Author: Ross Girshick, Microsoft Research(R-CNN 的作者) 原文链接:Fast R-CNN 项目地址:https://github.com/rbgirshick/fast-rcnn 博客学习:https://www.jianshu.com/p/fbbb21e1e390 https://zhuanlan.zhihu.com/p/30368989
之前的 R-CNN 是分阶段的,并且他的 proposal 产生的方式采用的是 selective search 的方式,没有借助 CNN 的方法。CNN 只用在对 region proposals 的特征提取上,类别分类 R-CNN 也是采用的 SVM. R-CNN 过程较为繁琐、方法更类似于传统方法、运行速度非常慢。Fast R-CNN 在很大程度上解决了这些问题。
SPPNet
在 R-CNN 中,产生的 region proposals 存在尺寸的差异,不利于后续输入到 CNN 中进行特征提取。为了解决这个问题,R-CNN 中采用的方法是:对 region proposals 进行 resize,这样使得图像出现畸变。SPPNet 对 R-CNN 中的该操作进行了改进,提出了 SPP(Spatial Pyramid Pooling)操作: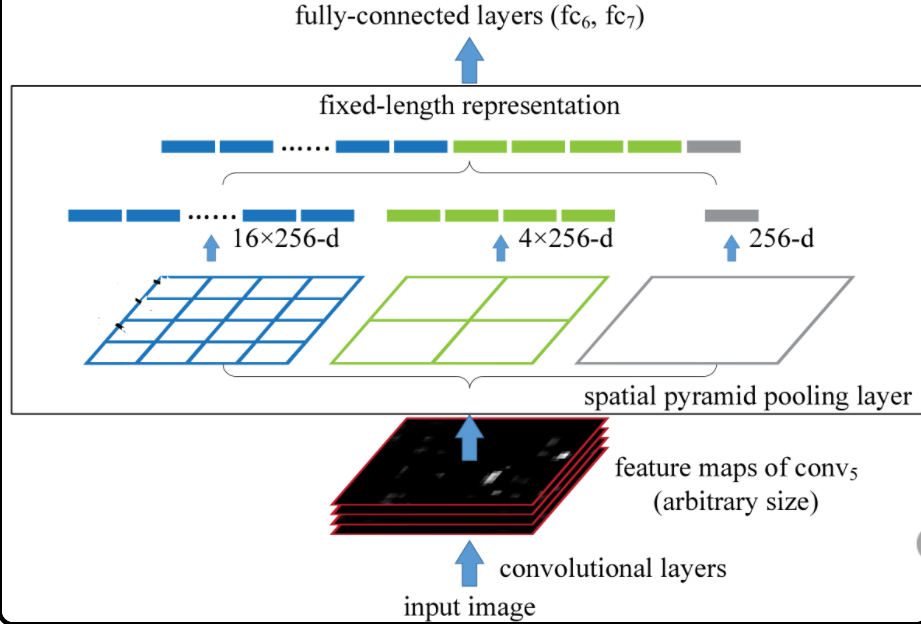
https://zhuanlan.zhihu.com/p/79888509
SPP 算子实现代码参考:https://www.cnblogs.com/marsggbo/p/8572846.html
作者将原 feature map 平均分为多尺度的网格(例如上图的
等),然后采用最大值池化,产生固定长度的特征向量。
Fast R-CNN
The Fast RCNN method has several advantages:
- Higher detection quality (mAP) than R-CNN, SPPnet
- Training is single-stage, using a multi-task loss
- Training can update all network layers
- No disk storage is required for feature caching
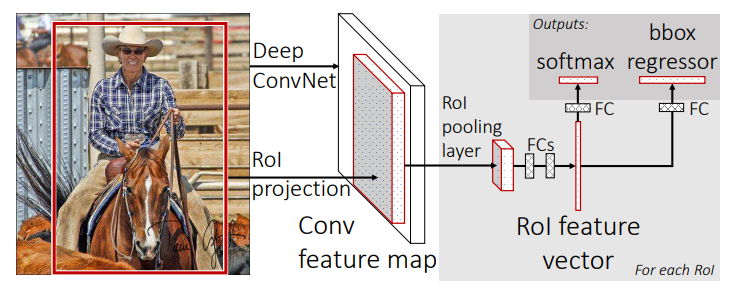
Fast R-CNN architecture. An input image and multiple regions of interest (RoIs) are input into a fully convolutional network. Each RoI is pooled into a fixed-size feature map and then mapped to a feature vector by fully connected layers (FCs). The network has two output vectors per RoI: softmax probabilities and per-class bounding-box regression offsets. The architecture is trained end-to-end with a multi-task loss.
ROI Pooling
The RoI pooling layer uses max pooling to convert the features inside any valid region of interest into a small feature map with a fixed spatial extent of  (e.g.,
(e.g.,  ), where
), where  and
and  are layer hyper-parameters that are independent of any particular RoI.
are layer hyper-parameters that are independent of any particular RoI.
设 ROI 利用  表示,其中
表示,其中  表示矩形区域的左上角坐标,
表示矩形区域的左上角坐标, 表示区域的高和宽。ROI Pooling 操作类似于SPP将 ROI 区域划分为
表示区域的高和宽。ROI Pooling 操作类似于SPP将 ROI 区域划分为  大小的网格,每个网格大小近似为
大小的网格,每个网格大小近似为  ,然后以网格为基本单位,对 ROI 进行 MaxPooling 操作,从而产生固定大小的输出。
,然后以网格为基本单位,对 ROI 进行 MaxPooling 操作,从而产生固定大小的输出。
- The network is modified to take two data inputs: a list of images and a list of RoIs in those images. 这句话如何理解?
- 值得一提的是:Fast R-CNN 的 region proposals 仍旧采用 selective search 的方法。但是所有的 region proposals 的特征只提取一遍:将 region proposals 的坐标映射到 feature map 上(SPPNet 也是采用的这种方式:计算共享)
- 貌似如何进行训练网络也是一个大问题!
training
作者采用了不同的训练方式。从论文的意思来看,貌似之前的 R-CNN 和 SPPNet训练时,都是每次在一张图片中每次训练时都是选取每张图形中的一个 ROI?(没整明白)
We propose a more efficient training method that takes advantage of feature sharing during training.
作者采用的方式是,每次选  张图片,然后在 张图片中取
张图片,然后在 张图片中取  个 ROIs(也即是每张图片取
个 ROIs(也即是每张图片取  个 ROIs)。这样的好处即是计算共享:如果每次从一张图片只去一个 ROI 进行训练,那么下一次取该图片中的其它 ROI 进行分析时将会重新对该图片进行 feature map 的计算。所以就可以在一张图中,同时取多个 ROIs 来进行模型的训练,而一张图的多个 ROIs 特征只需要进行一次 feature map 的提取。(这样做的一个可能弊端:重叠的 ROIs 具有高度的相关性,可能导致最终收敛变慢???)
个 ROIs)。这样的好处即是计算共享:如果每次从一张图片只去一个 ROI 进行训练,那么下一次取该图片中的其它 ROI 进行分析时将会重新对该图片进行 feature map 的计算。所以就可以在一张图中,同时取多个 ROIs 来进行模型的训练,而一张图的多个 ROIs 特征只需要进行一次 feature map 的提取。(这样做的一个可能弊端:重叠的 ROIs 具有高度的相关性,可能导致最终收敛变慢???)
Multi-task Loss
双任务:分类 + 检测框修正值回归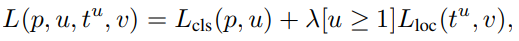
其中的  是一个权值参数,同时
是一个权值参数,同时  又实现了对背景环境的过滤。
又实现了对背景环境的过滤。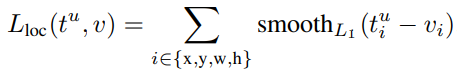
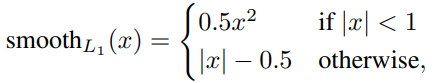
truncated SVD
对全连接层进行 SVD 分解来提高运算速度。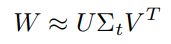

若有收获,就点个赞吧
0 人点赞
