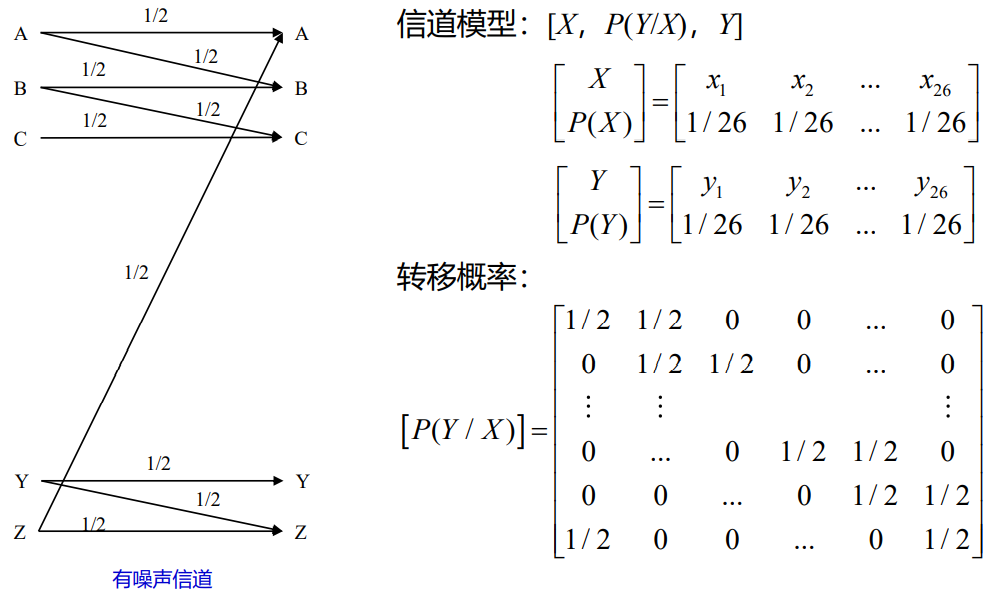

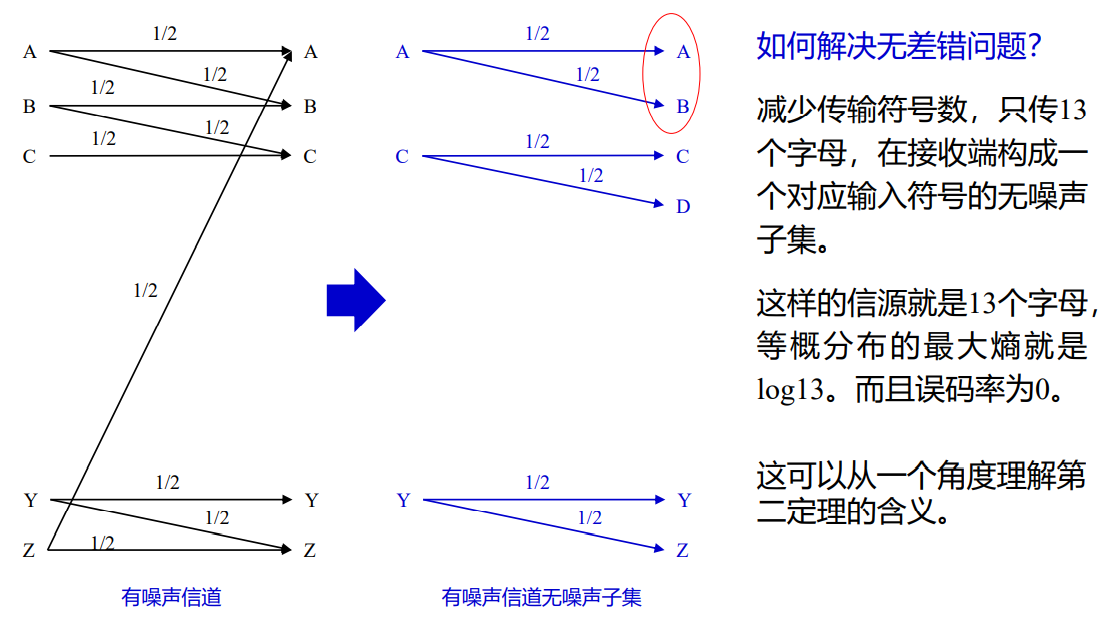
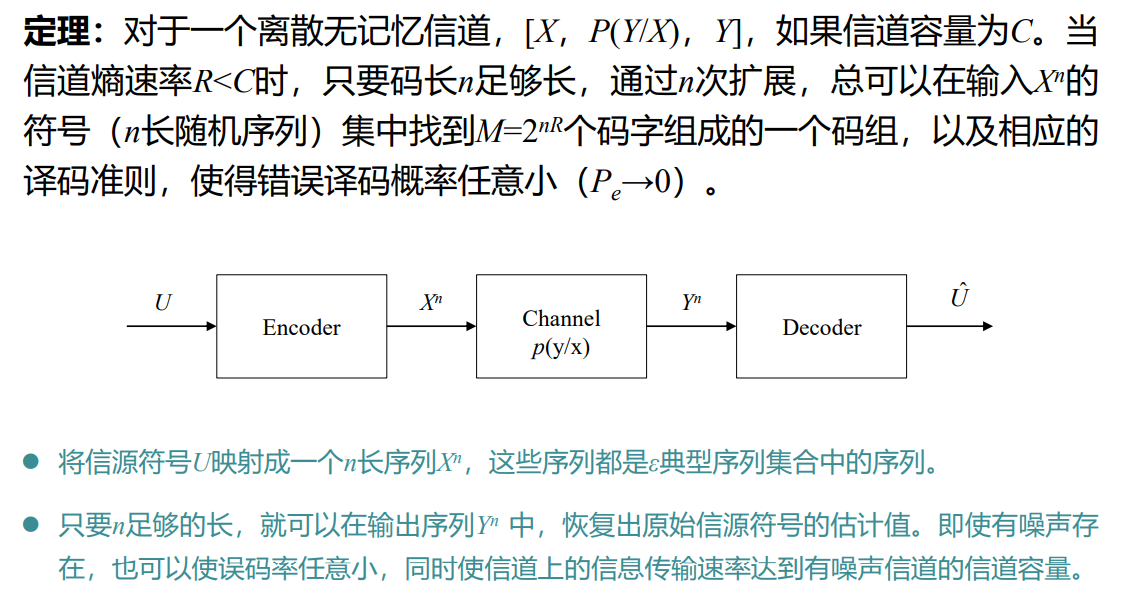
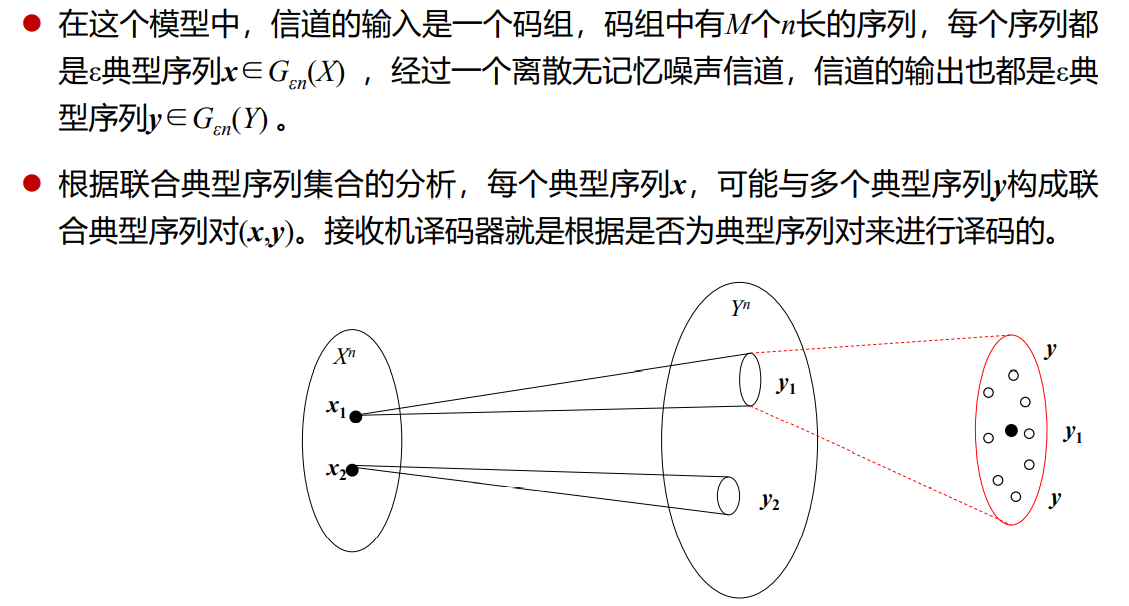
2.3 联合ε典型序列集合





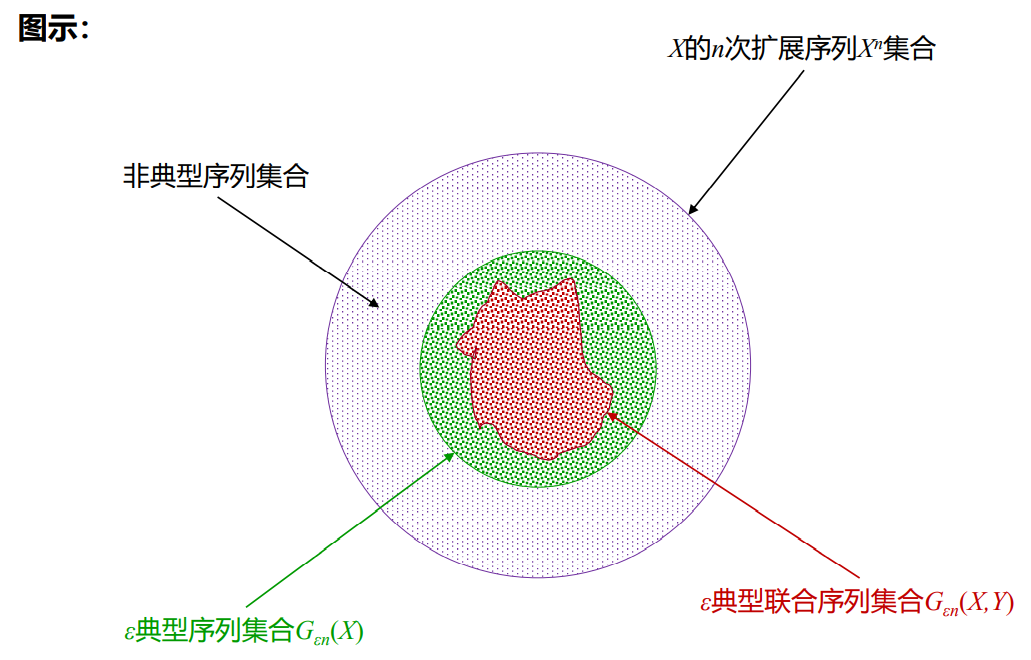
2.4 渐近等分性描述有噪编码

3. 信息传输的差错控制方法
- 在有噪声信道上传输信息不可避免地会产生差错,而通信系统的基本目标是尽量减少或消除信道干扰引起的差错
- 出现了各种基于香农信道编码理论的差错控制方法,进而在通信理论中形成了一个专门研究信道编码的理论分支
从目前来看,传统的信道编码理论的主要基础是香农第二编码定理和代数理论
3.1 差错控制方法的分类
应用角度
- 可以分为检错码和纠错码
- 检错码一般具有较少的监督码元,冗余度较小,只能检出错误,但不能纠正错误,检错码一般需要与自动重复传送(ARQ)系统一起构成差错控制系统
- 纠错码相对具有较多的监督码元,纠错码既可以发现错误也可以同时纠正错误
- 从编码的码字结构及监督元与信息元的数学关系角度讲,信道编码还可以分为线性编码和非线性编码
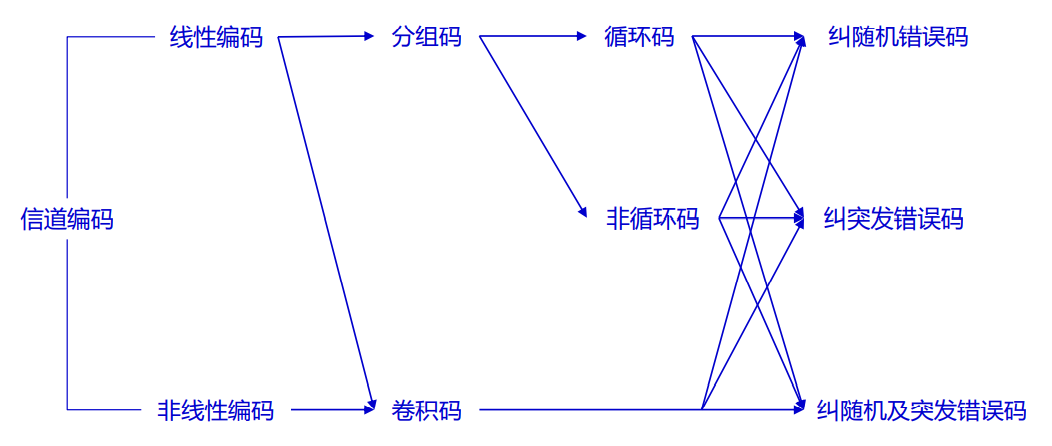
- 码字结构角度
- 可以分为分组码和卷积码
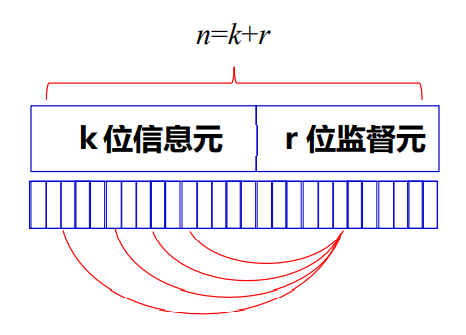
- 分组码
- 码字结构如图所示,其码长为n=k+r,其中k为信息码元个数,r为监督码元个数,每个码字的监督元只与这个码字的信息元有逻辑代数关系,也就是说存在一种码字分组内的相关,译码时可以每个码子单独译码,通常记为(n,k)码
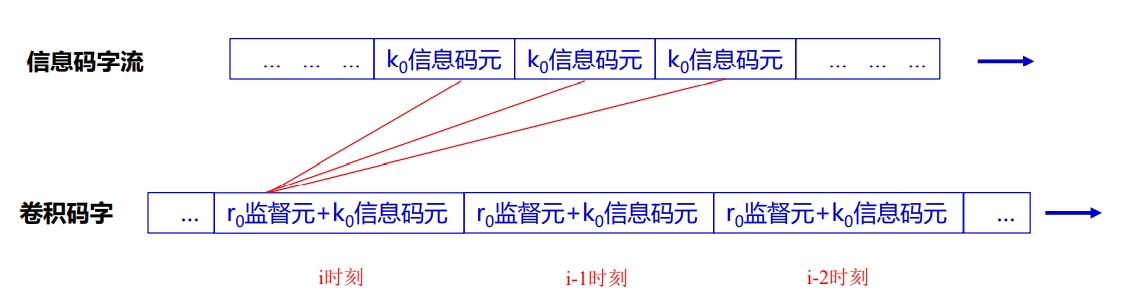
- 卷积码
- n0为码字长度,k0为信息元个数,且n0≥k0
- 卷积码的n0-k0个监督元不仅与本码字的信息元有代数关系,而且还与前m个码字的信息元有关 , m为卷积码编码器的存储器级数,也称为卷积码的约束长度
- 卷积码通常记为(n0,k0,m)码
3.2 自动请求重传ARQ
- 当通信系统对信息传输延时要求不是很高,信道条件比较好时,为了提高系统整体效率,往往使用检错码加上自动重传的方法解决传输差错控制问题。
- 在这样的系统中,发送端将信息通过检错码编码,接收端监测码字错误情况,一旦发现错误就通过反向信道自动通知发送端,请求发送端重发。
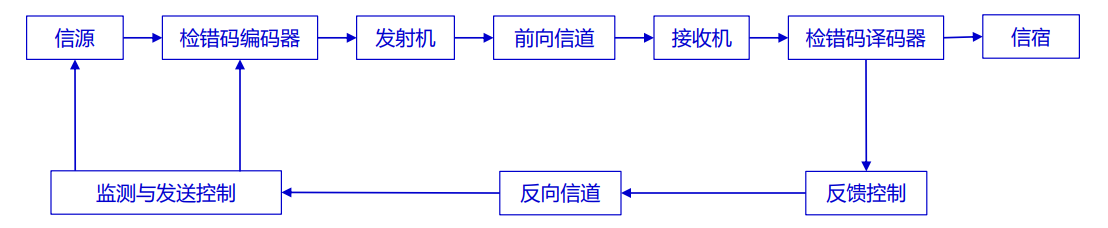
几种典型的ARQ:停止等待式ARQ,退N步式ARQ和选择重传式ARQ
3.3 前向纠错方式FEC
前向纠错(FEC)方式要求接收端不仅能发现码字的错误,而且还要能够按照译码准则估计出正确的码字。
- 前向纠错方式的优点是接收端可以自动发现并纠正错误,不需要反向信道,可实现一点对多点的广播通信,传输实时性好,控制方式比较简单。
- 而其缺点是译码算法比较复杂,如果使用一种固定的编译码算法,则对信道的适应性较差,为了提高可靠性就要牺牲传输效率。

除了ARQ方式和FEC方式之外,还可以将两种方式结合使用,这就是所谓的混合纠错方式(HEC),HEC可以充分利用两种基本方式的优点,提高信道编码的适应性,提高系统效率
3.4 信道编码纠错能力
除了ARQ方式和FEC方式之外,还可以将两种方式结合使用,这就是所谓的混合纠错方式(HEC),HEC可以充分利用两种基本方式的优点,提高信道编码的适应性,提高系统效率

3.5 信道编码编码效率
- 对于信源编码和信道编码,其编码效率是统一的,都是传输有效性的一种体现
- 在一个码字中信息为所占的比例称为编码效率
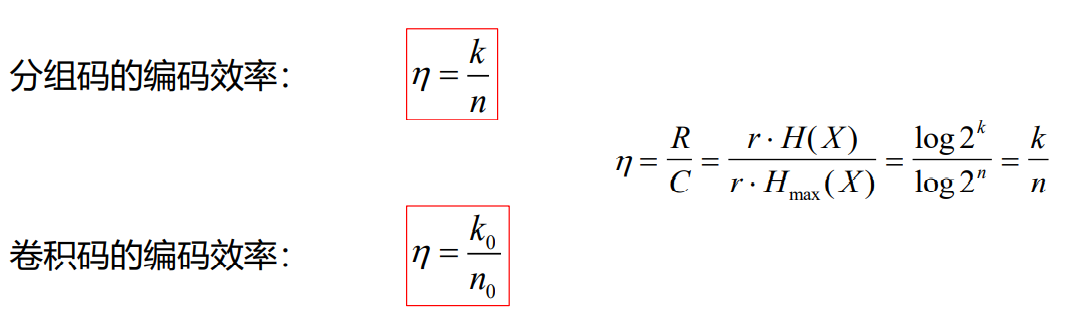
3.6 信道编码编码增益
- 香农第二定理指出,在传信率接近信道容量情况下,以任意小的误码率传输信息是可能的
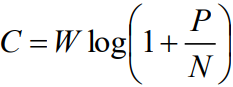
- 其中的噪声功率
 ,
, 为噪声功率密度,信号功率
为噪声功率密度,信号功率 ,Eb为符号码元能量,Tb为码元时间宽度,Tb与码元速率Rb的关系为Rb=1/Tb。因此,可以写成
,Eb为符号码元能量,Tb为码元时间宽度,Tb与码元速率Rb的关系为Rb=1/Tb。因此,可以写成
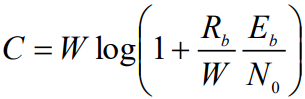
- 其中Rb/W就是频带利用率,在理想接收机条件下,理论上可以认为频带利用率取决于系统使用的调制解调方式。这就是用归一化信噪比Eb/N0(码元信噪比)表示的香农公式
- 针对同一个通信系统,在一定的误码率指标条件下,通过信道编码带来的信噪比需求的减少量称为编码增益,即
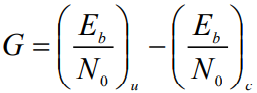
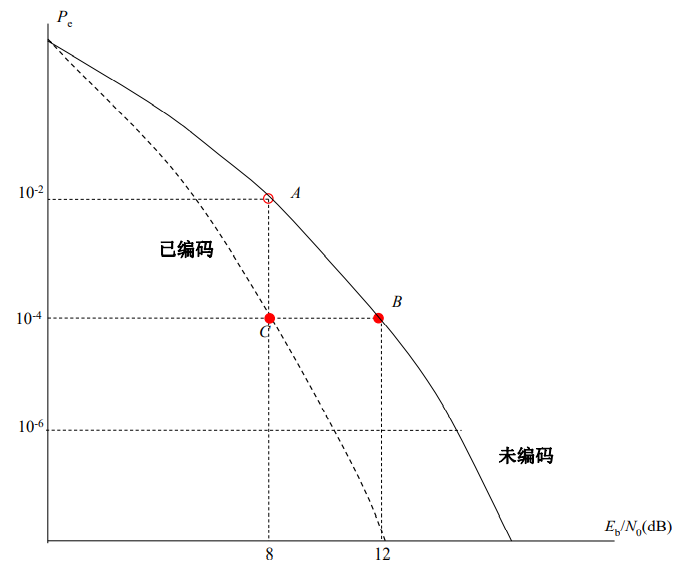
例如:为了获得10-4的误码率指标,未编码时需要信噪比为12dB,而编码后只需要8dB,即表示系统具有4dB的编码增益
3.7 简单检错码
奇偶校验码
- 奇偶校验码也称为一致监督检错码,是一种检错分组码。
- 最小码距为2,码字长度为n=k+1

- 偶校验码
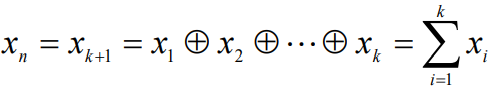
- 奇校验码
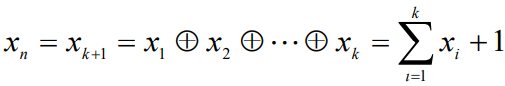
- 编码效率
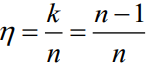
- 定比码
- 定比码也称为等重码或范德伦码,定比码也是一种简单检错码,包括五三定比码和七三定比码,最小码距为2
- 五三定比码也叫五单位码,主要用于国内电报系统,码长为5,其中1的个数为3,这种码的许用码字为10,用于国内电报中的数字0~9
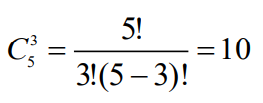
- 七三定比码也叫七单位码,主要用于国际电报系统,码长为7,其中1的个数为3,这种码的许用码字为35,用于英文电报中26个英文字母和一些基本符号
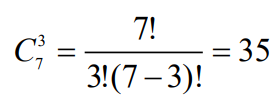
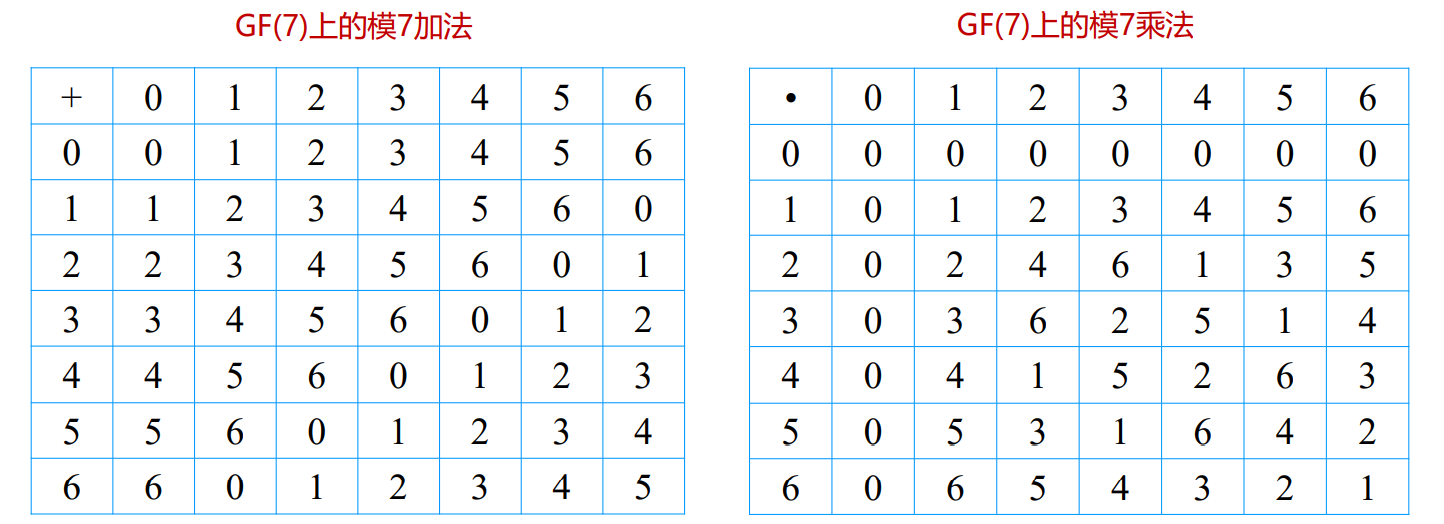
4. 线性分组码构成与原理
- 差错控制编码(ECC)的分类
- 检错码、纠错码
- 分组码、卷积码(连续码)
- 纠独立错误码,纠突发错误码
- 可分离码(信息位与冗余位可以明显分离的),不可分离码(无法分离的)
- 可分离码中还包括:系统码,非系统码
- 差错控制编码的绝对冗余度和相对冗余度
- 对于可分离编码,如果码长为n,信息位为k,冗余位为r
- 绝对冗余度:
- 对于可分离编码,如果码长为n,信息位为k,冗余位为r
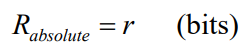
- 相对冗余度:

- 对于二元不可分离编码,如果码长为n,信息码序列个数为M
- 绝对冗余度:
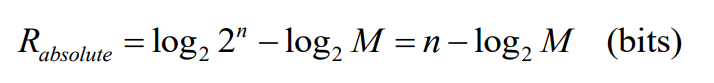
- 相对冗余度:

4.1 最大似然译码(MLD)与最小距离译码
- 接收机的译码过程就是根据接收码字向量r,估计发送码字c的过程,估计错了就是误码发生。所以接收到一个码字r而产生误码的概率为:
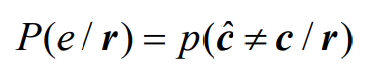
- 总的误码率:
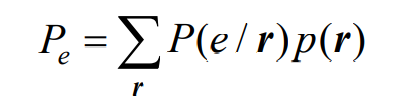
- 对于离散无记忆信道,最大似然估计就是
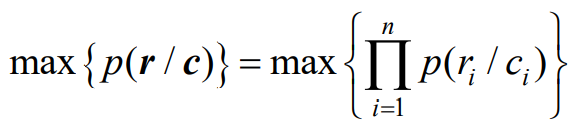
- 等效于
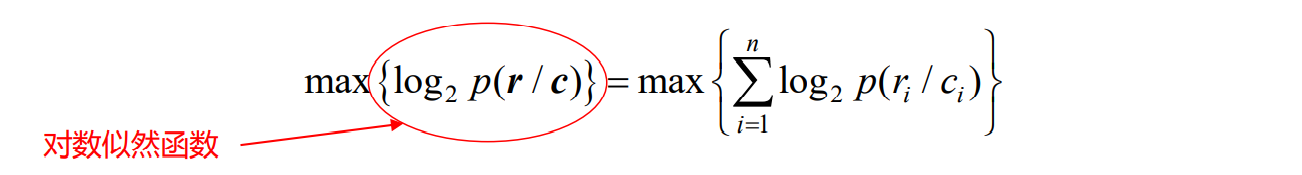
- 对于二元对称信道(BSC),一个n长的码字,似然函数为:
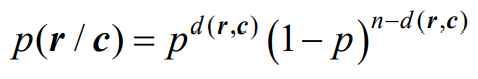
- 对数似然函数为:
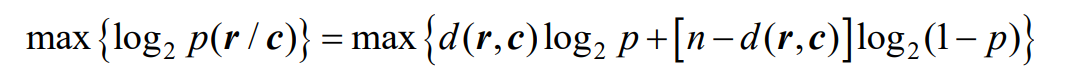
- 即
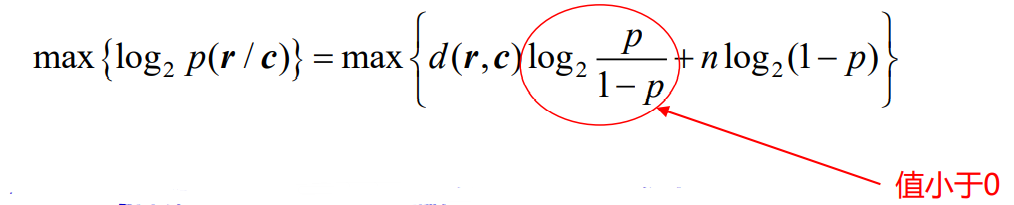
- 对于p<1/2,汉明距离越小,对数似然函数越大
-
4.2 近世代数-域(Field)
如果一个元素集合F,在其中定义加法和乘法两种运算,并满足下列条件则称为一个域(Field)。a,b,c,d,e,a^-1∈F
- 在加法下为一个交换群,满足自闭性,交换律,结合律,单位元,逆元,其中加法单位元称为域的零元,记为0
- 集合中的非零元素在乘法下为一个交换群,满足非零元素自闭性,交换律,结合律,单位元,逆元,其中乘法单位元称为幺元,记为1
- 在加法乘法下满足分配律
简单地讲:域就是一组元素集合,在这个集合中进行加、减、乘、除运算后其结果仍在这个集合中。可以看出,域中至少有两个元素,加法单位元和乘法单位元,{0,1}就是这样一个二元域。
有限域(Galois Field)
- 域中元素的个数m称为域的阶(order),有限个元素的域称为有限域或叫作伽罗华域,
- 记为GF(m),GF-Galois Field
- 域的性质:
- 性质1:对于域中的任何元素a,有a∙0 = 0∙a = 0
- 性质2:对于域中的任何两个非零元素a和b,a∙b ≠ 0
- 性质3:如果a∙b = 0,且a ≠ 0,则b=0
- 性质4:对于域中的任何两个元素a和b,-(a∙b)=(-a) ∙ b=a ∙ (-b)
- 性质5:如果a ≠ 0,且a∙b=a∙c,则b = c
- 很容易验证实数集合在普通加法和乘法下是一个域,这个域有无穷多的元素
集合{0,1}在模二加法和乘法下构成一个二元有限域,一般称为二元域,记为GF(2)
素数域(Prime number Field)
- 如果p为一个素数,则正整数集合{0,1,2,…p-1},在模p加法和模p乘法下构成一个阶数为p的域,称为素域,
- 记为GF(p)。GF(2)为一素域
- 域上的向量空间
- 设F是一个域,V是一个非空的向量集合,在V中定义一种加法运算(+),并存在加法自闭性。同时定义一种F中元素与V中元素的乘法运算(•),这种乘法对V中的元素存在乘法自闭性。如果加法运算和乘法运算满足以下运算规则,就称V是F上的向量空间(vector space)
- 集合V 对于加法是一个交换群
- 若a ∈ F,v ∈V ,则a∙v ∈V仍然成立
- 满足分配率,即若a,b ∈ F,u,v ∈V,则a∙(u+v)=a∙u+a∙v
- 满足结合律,即若a,b ∈ F,v ∈V ,则(a∙b)∙v=a∙(b∙v)
- 存在单位元,即若1为F中的单位元,v ∈ V,则1∙v=v
V中的元素为向量,F中的元素为标量。V中的加法为向量加法,F中的元素乘以V中的元素称为标乘。V中的单位元是一个零向量,记为0
域上的向量空间的性质
- 性质Ⅰ:设0为域F上的零元,对于V上的任一向量v有 0∙v = 0;
- 性质Ⅱ:对于域F上的任一标量c,有c∙0 = 0;
性质Ⅱ:对于域F上的任一标量c,有c∙0 = 0;
如果域F为一个二元有限域GF(2),GF(2)上的向量空间V就是我们在编码理论中最常用的码字向量空间
4.3 线性分组码的构成
- 汉明码是一种最简单、最典型的线性分组码
- 其编译码简单,是早期通信系统很常用的一种编码方法
- 线性分组码是这样一类纠错编码,它把信源输出的码序列分成长度相等的分组,然后再每个分组中加上若干监督码元构成码字
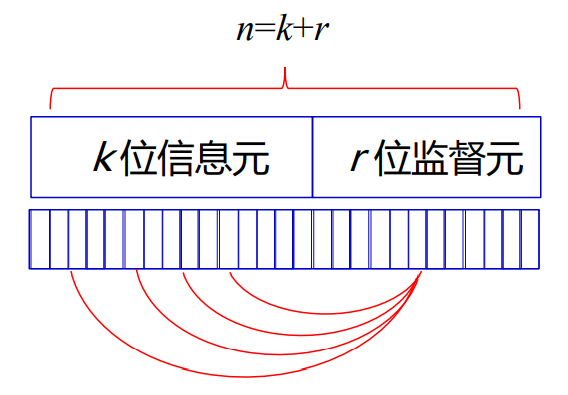
- 每个码字中的监督码元与信息码元存在某种监督关系(约束关系)
- 如果这种监督关系可以用代数关系描述,我们就称其为代数编码
- 如果这种关系是线性关系,我们就称其为线性分组码

- 编码器的输入m为消息分组,它由k位消息码元组成。编码器的输出c称为码字向量,它由n位码元组成
- 长度为n的二元序列(n-重),共有2^n个可能的码字向量
编码器只是在这2^n个可能码字向量中选择2^k个码字向量
一个长度为n,有2^k个码字的分组码C,当且仅当这2^k个码字是GF(2)上n 维向量空间(所有n重)的一个k维子空间时,则码组C 称为(n,k)线性分组码,简称(n,k)码
- (n,k)线性分组码的特性:
- 二元分组码为线性分组码的充要条件为两个码字的模二加仍然是这个码组中的一个码字
- 由于k维子空间是在模2加法运算下构成了一个加法交换群(阿贝尔群),所以线性分组码也称为群码
- 线性分组码的一个重要参数为码率(Code rate)R=k/n,它实际上也就是编码效率
如果(n,k)线性分组码的码字中消息分组与监督码元是明显分开的,我们称为系统码,否则称为非系统码
考虑n=5,GF(2)上的所有5维向量组成的向量空间由32个向量(元素)组成

- 可见:
- 00000为零向量;两个向量的模2加还是空间的一个向量;GF(2)的元素乘以向量还是空间的一个向量
二元域上长度为n的向量空间中有2^n个向量
向量空间的子空间
- 向量空间的维数与向量的维数不是一个概念,向量的维数是向量的分量的个数;
- 向量空间的维数是向量空间的基底的向量个数
- 例如,长度等于5的二元域上的向量空间,维数也等于5。它的基底可能是不唯一的,但其中00001,00010,00100,01000,10000肯定是一个基底,由这个基底可以张成这个向量空间。这个基底称为自然基底
- 若V是F上的向量空间,如果V存在一个子空间S也是F上的向量空间,则称S为V的子空间(subspace)
- 设S为域F上向量空间V的一个非空子集。若满足下列条件,则S就是V的一个子空间
- 若u,v ∈ S,则u+v ∈ S也成立
- 若a ∈ F,u ∈ S,则a∙u ∈ S也成立
- 在上面5维向量空间中,有一个3维子空间:

- 它的基底有三个向量组成,11100,01010,10001就是一个基底
- 这个基底并不唯一
- (n, k)线性分组码的编码问题就是寻找n维向量空间的k维子空间的问题
4.4 从实例分析线性分组编译码
- 一个(7,4)系统线性分组码

- 可知c=[c6,c5,c4,c3,c2,c1,c0], [c6,c5,c4,c3]为信息元,[c2,c1,c0]为监督元
- 监督方程为:
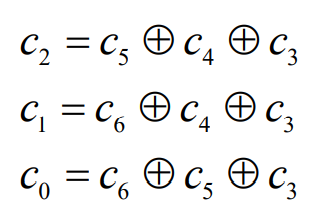
- 如果消息分组为m=[1011],系统汉明码的码字为c=[1011010]
- 通过矩阵计算表示
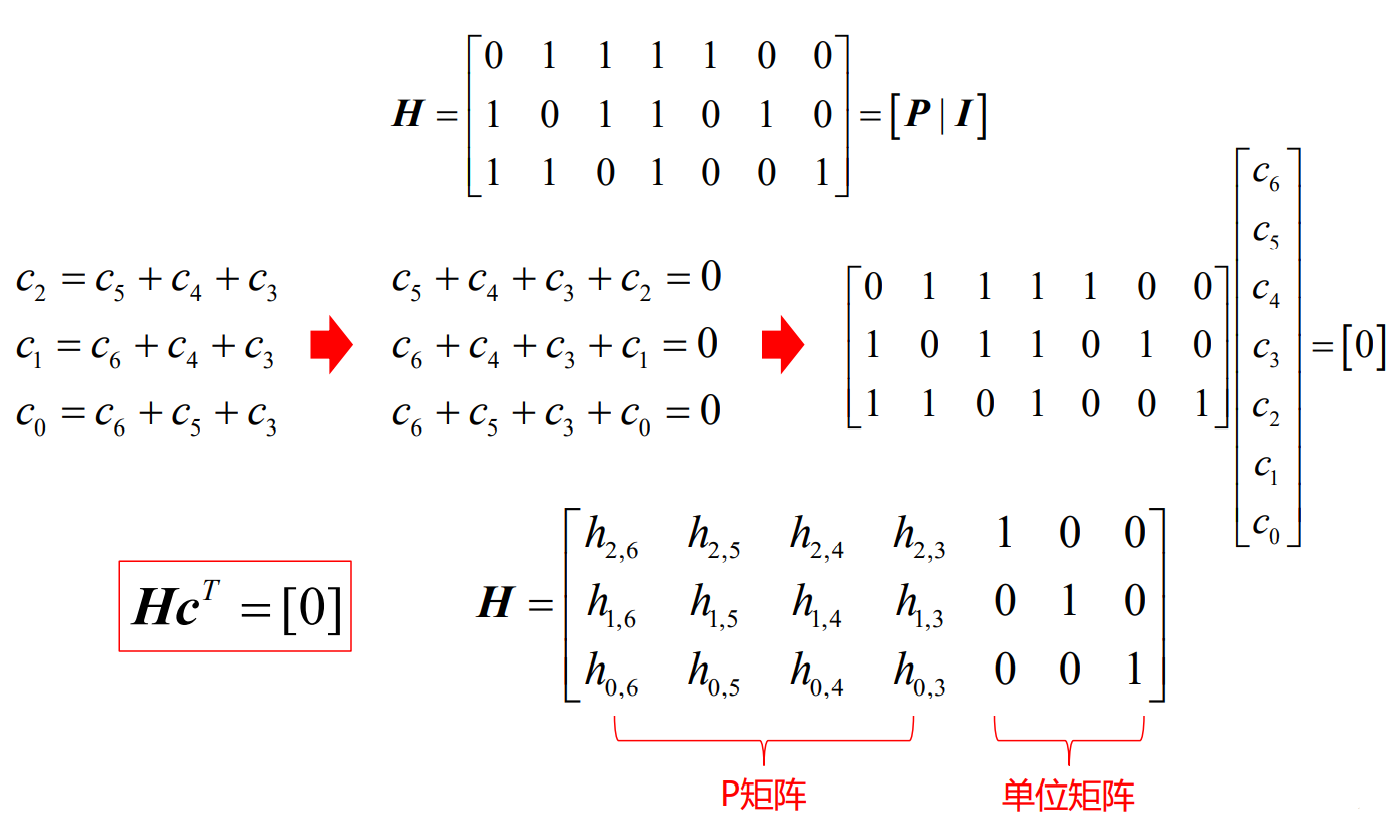
- 由此得到了监督矩阵H
- 即将接收的一个码c与监督矩阵H作用通过计算结果是否为0判断接收是否正确
- 将监督方程扩展写为下面的形式
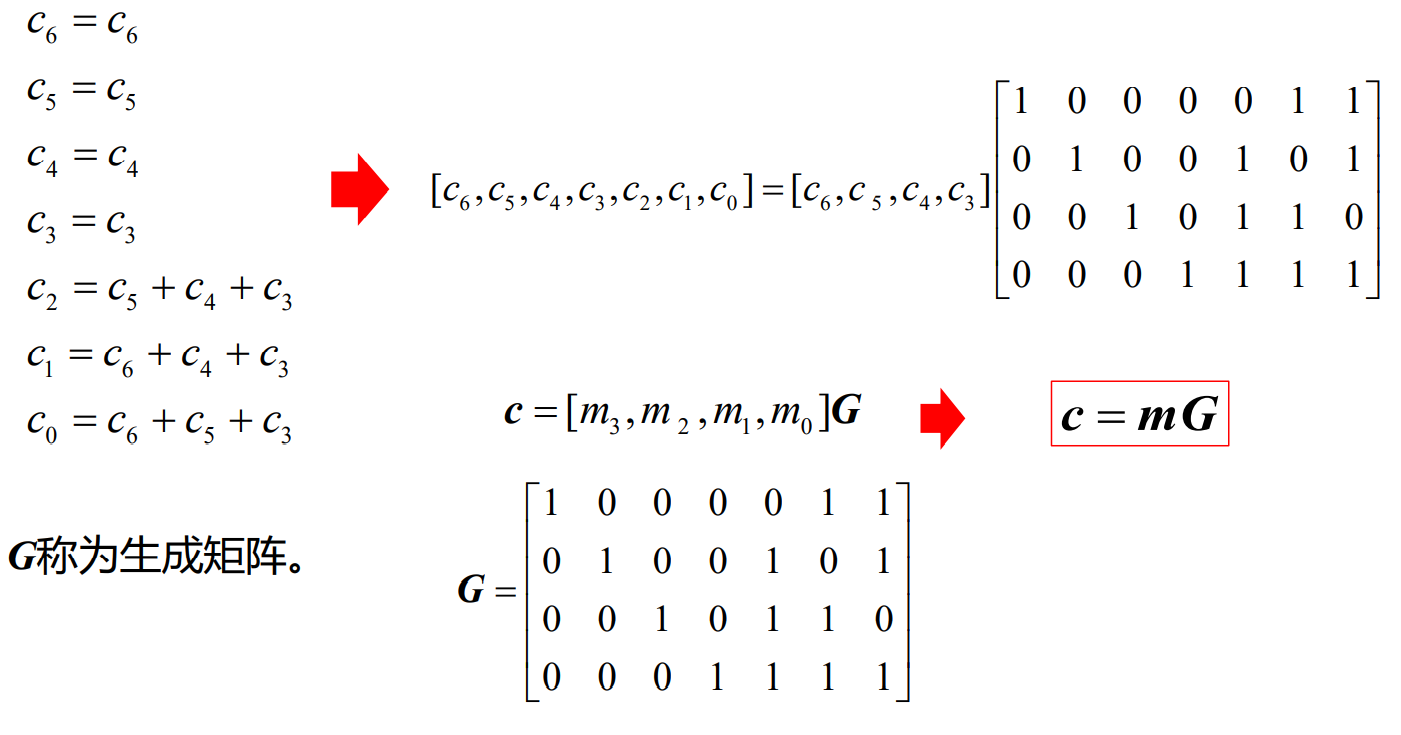
- 得到了生成矩阵G
- 即将四位信息码通过与生成矩阵作用,可以得到七位的完整码
- 相互关系
- 译码过程

- 接收译码器操作为:
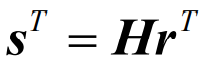
- 使用监督矩阵作用在接收信息序列上
- 在只错1位的情况下,可以看到错误码元与校验子的关系:

- 综上可总结为

4.5 线性分组码的描述
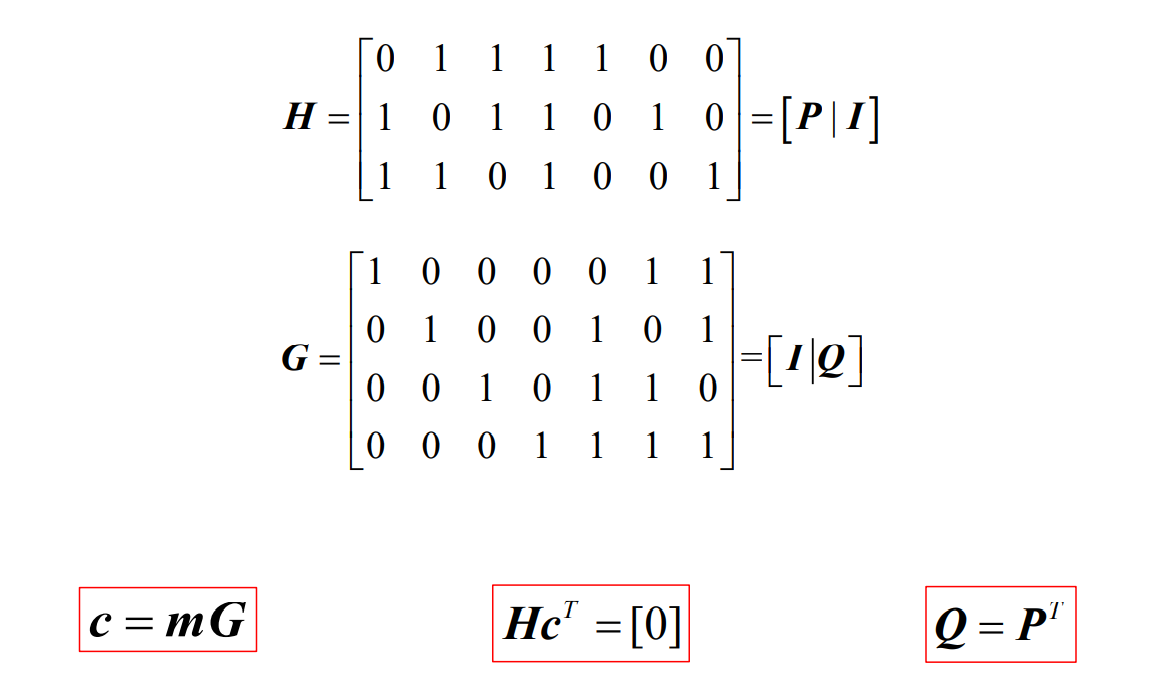
- 系统线性分组码的监督矩阵(H矩阵)
- 线性分组码的监督元与信息码元之间存在某种线性代数关系,可以用监督矩阵来描述
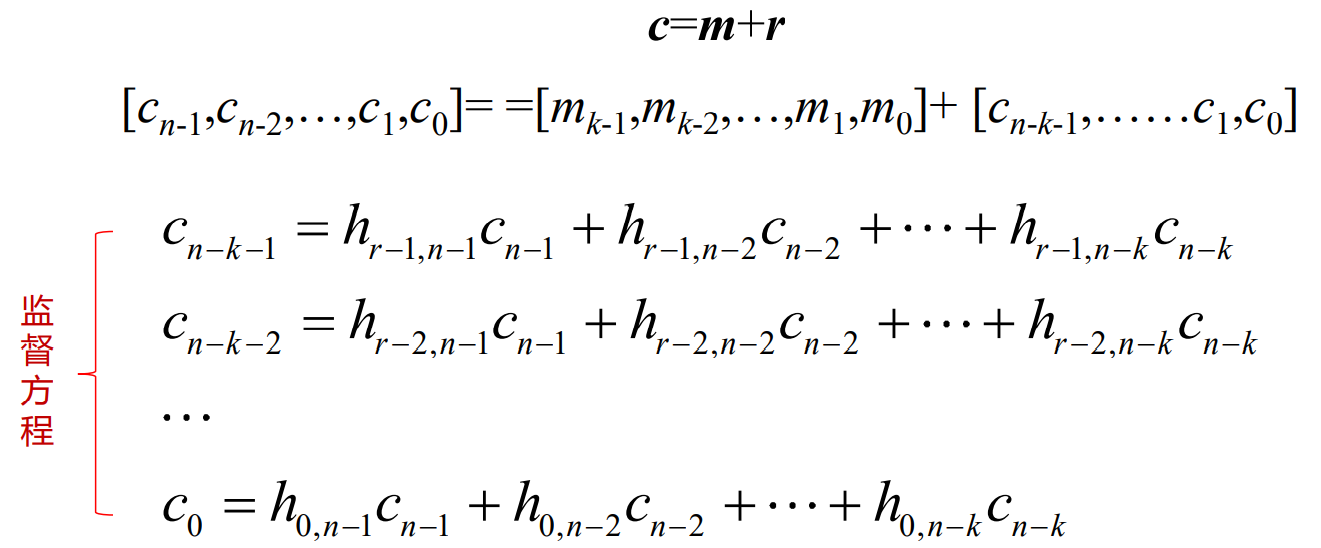

- 这就是监督方程的矩阵形式,其中的系数矩阵H称为这个线性分组码的一致监督矩阵(也称为奇偶校验矩阵),简称监督矩阵(或校验矩阵),H矩阵是一个(n-k)×n矩阵,即r行n列矩阵
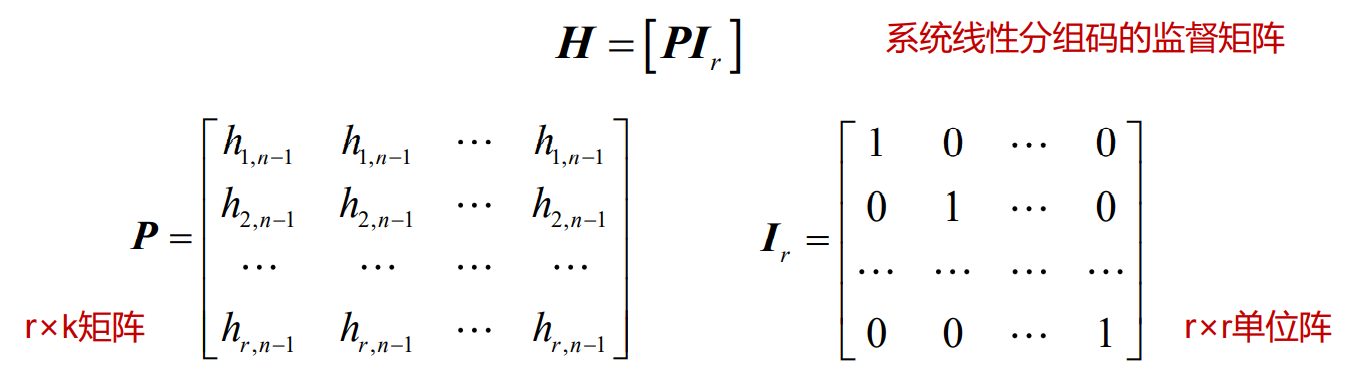
- 系统线性分组码的生成矩阵(G矩阵)
- 一般情况下的生成矩阵
- 一个(n,k)线性分组码C是一个n维向量空间的一个k维子空间,则在码组C中,一定存在k个线性独立的码字向量(基底),g_k-1, g_k-2, …, g_1, g_0,使得码组C中的每个码字c都是这k个码字的一种线性组合,即
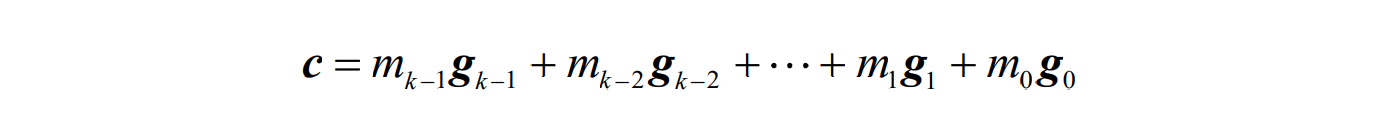
- 每一个基底都是一个n重向量,可以写成
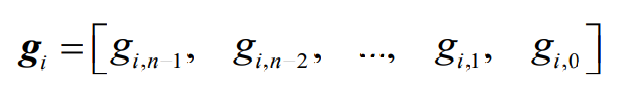
- 将k个基底写成一个k行n列的矩阵就是这个线性分组码C的生成矩阵G
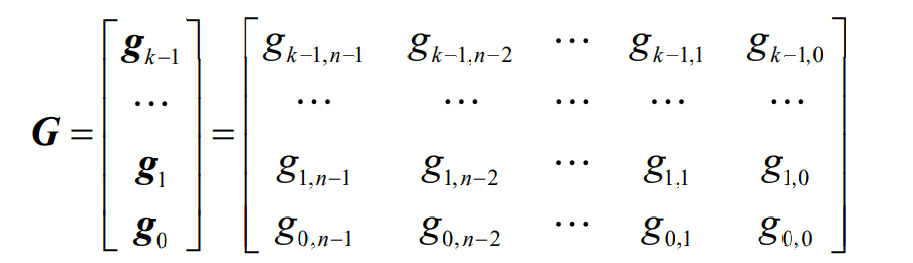
- 线性分组码的码字向量c、消息分组向量m与生成矩阵G的关系为
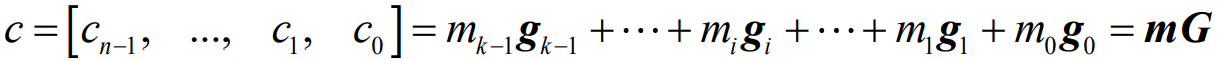
- 这k个基底向量是线性无关的,因此由这k个向量构成的生成矩阵G的秩一定等于k
- 当信息码字给定后,线性分组码字就由生成矩阵G决定,也就是说,线性分组码编码器的工作过程就是根据生成矩阵G将输入的消息分组m变换为输出的码字向量c的过程
- 由此可知,设计一个(n,k)线性分组码生成矩阵的问题实际上就是选择n维向量空间中k维子空间的k个线性无关码字向量的问题,也就是寻找基底的问题
n维向量空间中的k维子空间的基底可能是不唯一的,因此所构成的生成矩阵G也是不同的,可能产生不同的码组
4.6 系统码与非系统码
系统码与非系统码的生成矩阵和监督矩阵都有明显的结构差异,同时,线性分组码的监督矩阵和生成矩阵之间也存在一定的代数关系
- 线性分组码生成矩阵G是由k个基底作为行向量构成的,所谓基底就是k维子空间中k个线性无关的n重向量,基底是不唯一的
- 根据线性空间理论,生成矩阵G经过初等行变换后不会改变矩阵的秩,变换后的k个行向量仍然是相性无关的。利用这一点,我们可以使一个(n, k)线性分组码的生成矩阵具有如下的形式
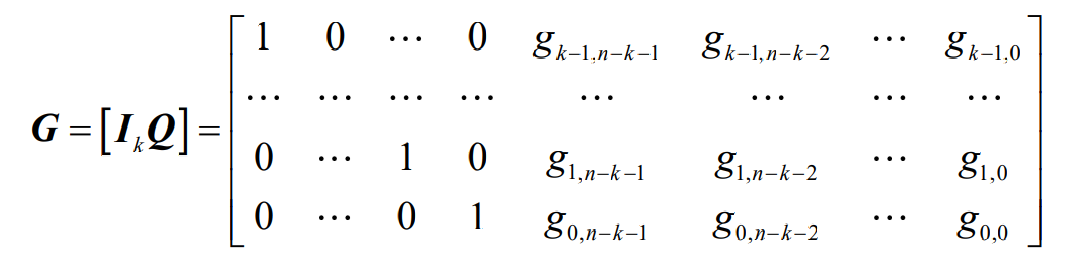
- 这种形式的生成矩阵称为典型生成矩阵(或标准型),它产生的线性分组码是一种系统线性分组码
- 其中Q为一个k×r矩阵, I_k为k×k单位阵
- 反之,不具备这种形式的生成矩阵所产生的线性分组码就是非系统码
非系统码与系统码并无本质区别,非系统码的生成矩阵可以通过矩阵的初等行变换转换为系统码的生成矩阵
对于系统码存在关系
- 如果已知一个系统线性分组码的典型生成矩阵为式为:

- 基本监督矩阵为的形式为:
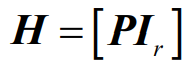
- 根据正交性可知
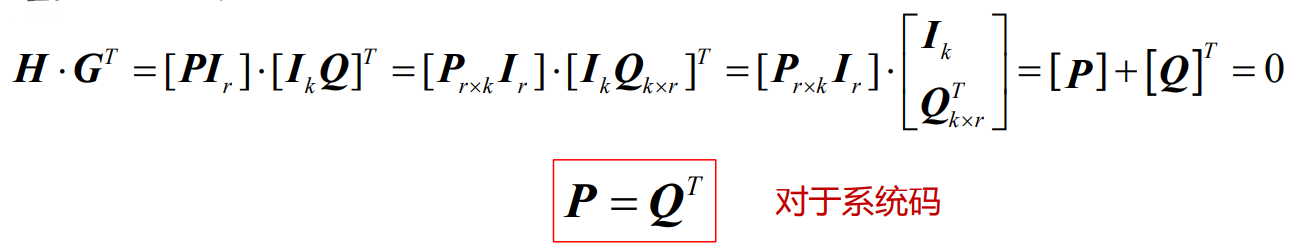
4.7 H矩阵和G矩阵的确定
- 首先设计n和k,确定了n和k之后,就在n维空间Vn中找到k维子空间Sk,就是找到Sk的基底(k个n重向量)
- 将这k个基底作为行向量构成一个矩阵,就是一个生成矩阵G。但是这个矩阵不一定是系统线性分组码标准形式
- 可以通过矩阵的初等变换,把这个G矩阵变成标准形式,就得到了系统码的生成矩阵
- 根据G矩阵与H矩阵的正交关系,就可以求得标准形式的监督矩阵
- 进而得到监督方程(校验方程),可以设计编码电路和译码电路
- 实际上,无论是标准形式还是非标准形式,线性分组码的G矩阵和H矩阵都是相互正交的
- 因此,也可以找到非标准形式G矩阵,直接求与其正交的H矩阵
把H矩阵变成标准形式,再求出标准型的G矩阵
子空间的基底寻找
- 假定我们的一个5维向量空间V5中确定一个子空间
- 任意找6个向量,一定是相关的,利用矩阵消元法
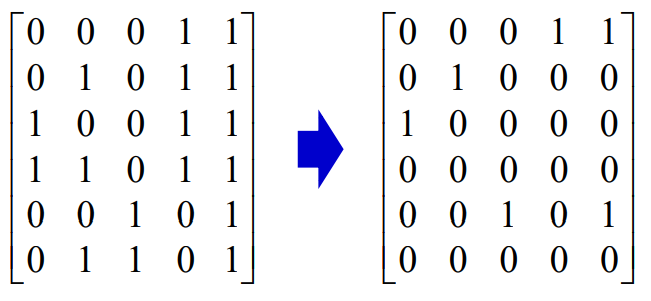
- 可见,其中的4个向量是线性无关的,也就找到了一个4维子空间的基底
这样就可以得到了一个(5,4)分组码的生成矩阵
再看V5空间上的三个向量,也是一个3维子空间的基底,产生一个(5,3)分组码
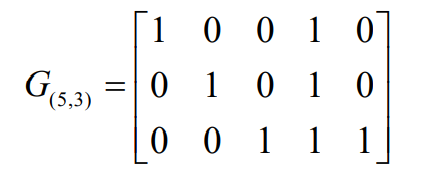
- 其对应监督矩阵为:
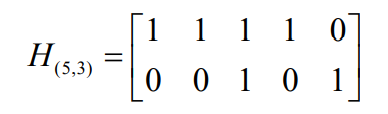
- 根据对偶码的关系,(5,3)分组码的对偶码的生成矩阵为:
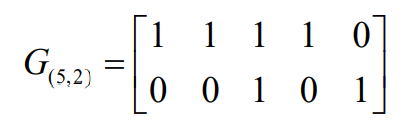
可以验证:两个子空间中的码字向量是相互正交的(内积等于0)
n维线性空间Vn的k维子空间Sk一定存在一个的对偶空间Sn-k。k维子空间一般不是唯一的, Vn空间和子空间基底一般也不是唯一的。
- 子空间的生成矩阵也不是唯一的,同一个码组有不同的生成矩阵,有系统码和非系统码之分
- 求一个码组的对偶码的办法:确定原码的标准型生成矩阵,求出原码的监督矩阵,用原码监督矩阵作为对偶码的生成矩阵产生的码字空间就是对偶码
- 原码的所有码字与对偶码的所有码字相互正交,这两个子空间称为零化空间
- 任何一k维子空间都可以构成一个(n,k)线性分组码,具有码字向量的自闭性等,但是具有什么样的纠错能力,要看最小汉明距
同样的(n,k)分组码,编码效率一样,但是纠错能力可能不一样,因此有好码和非好码之分
4.8 校验子与标准阵译码
校验子译码
- 发送的二元码字c=[cn-1,cn-2,……,c1,c0]在有噪信道上传输将受到干扰并产生差错,反映到接收码字上可以用一个二元向量来表示,称为错误图样(error patterns),表示为
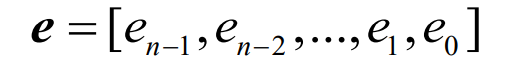
- 接收码字可以表示为
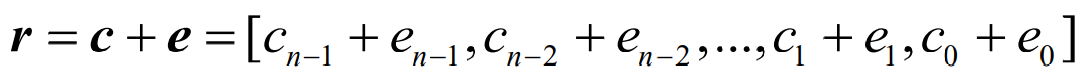
- 对于接收码字r,译码器根据已知的监督矩阵H计算如下关系式
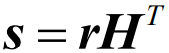
- 分析可知
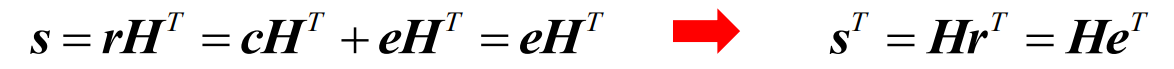
- 其中s为一个n-k=r重向量,称为校验子,或称为伴随式(syndrome),可表示为
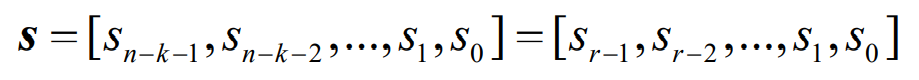
- 校验子也叫校验子向量
- 根据监督矩阵和错误图样的定义可以看出,如果校验子向量s≠0,接收码字一定有错误
- 如果校验子向量s=0,译码器认为接收码字无错误(也可能存在不可纠正的错误)
- 例题
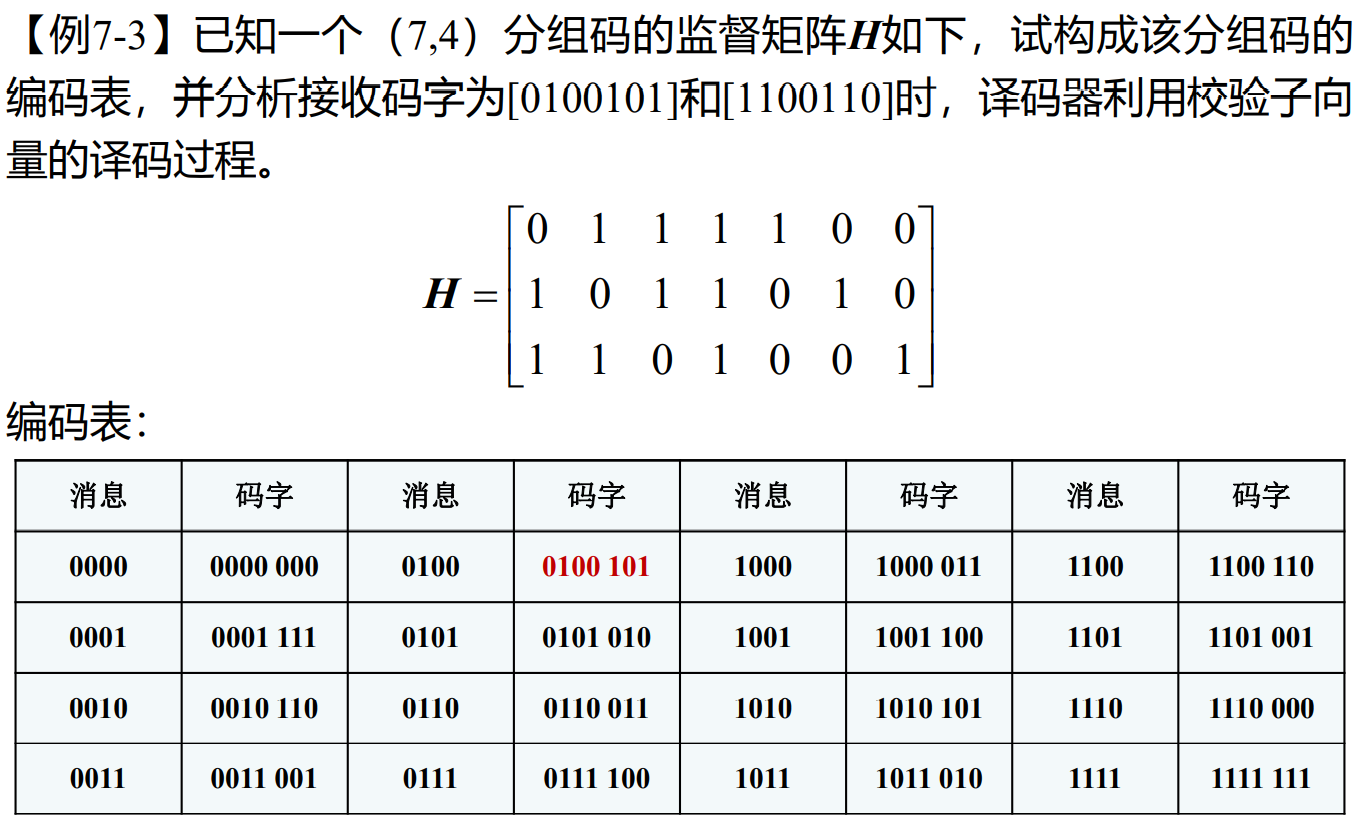
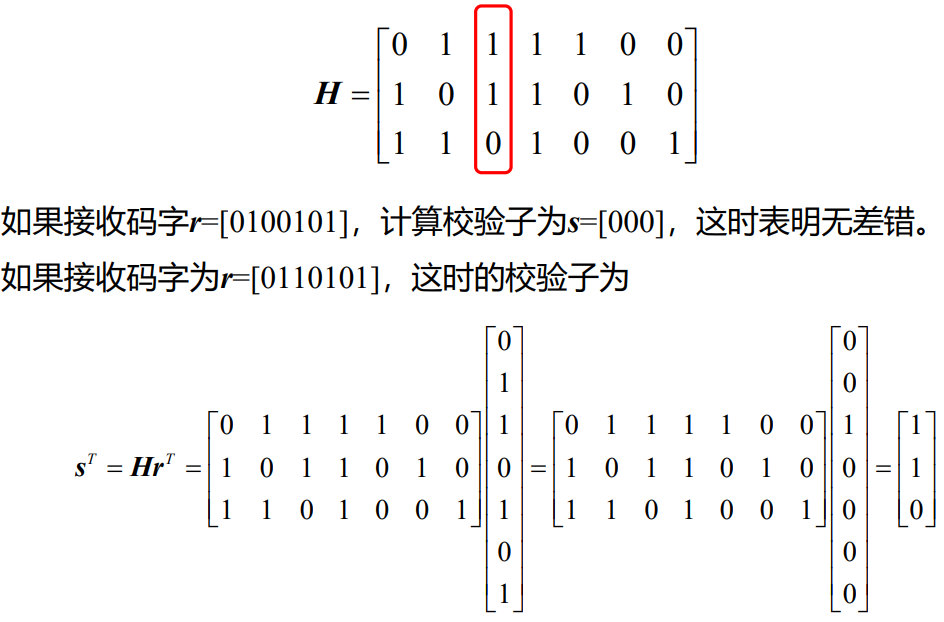
- 标准阵译码:
- 线性分组码译码的基本过程就是对于每一个接收码字向量r,利用确定好的监督矩阵来计算校验子向量,按最大似然准则得到错误图样,最后得到发送码字向量的估计值。(n,k)线性分组码的译码包括以下步骤:
- 由接收码字向量r计算校验子s^T=Hr^T
- 若s=0,则译码器认为接收码字无差错,若s≠0则认为有差错,并由s计算错误图样e
- 根据错误图样进行译码(纠错),确定发送码字的估计值
- 在这个译码过程中最困难的是第二步,确定错误图样,即错误定位
这里介绍一个基本的译码方法,标准阵译码,即查表法译码
(n,k)线性分组码是n维矢量空间中的一个k维子空间
- 码组中有2^k个码字,码组在有限域GF(2)上是一个子空间
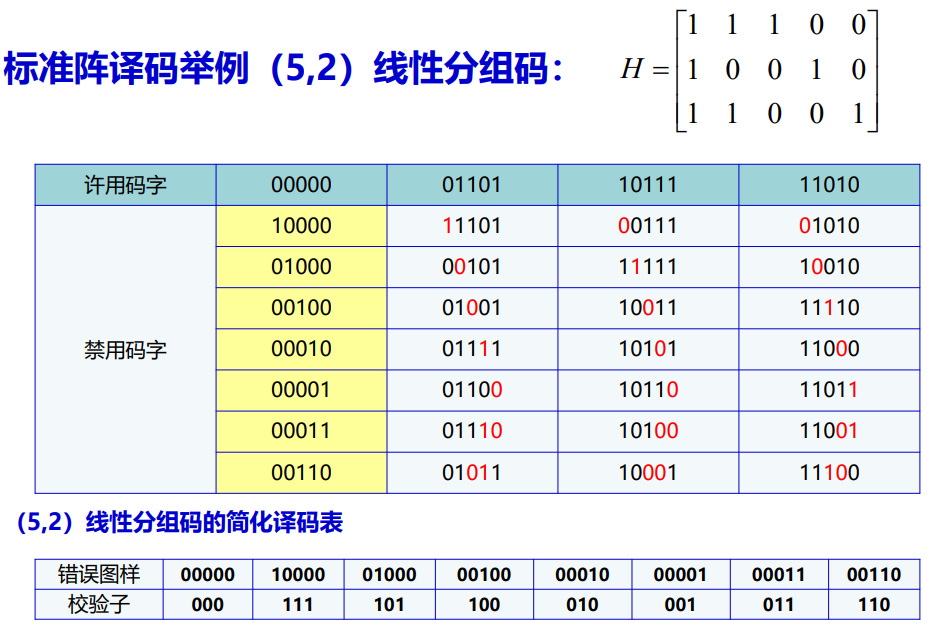
- 利用分元陪集(陪集表Coset table)方法,可以用子空间的所有2^k个向量,生成n维空间中的所有2^n个向量。我们把分元陪集的过程用一个表来描述,这个表称为标准阵译码表

- 标准阵译码表的构成方法按照以下几个步骤
- 将该分组码码组(子空间)中的2^k个码字向量(许用码字)放在表中的第一行,构成第一个陪集,该子群的加法单位元c_0=(00…0)放在第一列,作为第一个陪集的陪集首
- 在所有禁用码字向量中,挑出一个汉明重量最小的n重向量放在第二行的第一列,作为第二个陪集的陪集首,将第一行的相应向量与第二个陪集的陪集首相加,构成第二个陪集
- 依次进行,直至构成第2^r个陪集,完成的标准阵译码表将包括n维空间的所有2^n个n重向量,这个标准阵为2^(n-k)=2^r行2k列

- 标准阵译码的基本思想:
- 接收到的码字向量r必然在这个标准阵当中,译码器对每一个接收的码字向量利用查表法就可以实现译码
- 译码规则:
- 如果接收到的码字落在标准阵的第一行,就认为没有差错。如果接收码字r 落在标准阵的某一列(不在第一行),译码器就认为发送的码字是这一列中第一行的许用码字,也就是说译码器认为此时的错误图样是接收码字r 所在陪集的陪集首
- 在随机信道中,错误图样的汉明重量越小,其产生的可能性越大,进而利用标准阵译码表正确译码的可能性就越大,所以在设计译码表时选择汉明重量最轻的禁用码字作为陪集首
- 标准阵译码表的码设计满足最小汉明距离译码准则,同样可以证明在BSC信道条件下,最小汉明距离译码等价于最大似然译码
- 例子
4.9 特殊的码组
- 奇偶校验码
- 码组{000,011,101,110}也是一个线性分组码,(3,2)分组码,其生成矩阵和校验矩阵:

- 自对偶码:
- 码组{00,11}也是一个线性分组码,(2,1)分组码,其生成矩阵和校验矩阵:

这个码字的对偶码就是本身,称为Self-dual codes
5. 汉明码
5.1 监督矩阵H与最小汉明距离的关系
如果C为一个线性分组码的码组,u和v是码组C中的任意两个码字,则码组C的最小汉明距离定义为:
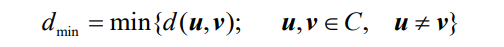
- 如果u,v,w为n维空间中的向量,则存在所谓三角不等式的关系,即
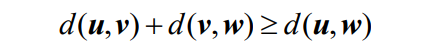
- 如果C为一个线性分组码,u,v为码组C中的两个码字,则这两个码字的和w=u+v也必然是码组C中的一个码字,则根据最小码距的定义有
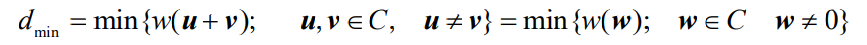
- 存在定理:
- 线性分组码的最小汉明距离等于码组中非零码字的最小汉明重量
因此,对于一个线性分组码,确定其最小汉明距离等价于确定其最小汉明重量
最小汉明距离与监督矩阵的关系
- (n,k)线性分组码C的监督矩阵为H。如果线性分组码的最小码距等于d,则H矩阵的d-1个列向量线性无关(d个列向量之和为零)。反之,如果H矩阵的d-1个列向量线性无关(d个列向量之和为零),则该线性分组码的最小码距为d
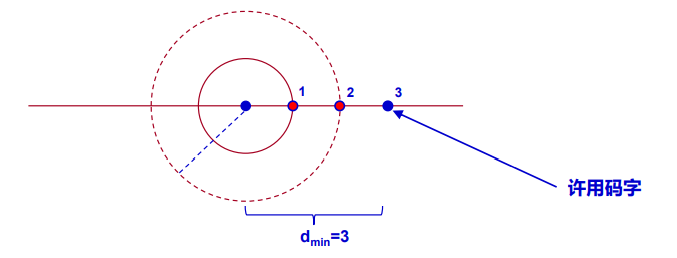
- 举例:(7,4)汉明码的监督矩阵,任何2列相加不等于0;任何3列相加可能为0。所以其最小码距dmin=3
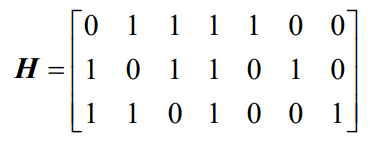
- 推论:
设(n,k)线性分组码C的监督矩阵为H。改变监督矩阵列向量的位置,不会影响列向量的相关性,也就不会影响码组的最小汉明距离。通过改变监督矩阵列向量的位置可能产生不同的码组,但其纠错检错能力是相同的。
可以得到关于线性分组码检错能力的结论
- 最小汉明距离为dmin的线性分组码,能检出所有dmin-1位或更少位码元错误的错误图样
- 最小汉明距离为dmin的码,不能检测出所有的dmin位错误,但有可能检出一些dmin位或更多位的码元错误
(n,k)线性分组码能检出长度为n的2n-2k个错误图样,因为2n-2k是禁用码字的个数,收到禁用码字就等于检出错误(但可能无法纠正错误)
5.2 汉明码定义
对于任意正的整数r≥3,存在具有下列参数的线性分组码C:
- 码长:n=2^r-1
- 信息码元:k=2^r-1-r=n-r
- 监督元:r=n-k
- 最小码距:dmin=3
这个码组C称为狭义汉明码
汉明码是1950年被提出的一种线性分组码,后被证明是一种完备码
汉明码是一种纠1位错误的线性分组码,其最小码距为3
- 若最小码距等于3,监督矩阵H中至少为任意两列线性无关;这也就意味着没有全0列,每一列均不相同,即任何两列相加不等于0。
对于任何一个(n,k)线性分组码有2^r=2^(n-k)个监督元(校验位),在二进制情况下,这r个监督元可以构成2^r个互不相同的r重列向量,其中有1个全0列向量,有2^r-1个非全0列向量。因此,只要用这2^r-1个非全0列向量作为H矩阵的列向量,就可以保证H矩阵的至少任何两列向量线性无关,也就可以确定一个(n,k)汉明码。
例如,(7,4)汉明码的监督矩阵为
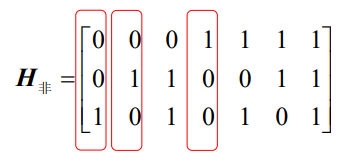
- 很容易可以得到,(7,4)系统汉明码的一个监督矩阵为
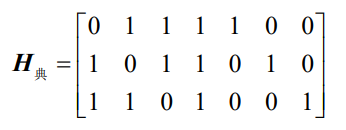
5.3 特殊的汉明码
- 广义汉明码
- 根据汉明码的定义,狭义汉明码的监督位为r≥3,码长和信息位长度分别为n=2^r-1和k=n-r,汉明码的码长和信息位长度都是受限制的,但是存在特殊的缩短汉明码
- 例如:(7,4)汉明码缩短码为(6,3)分组码,其监督矩阵HS可以将(7,4)汉明码的监督矩阵减少一列而得到

- 增余汉明码
- 也称扩展汉明码
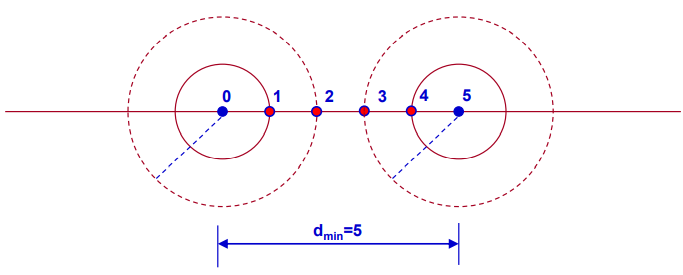
- 在(n,k)汉明码的基础上,通过增加一位监督元,它取为所有码元的模2加,这样就构成一个(n+1,k)汉明码。其最小码距为dmin=4,可以在纠一位错的同时检两位错
- 例如:由(7,4)汉明码可以扩展出(8,4)增余汉明码,其一致监督矩阵H_E为
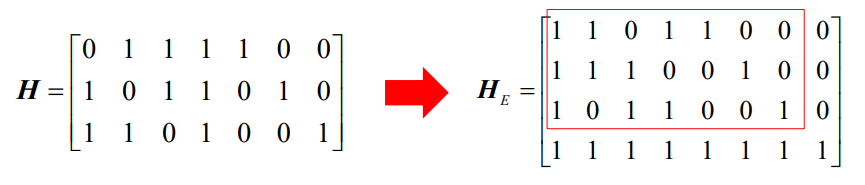
5.4 汉明码与完备码
- 对于二元(n,k)线性分组码的一个码字
- n个码元无差错的错误图样为:

- 只有一位码元差错的错误图样为:

- 有t位码元差错的错误图样为:

- 另一方面,(n,k)线性分组码有2n-k个校验子向量,若要纠正所有小于等于t个码元错误,就必须有大于等于t+1个校验子向量与之对应,分别指出无错和哪t位错。
- 此时校验子向量的个数应当满足:
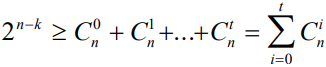
这个关系式称为汉明界,它是构造纠正t位错的(n,k)线性分组码的必要条件
完备码
- 该(n,k)线性分组码使汉明界的等号成立,校验子向量的个数与所有可纠正的错误图样数正好相等,说明校验位得到了充分的利用
- 在完备码的标准阵译码表中,重量小于等于t的所有错误图样作为陪集首就可以构成全部n维空间,也就是说,不会使用重量大于t的禁用码字作为陪集首
- perfect codes
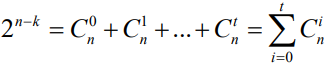
- Almost perfect codes
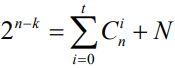
- 完备码是较少的,上面给出的汉明码定义确定狭义汉明码是一种完备码
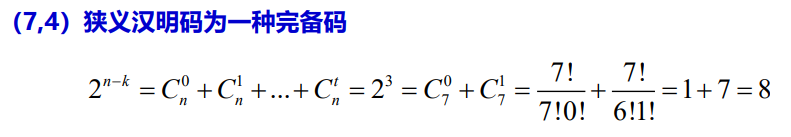
n=7, k=4, t=1
线性分组码译码方法中可以看出,译码器接收到一个错误码字(禁用码字)后是利用比较这个错误码字与所有许用码字之间的汉明距离来实现译码的。
- 判断与这个错误码字汉明距离最小的许用码字为发送码字,这种方法也就是最小汉明距离译码。
在(n,k)线性分组码的译码过程中,如果所有2^(n-k)=2^r个校验子(伴随式),都用来纠正所有t=(d-1)/2个随机错误及大部分大于t个码元错误,则称这种译码方法为完备译码,否则称为非完备译码
如果译码器对于每个接收码字,都可以明确判决出发送码字,称为完备译码
- 如果译码器对于一些接收码字可以做出明确判决,而对于另外一些接收码字不能做出明确判决,称为不完备译码
例如:(3,1)重复码的译码可以实现完备译码,而对于(4,1)重复码,当一个码字错两位时,译码器不能明确判决,只能是不完备译码
限定距离译码
- 如果一个(n, k)线性分组码,能纠正t小于等于(d-1)/2个码元错误。在译码时只纠正t’< t个码元错误,而当错误码元个数大于t’时,译码器只检出错误而不纠正错误。
- 例如:
当一个线性分组码的最小码距为5时,可以纠两位错误,如果译码器只纠1位错,而大于1位错时只检出不纠正,就是限定距离译码
5.5 汉明码的生成矩阵和监督矩阵
线性分组码的生成矩阵G,经过初等行变换不改变码组(子空间)也就是说可以由不同的基底张成了同个子空间
- 如果进行初等变换(包括行变换和列变换),可能会改变码组,张成不同的子空间。但是,仍然是一个线性分组码。因为,矩阵的初等变换不会改变矩阵的秩,也就是不改变行向量的线性无关性质。所以,初等变换会很快找到一个典型的生成矩阵。
- 同样,线性分组码的监督矩阵,也可以进行初等变(行列都可以),因为行的初等变换不会改变列向量的相关性
这样并不影响性列的相关性,可能产生不同的码子空间(码组),但是都是汉明码
5.6 辛格尔顿界(Singleton bound)
如果一个(n, k)线性分组码的最小汉明距离为dmin,那么,其校验位的个数一定满足
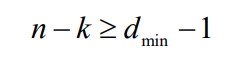
- 可见,即使是汉明码也没有达到等号的界。等号成立的线性分组码称为最大距离可分离码(MDS-maximum distance separable)
- 二元MDS码包括:
- (n, n) 分组码,dmin=1,n-k=0,等号成立,但是没有纠错能力
- (n, 1)分组码,dmin=n,n-k=n-1,等号成立,但是效率太低
- (n, n-1)分组码,奇偶校验码,例如:码组{000,011,101,110}也是一个线性分组码,dmin=2,n-k=1,等号成立,纠错能力有限
- 著名的非二进制MDS码就是Reed-Solomon码,也就是多元BCH码

若有收获,就点个赞吧
0 人点赞
