transformer 最核心的便是 self-attention 机制,但是 self-attention 机制计算量是与序列长度 N 成平方关系的,非常耗费计算力。故如何降低自注意力机制的计算量是非常值得研究的。
- 设序列张量 shape 为
,由 Query 和 Key 产生权值的矩阵乘法需要用到
次,产生加权序列的矩阵乘法需要用到乘法
。所以自注意力机制引入的计算量是
- 有文章指出,transformer 适用于大的数据集,在数据量较少是 CNN 等更有优势
- transformer 里面的多头机制类似于 CNN 中的多通道
- transformer,RNN 采用 LayerNorm 原因在于序列长短不一,多个样本 Norm 之后分布可能存在较大差异;所以将每个样本进行 Norm

降低时间复杂度,比较直观的方式是将  降低,而降低 N,我们比较容易想到的方式即:采样,序列分段等,而部分论文正是如此做的。在接下来的内容中,将列举一些降低时间复杂的方法:
降低,而降低 N,我们比较容易想到的方式即:采样,序列分段等,而部分论文正是如此做的。在接下来的内容中,将列举一些降低时间复杂的方法:
Paper: Transformer-XL, Blog: https://zhuanlan.zhihu.com/p/70745925
Paper: Star-transformer, Blog: https://zhuanlan.zhihu.com/p/97888995
将全连接变为稀疏连接,引入一个过渡节点来获取全局的信息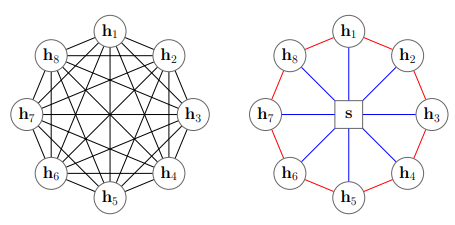

若有收获,就点个赞吧
0 人点赞
