原文链接:X3D:Expanding Architectures for Efficient Video Recognition_2020CVPR 代码链接:https://github.com/facebookresearch/SlowFast 博客参考:CVPR2020 FAIR X3D超轻量级行为识别模型
规定:
- 加粗表示进一步强调;
- 红色、橙色标注表示为重要信息;
- 斜体、下划线以及背景色表示突出;
- 绿色标注表示困惑的地方;
Abstract
This paper presents X3D, a family of efficient video networks that progressively expand a tiny 2D image classification architecture along multiple network axes, in space, time, width and depth. Inspired by feature selection methods in machine learning, a simple stepwise network expansion approach is employed that expands a single axis in each step, such that good accuracy to complexity trade-off is achieved. To expand X3D to a specific target complexity, we perform progressive forward expansion followed by backward contraction. X3D achieves state-of-the-art performance while requiring and
and  fewer multiply-adds and parameters for similar accuracy as previous work. Our most surprising finding is that networks with high spatiotemporal resolution can perform well, while being extremely light in terms of network width and parameters. We report competitive accuracy at unprecedented efficiency on video classification and detection benchmarks.
fewer multiply-adds and parameters for similar accuracy as previous work. Our most surprising finding is that networks with high spatiotemporal resolution can perform well, while being extremely light in terms of network width and parameters. We report competitive accuracy at unprecedented efficiency on video classification and detection benchmarks.
Introduction
Neural networks for video recognition have been largely driven by expanding 2D image architectures into spacetime. Naturally, these expansions often happen along the temporal axis, involving extending the network inputs, features, and/or filter kernels into spacetime; other design decisions—including depth (number of layers), width (number of channels), and spatial sizes—however, are typically inherited from 2D image architectures. While expanding along the temporal axis (while keeping other design properties) generally increases accuracy, it can be sub-optimal if one takes into account the computation/accuracy trade-off—a consideration of central importance in applications.本文的主要目的是在精度和计算量上做一个权衡。正如本文所述,扩展时间轴的方式的确是一种提高准确率的方式。
In part because of the direct extension of 2D models to 3D, video recognition architectures are computationally heavy. In comparison to image recognition, typical video models are significantly more compute-demanding, e.g. an image ResNet can use around  fewer multiply-add operations than a temporally extended video variant.
fewer multiply-add operations than a temporally extended video variant.
This paper focuses on the low-computation regime in terms of computation/accuracy trade-off for video recognition. We base our design upon the “mobile-regime” models developed for image recognition. Our core idea is that while expanding a small model along the temporal axis can increase accuracy, the computation/accuracy trade-off may not always be best compared with expanding other axes, especially in the low-computation regime where accuracy can increase quickly along different axes.
核心思想:不单单是扩展时域轴,同样可以考虑扩展其它轴来提升准确率。
In this paper, we progressively “expand” a tiny base 2D image architecture into a spatiotemporal one by expanding multiple possible axes shown in Fig. 1. The candidate axes are temporal duration  , frame rate
, frame rate  , spatial resolution
, spatial resolution  , network width
, network width  , bottleneck width
, bottleneck width  , and depth
, and depth  . The resulting architecture is referred as X3D (Expand 3D) for expanding from the 2D space into 3D spacetime domain.
. The resulting architecture is referred as X3D (Expand 3D) for expanding from the 2D space into 3D spacetime domain.
主要是如何实现这种扩展的,不同的参数如何选取。
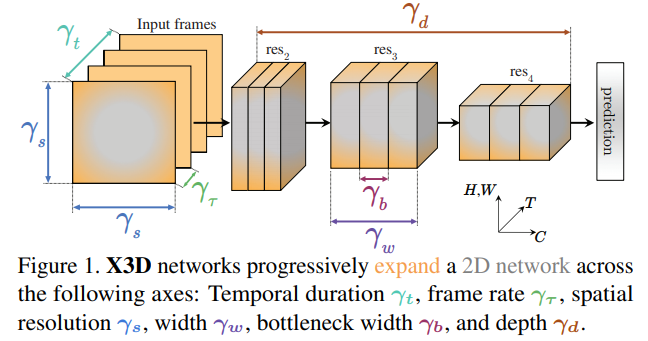
The 2D base architecture is driven by the MobileNet core concept of channel-wise separable convolutions, but is made tiny by having over  fewer multiply-add operations than mobile image models. Our expansion then progressively increases the computation (e.g., by
fewer multiply-add operations than mobile image models. Our expansion then progressively increases the computation (e.g., by  ) by expanding only one axis at a time, train and validate the resultant architecture, and select the axis that achieves the best computation/accuracy trade-off. The process is repeated until the architecture reaches a desired computational budget. This can be interpreted as a form of coordinate descent in the hyper-parameter space defined by those axes.
) by expanding only one axis at a time, train and validate the resultant architecture, and select the axis that achieves the best computation/accuracy trade-off. The process is repeated until the architecture reaches a desired computational budget. This can be interpreted as a form of coordinate descent in the hyper-parameter space defined by those axes.
Our progressive network expansion approach is inspired by the history of image ConvNet design where popular architectures have arisen by expansions across depth, resolution or width, and classical feature selection methods in machine learning. In the latter, progressive feature selection methods start with either a set of minimum features and aim to find relevant features to improve in a greedy fashion by including (forward selection) a single feature in each step, or start with a full set of features and aim to find irrelevant ones that are excluded by repeatedly deleting the feature that reduces performance the least (backward elimination).
本文想要做的就是综合这些扩展方式,找到一种在计算和准确率之间权衡最优的扩展结构。问题是,现在应该如何去找这种结构?
Overall, our expansion produces a sequence of spatiotemporal architectures, covering a wide range of computation/accuracy trade-offs. They can be used under different computational budgets that are application-dependent in practice. For example, across different computation and accuracy regimes X3D performs favorably to state-of-theart while requiring 4.8× and 5.5× fewer multiply-adds and parameters for similar accuracy as previous work. Further, expansion is simple and cheap e.g. our low-compute model is completed after only training 30 tiny models that accumulatively require over 25× fewer multiply-add operations for training than one large state-of-the-art network.
Conceptually, our most surprising finding is that very thin video architectures that are created by expanding spatiotemporal resolution perform well, while being light in terms of network width and parameters. X3D networks have lower width than image-design based video models, making X3D similar to the high-resolution Fast pathway which has been designed in such fashion. We hope these advances will facilitate future research and applications.
同样抱着扩展如何实现的疑问。
Related Work
Spatiotemporal (3D) networks. Video recognition architectures are favorably designed by extending image classification networks with a temporal dimension, and preserving the spatial properties. These extensions include direct transformation of 2D models such as ResNet or Inception to 3D, adding RNNs on top of 2D CNNs, or extending 2D models with an optical flow stream that is processed by an identical 2D network. While starting with a 2D image based model and converting it to a spatiotemporal equivalent by inflating filters allows pretraining on image classification tasks, it makes video architectures inherently biased towards their image-based counterparts.
The SlowFast architecture has explored the resolution trade-off across several axes, different temporal, spatial,and channel resolution in the Slow and Fast pathway. Interestingly the Fast pathway can be very thin and therefore only adds a small computational overhead; however, performs low in isolation. Further, these explorations were performed with the architecture of the computationally heavy Slow pathway held constant to a temporal extension of an image classification design. In relation to this previous effort, our work investigates whether the heavy Slow pathway is required, or if a lightweight network can be made competitive.
Efficient 2D networks. Computation-efficient architectures have been extensively developed for the image classification task, with MobileNetV1&2 and ShuffleNet exploring channel-wise separable convolutions and expanded bottlenecks. Several methods for neural architecture search in this setting have been proposed, also adding Squeeze-Excitation (SE) attention blocks to the design space in [72] and more recently, MobileNetV3 [31] Swish non-linearities [59]. MobileNets [32, 61, 72] were scaled up and down by using a multiplier for width and input size (resolution). Recently, MnasNet [72] is used to apply liner scaling factors to spatial, width and depth axes for creating a set of EfficientNets for image classification. Our expansion is related to this, but requires fewer samples and handles more axes as we only train a single model for each axis in each step
这些都是些什么神奇的方法???
Efficient 3D networks. Several innovative architectures for efficient video classification have been proposed, e.g. [3, 6, 10,12,14,19,36,45,48,55,57,68,69,76,78,79,85,89,97–99]. Channel-wise separable convolution as a key building block for efficient 2D ConvNets [31, 32, 61, 73, 95] has been explored for video classification in [45,76], where 2D architectures are extended to their 3D counterparts, e.g. ShuffleNet and MobileNet in [45], or ResNet in [76] by using a 3×3×3 channel-wise separable convolution in the bottleneck of a residual stage. Earlier, [10] adopt 2D ResNets and MobileNets from ImageNet and sparsifies connections inside each residual block similar to separable or group convolution. A temporal shift module (TSM) is introduced in [51] that extends a ResNet to capture temporal information using memory shifting operations. There is also active research on adaptive frame sampling techniques, e.g. [2,46,65,86,87,91], which we think can be complementary to our approach.
与视频动作分类相关的论文很多,可以依次了解一下! 还有两个概念:separable convolution and group convolution
X3D Networks
Image classification architectures have gone through an evolution of architecture design with progressively expanding existing models along network depth [8,29,47,64,71,94], input resolution [35, 70, 73] or channel width [88, 93]. Similar progress can be observed for the mobile image classification domain where contracting modifications (shallower networks, lower resolution, thinner layers, separable convolution [31, 32, 37, 61, 95]) allowed operating at lower computational budget.
For video classification the temporal dimension exposes an additional dilemma(困境), increasing the number of possibilities but also requiring it to be dealt differently than the spatial dimensions [15, 63, 77]. We are especially interested in the trade-off between different axes.
- data layer 用来选择输入的视频帧的采样率、时空分辨率等。这个层非常有趣。
- 时间轴在前面特征提取的操作内,一直都是
- 网络的时域卷积和空域卷积是分开的,如 conv1 所示。
- channel 表示的是每一帧图片产生的 channel 数,它与时域的帧数是独立的。
中的
卷积为channel-wise卷积(**conv1有点奇特,3指的是时域跨度,1表示的是channel跨度?**)。
- 有的地方说 3×3×3 使用了channel-wise separable convolution(感觉不太对)!
作者的一些思考:
What is the best temporal sampling strategy for 3D networks? Is a long input duration and sparser sampling preferred over faster sampling of short duration clips?
对于视频数据,自己在采样、持续时间以及分辨率等方面也有困惑。
Do we require finer spatial resolution? Previous works have used lower resolution for video classification [42, 75, 77] to increase efficiency. Also, videos typically come at coarser spatial resolution than Internet images; therefore, is there a maximum spatial resolution at which performance saturates?
- Is it better to have a network with high frame-rate but thinner channel resolution, or to slowly process video with a wider model? E.g. should the network have heavier layers as typical image classification models (and the Slow pathway [15]) or rather lighter layers with lower width (as the Fast pathway [15]). Or is there a better trade-off, possibly between these extremes?
- When increasing the network width, is it better to globally expand the network width in the ResNet block design [29] or to expand the inner (“bottleneck”) width, as is common in mobile image classification networks using channel-wise separable convolutions [61, 95]?
- Should going deeper be performed with expanding input resolution in order to keep the receptive field size large enough and its growth rate roughly constant, or is it better to expand into different axes? Does this hold for both the spatial and temporal dimension?
网络初始化所有的 为一,这样就是一个适用于 2D 图像的网络。data layer完成数据的操作,包括采样等;conv1, filters the 3 RGB input channels and produces 24 output features. This width is increased by a factor of 2 after every spatial sub-sampling with a
为一,这样就是一个适用于 2D 图像的网络。data layer完成数据的操作,包括采样等;conv1, filters the 3 RGB input channels and produces 24 output features. This width is increased by a factor of 2 after every spatial sub-sampling with a  at each deeper stage from
at each deeper stage from  to
to  . Spatial sub-sampling is performed by the center (“bottleneck”) filter of the first res-block of each stage.
. Spatial sub-sampling is performed by the center (“bottleneck”) filter of the first res-block of each stage.
Similar to the SlowFast pathways [15], the model preserves the temporal input resolution for all features throughout the network hierarchy. There is no temporal downsampling layer (neither temporal pooling nor time-strided convolutions) throughout the network, up to the global pooling layer before classification. Thus, the activations tensors contain all frames along the temporal dimension, maintaining full temporal frequency in all features.
Network stages. X2D consists of a stage-level and bottleneck design that is inspired by recent 2D mobile image classification networks(channelwise separable convolution:变为了三维卷积,在 channel 维度进行滑动). We adopt stages that follow MobileNet [31, 61] design by extending every spatial 3×3 convolution in the bottleneck block to a 3×3×3 (i.e.  ) spatiotemporal convolution which has also been explored for video classification in [45, 76]. Further, the 3×1 temporal convolution in the first conv1 stage is channel-wise.
) spatiotemporal convolution which has also been explored for video classification in [45, 76]. Further, the 3×1 temporal convolution in the first conv1 stage is channel-wise.
Expansion operations
We define a basic set of expansion operations that are used for sequentially expanding X2D from a tiny spatial network to X3D, a spatiotemporal network, by performing the following operations on temporal, spatial, width and depth dimensions.
- X-Fast expands the temporal activation size, , by increasing the frame-rate,
 , and therefore temporal resolution, while holding the clip duration constant(时域的膨胀只是提高分辨率).
, and therefore temporal resolution, while holding the clip duration constant(时域的膨胀只是提高分辨率). - X-Temporal expands the temporal size, , by sampling a longer temporal clip and increasing the frame-rate , to expand both duration and temporal resolution.
- X-Spatial expands the spatial resolution, , by increasing the spatial sampling resolution of the input video.
- X-Depth expands the depth of the network by increasing the number of layers per residual stage by times.
- X-Width uniformly expands the channel number for all layers by a global width expansion factor .
- X-Bottleneck expands the inner channel width, , of the center convolutional filter in each residual block.
Progressive Network Expansion
We employ a simple progressive algorithm for network expansion, similar to forward and backward algorithms for feature selection [25, 39, 41, 44]. Initially we start with X2D, the basis model instantiation with a set of unit expanding factors of cardinality
of cardinality  . We use
. We use  factors,
factors,  , but other axes are possible.
, but other axes are possible.
Forward expansion. The network expansion criterion function, which measures the goodness for the current expansion factors , is represented as
, is represented as  . Higher scores of this measure represent better expanding factors, while lower scores would represent worse. In our experiments, this corresponds to the accuracy of a model expanded by . Furthermore, let
. Higher scores of this measure represent better expanding factors, while lower scores would represent worse. In our experiments, this corresponds to the accuracy of a model expanded by . Furthermore, let  be a complexity criterion function that measures the cost of the current expanding factors . In our experiments,
be a complexity criterion function that measures the cost of the current expanding factors . In our experiments,  is set to the floating point operations of the underlying network instantiation expanded by , but other measures such as runtime, parameters, or memory are possible. Then, the network expansion tries to find expansion factors with the best trade-off
is set to the floating point operations of the underlying network instantiation expanded by , but other measures such as runtime, parameters, or memory are possible. Then, the network expansion tries to find expansion factors with the best trade-off  ,
,  where
where  are the possible expansion factors to be explored and
are the possible expansion factors to be explored and  is the target complexity. In our case we perform expansion that only changes a single one of the a expansion factors while holding the others constant(控制变量法); therefore there are only a different subsets of Z to evaluate, where each of them alters in only one dimension from . The expansion with the best computation/accuracy trade-off is kept for the next step. This is a form of coordinate descent [83] in the hyper-parameter space defined by those axes.
is the target complexity. In our case we perform expansion that only changes a single one of the a expansion factors while holding the others constant(控制变量法); therefore there are only a different subsets of Z to evaluate, where each of them alters in only one dimension from . The expansion with the best computation/accuracy trade-off is kept for the next step. This is a form of coordinate descent [83] in the hyper-parameter space defined by those axes.coordinate descent:
- 对于多个坐标,每次固定其它坐标,当作常数,从而针对其中一个坐标进行极值求解。
特征选择:
- 使用贪心的方法找到能提升 performance 的 relevant features
- 删去对 performance最小的 feature
The expansion is performed in a progressive manner with an expansion-rate  that corresponds to the stepsize at which the model complexity is increased in each expansion step. We use a multiplicative increase of
that corresponds to the stepsize at which the model complexity is increased in each expansion step. We use a multiplicative increase of  of the model complexity in each step that corresponds to the complexity increase for doubling the number of frames of the model. The stepwise expansion is therefore simple and efficient as it only requires to train a few models until a target complexity is reached, since we exponentially increase the complexity.
of the model complexity in each step that corresponds to the complexity increase for doubling the number of frames of the model. The stepwise expansion is therefore simple and efficient as it only requires to train a few models until a target complexity is reached, since we exponentially increase the complexity.
Backward contraction. Since the forward expansion only produces models in discrete steps, we perform a backward contraction step to meet a desired target complexity, if the target is exceeded by the forward expansion steps. This contraction is implemented as a simple reduction of the last expansion, such that it matches the target. For example, if the last step has increased the frame-rate by a factor of two, the backward contraction will reduce the frame-rate by a factor < 2 to roughtly match the desired target complexity.
收缩复杂度,貌似只用于最后一层?
Experiments: Action Classification
Datasets. We perform our expansion on Kinetics-400 [43] (K400) with ∼240k training, 20k validation and 35k testing videos in 400 human action categories. We report top-1 and top-5 classification accuracy (%). As in previous work, we train and report ablations on the train and val sets. We also report results on test set as the labels have been made available [4]. We report the computational cost (in FLOPs) of a single, spatially center-cropped clip.2
Training. 从头开始训练,即没有使用 ImageNet 等的预训练模型,也没有对网络进行初始化,网络权值为随机值。
Inference. To be comparable with previous work and evaluate accuracy/complexity trade-offs we apply two testing strategies: (i)  : Temporally, uniformly samples
: Temporally, uniformly samples  clips (e.g.
clips (e.g.  ) from a video and spatially scales the shorter spatial side to
) from a video and spatially scales the shorter spatial side to  pixels and takes a
pixels and takes a  center crop, comparable to [46, 51, 76, 84]. (ii)
center crop, comparable to [46, 51, 76, 84]. (ii)  is the same as above temporally, but takes 3 crops of
is the same as above temporally, but takes 3 crops of  to cover the longer spatial axis, as an approximation of fully-convolutional testing, following [15, 81]. We average the softmax scores for all individual predictions.
to cover the longer spatial axis, as an approximation of fully-convolutional testing, following [15, 81]. We average the softmax scores for all individual predictions.
FLOPS: 注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。 FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。(最主要的是浮点加法和浮点乘法,定义一个加法和乘法表示一个flop)是简单的数学运算,python 的工具包可以对模型直接进行 flops 计算。
- 如何获取最终结果的方式需要多看别人的方法。
- 网络推理的速度不仅仅和FLOPs相关,还和数据的访问相关。
Expanded networks

The accuracy/complexity trade-off curve for the expansion process on K400 is shown in Fig. 2. Expansion starts from X2D that produces 47.75% top-1 accuracy (vertical axis) with 1.63M parameters 20.67M FLOPs per clip (horizontal axis), which is roughly doubled in each progressive step. We use 10-Center clip testing as our default test setting for expansion, so the overall cost per video is ×10. We will ablate different number of testing clips in Sec. 4.3. The expansion in Fig. 2 provides several interesting observations:
- expanding along any one of the candidate axes increases accuracy.
- Surprisingly, the first step selected by the expansion algorithm is not along the temporal axis; instead, it is a factor that grows the “bottleneck” width in the ResNet block design [29]. 这验证了MobileNetV2中的倒置残差结构.
- 第二步扩张的为帧数(因为最初只有单帧,因此扩展采样帧间隔和帧数是等同的),这也是我们认为“最应该在第一步扩张的维度”,因为这提供更多的时间信息.
- 第三步扩张的为空间分辨率,紧接着第四步为深度,接着是时间分辨率(帧率)和输入长度(帧间隔和帧数),然后是两次空间分辨率扩张,第十步再次扩张深度,An expansion of the depth after increasing input resolution is intuitive, as it allows to grow the filter receptive field resolution and size within each residual stage.(空间分辨率越高,则我们往往希望模型越深,以适应感受野需求).
- 值得注意的是,尽管模型一开始十分tiny(宽度比较小),但直到第十一步,模型才开始扩张全局的宽度,这使得X3D很像SlowFast的fast分支设计(时空分辨率很大但宽度很小),最后图里没显示扩张的两步为帧间隔和深度。
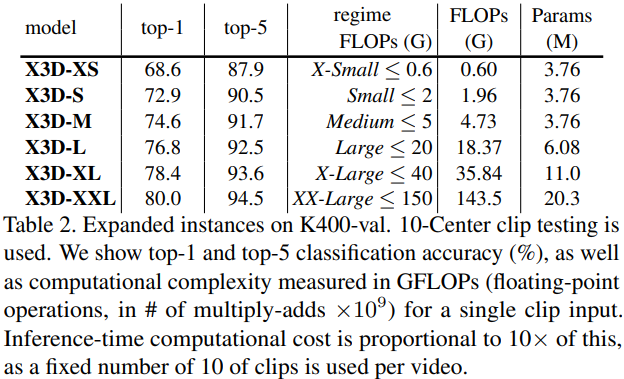
扩展之后的三个网络(网络复杂度不同):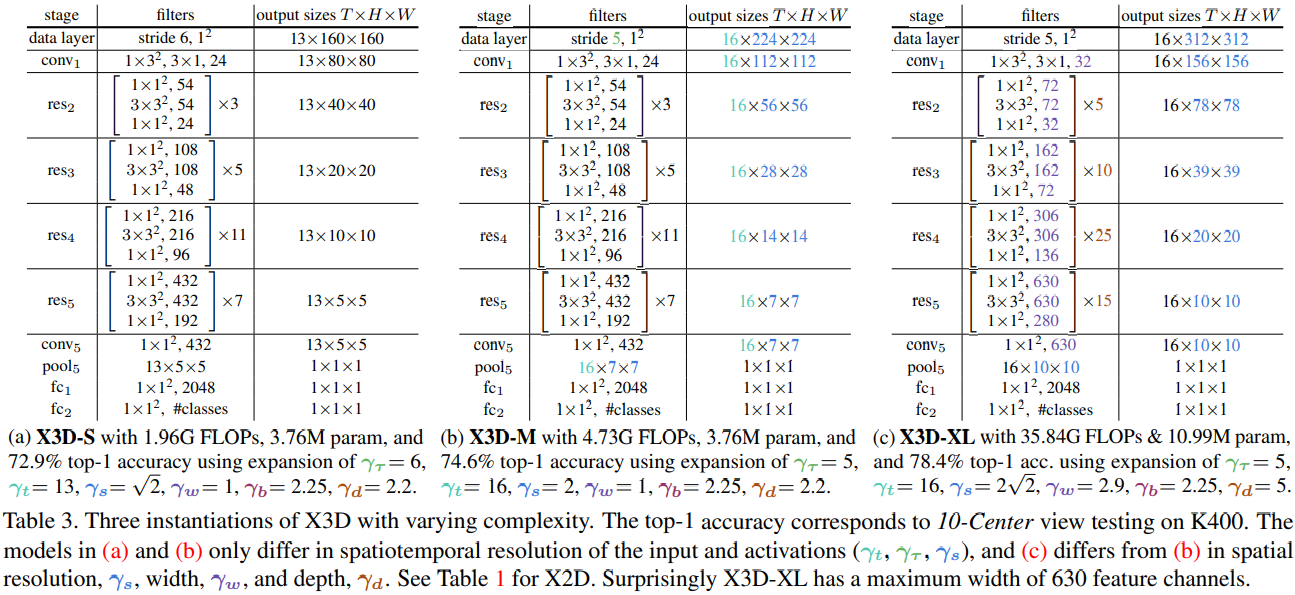
本文和其它方法的对比,主要从准确率和网络复杂度两个方面进行;当然也在不同的数据集上(Kinetics-400,Kinetics-600,Charades)验证方法的有效性。
Ablation Experiments
消融实验即是验证文章提出的不同 idea 具体的效果如何。论证方法:对比不采用本文 idea 和采用 idea 的结果差异,从效果提升验证自己观点的正确性。(本文在多个数据集上进行了测试,做消融实验时则可以只在其中一个数据集上进行验证)
和 EfficientNet3D 对比
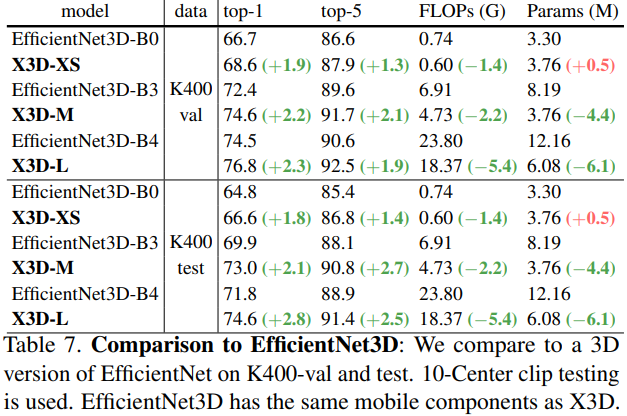
Inference cost
In many cases, like the experiments before, the inference procedure follows a fixed number of clips for testing. Here, we aim to ablate the effect of using fewer testing clips for video-level inference.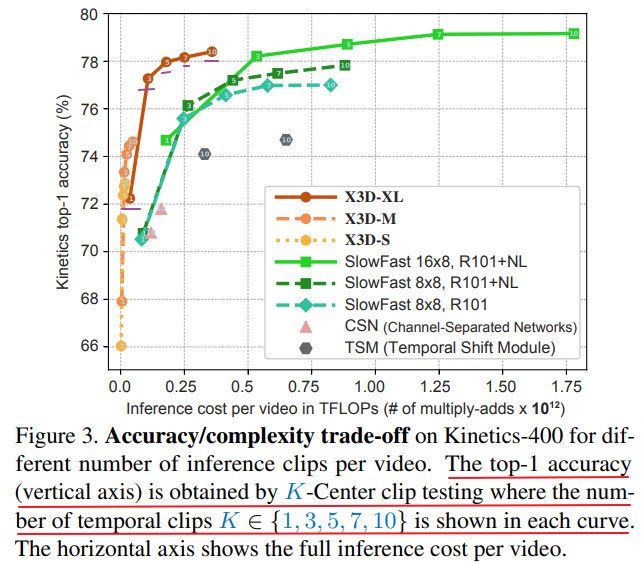
作者实验发现3clips与1clip相比准确率涨幅巨大,因为3clips包括了开始、中间和结束的部分,而1clip只包括中间的部分,而超过3clip增长缓慢,说明在不追求最高精度的前提下,稀疏clip采样策略更有效。
稀疏clip策略应该不适合类内动作的区分,即细粒度动作分类。
总结

若有收获,就点个赞吧
0 人点赞
