原论文链接: 3D Convolutional Neural Networks for Human Action Recognition-2013ICML
单词汇总

介绍
C3D(3-Dimensional Convolution)是除了Two-Stream后的另外一大主流方法,但是目前来看C3D的方法得到的效果普遍比Two-Stream方法低好几个百分点。但是C3D任然是目前研究的热点,主要原因是该方法比Two-Stream方法快很多,而且基本上都是端到端的训练,网络结构更加简洁。该方法思想非常简单,图像是二维,所以使用二维的卷积核。视频是三维信息,那么可以使用三维的卷积核。所以C3D的意思是:用三维的卷积核处理视频。参考
3D 卷积
2D 卷积操作公式可以表示如下:
其中 表示位置坐标,
表示位置坐标, 表示第个feature map,
表示第个feature map, 表示第 层。
表示第 层。 表示对第
表示对第  层的 feature map 的遍历,
层的 feature map 的遍历, 表示和第
表示和第  个 feature map 相连的核在位置
个 feature map 相连的核在位置 位置处的值,
位置处的值, 表示核的高度和宽度。
表示核的高度和宽度。
上面公式是一种简化,其默认步长为1,并且未考虑边界问题。
3D 卷积操作公式可以表示如下:
其中 表示第层的第个 feature map 在位置
表示第层的第个 feature map 在位置 处的值。
处的值。 表示卷积核沿着时间轴的最大值,
表示卷积核沿着时间轴的最大值, 表示和上一层第个 feature map 相连接卷积核在
表示和上一层第个 feature map 相连接卷积核在 处的值。
处的值。
按照这个公式来,feature map 应该被理解为3维的,按照这种方式来理解也是更为方便。(每个 feature map 也即是一个 channel)(本文后面的内容与此公式并非完全符合,它没有综合不同 channel 的信息)
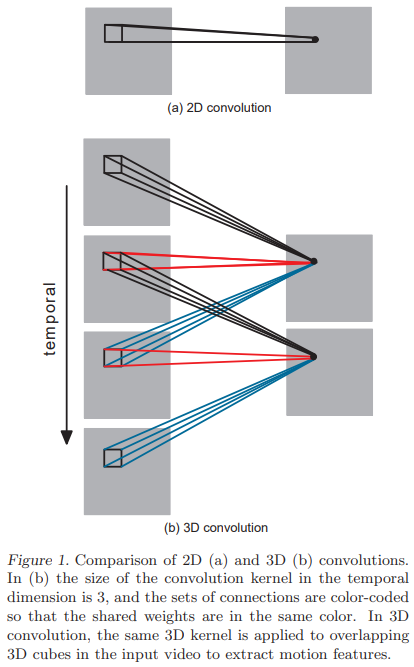
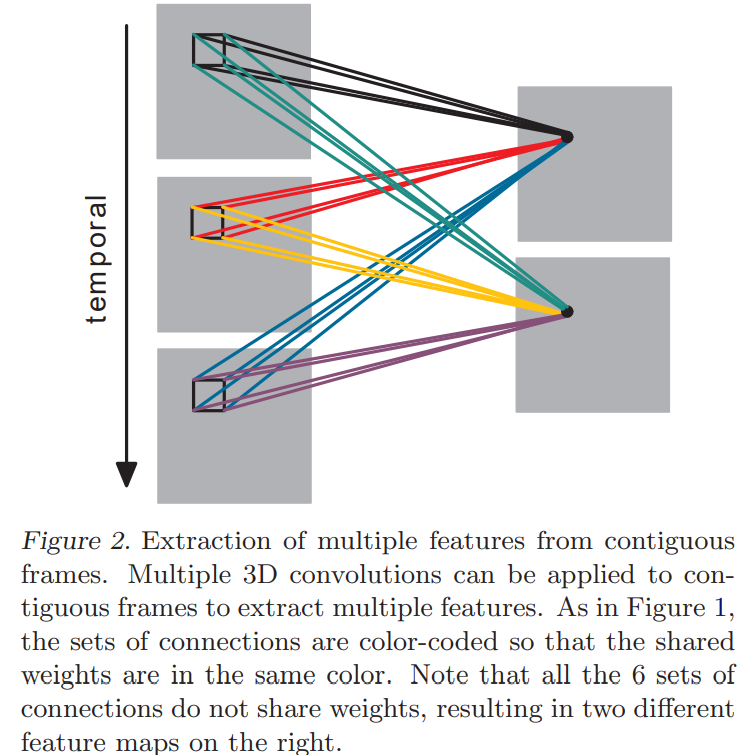
3D 卷积网络
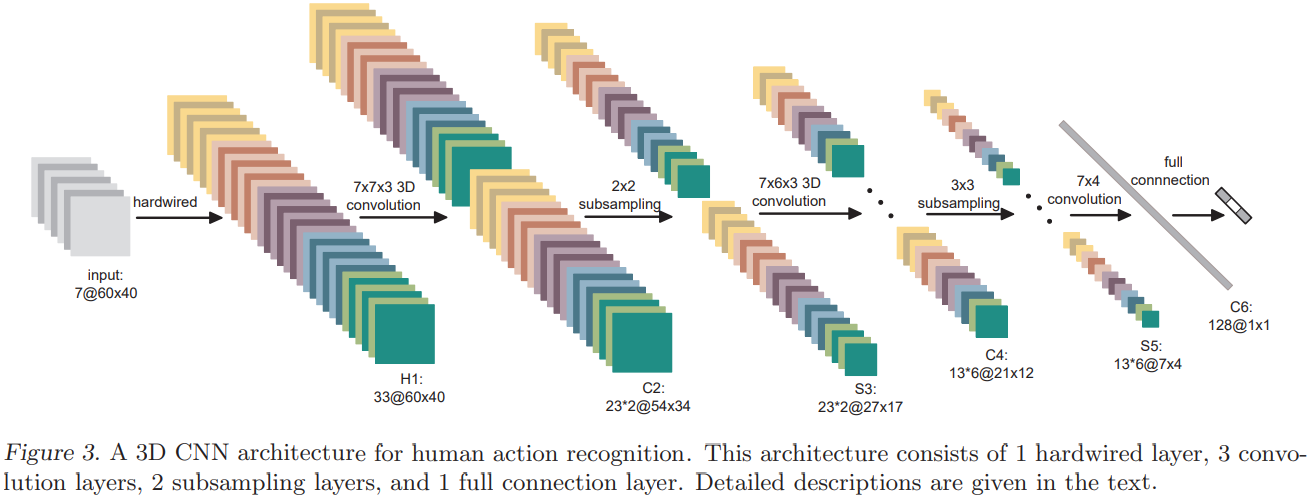
网络的第一层是一系列硬连接核,从输入(输入为三个 channels)的7帧 大小的图片,提取五个 channels 的特征(5个 channels 当然相当于 5个滤波器):灰度、方向梯度、方向梯度、方向光流、方向光流,一共33个 maps 。
大小的图片,提取五个 channels 的特征(5个 channels 当然相当于 5个滤波器):灰度、方向梯度、方向梯度、方向光流、方向光流,一共33个 maps 。
为何是33呢?看好了:灰度7张,水平梯度和竖直梯度14张,水平光流和竖直光流12张,一共33张! 关键是这个硬连接如何实现的?还有就是这个不同 channel 的 feature maps 数量不同??? 作者对不同通道分别卷积,没有融合不同通道的信息!
网络后面就是基本的卷积层堆叠啦,类比于2D卷积网络。(例如网络第二层:卷积核大小为 ,步长为
,步长为 ,值得一提的是,本文中的三维卷积是对5个 channels 分别进行3D 卷积,并没有融合不同通道的信息)但是,本文中的采样层只在空间进行采样,没有在时间轴进行采样(最大值池化)。然后就是最好的128不知道从哪里跑出来的???
,值得一提的是,本文中的三维卷积是对5个 channels 分别进行3D 卷积,并没有融合不同通道的信息)但是,本文中的采样层只在空间进行采样,没有在时间轴进行采样(最大值池化)。然后就是最好的128不知道从哪里跑出来的???
这个卷积就相当于:二维卷积对channel也进行滑动卷积。由此看来,本文的结构可以看做是介于二维卷积核三维卷积之间的卷积。按照这种方式利用框架实现网络可能并不方便……

若有收获,就点个赞吧
0 人点赞
