论文原文:2D Human Pose Estimation: New Benchmark and State of the Art Analysis 作者信息:Mykhaylo Andriluka(普朗克信息学研究所,哈弗大学), Leonid Pishchulin, Peter Gehler, and Bernt Schiele 参考博客:MPII Human Pose
名词解释:
- Backbone:骨干网络,如:VGG-16,Resnet-18等
- Benchmark:性能指标,标准,规则或者在性能上很有代表的框架
Baseline:用来对照的模型(可以是自己没有进行调优的网络),并不需要最好,作为对比的基线(毕竟是Base嘛)
人体姿态估计评价指标
PCP指标(正确部位百分比)
如果两个预测的关节位置与真实肢体关节位置之间的距离小于肢体长度的一半(通常表示为
 ),则认为肢体被检测到(正确的部位)。
),则认为肢体被检测到(正确的部位)。计算检测的关键点与其对应的groundtruth间的归一化距离小于设定阈值的比例。(这种评判方式最为直观)
PCKh指标
-
OKS指标
Obeject Keypoint Similarity(通常用于多人人体姿态估计)
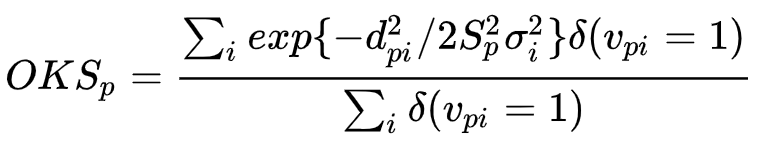
其中:
公式表示的意思是,groundtruth中第 个人和当前检测出来的行人进行运算,对比表示GroundTruth中人的id
个人和当前检测出来的行人进行运算,对比表示GroundTruth中人的id 表示id为的keypoint
表示id为的keypoint 表示真值中第个人的第个关节点和当前对比的估计人的第个关节点的欧式距离(groundtruth中每个人都会和检测出来的每个人进行求
表示真值中第个人的第个关节点和当前对比的估计人的第个关节点的欧式距离(groundtruth中每个人都会和检测出来的每个人进行求 )
) 表示groundtruth行人中id为的人的尺度因子,其值为行人检测框面积的平方根:
表示groundtruth行人中id为的人的尺度因子,其值为行人检测框面积的平方根: ,
, 为检测框的宽和高
为检测框的宽和高 表示第个关节点的方差,可以当做已知值,直接查到(这个在前面的论文中有所提到,认为标注引入的不确定性)
表示第个关节点的方差,可以当做已知值,直接查到(这个在前面的论文中有所提到,认为标注引入的不确定性) 表示groundtruth中第个人的第个关节点的可见性。其中
表示groundtruth中第个人的第个关节点的可见性。其中 表示关键点未标记,可能的原因是图片中不存在,或者不确定在哪,
表示关键点未标记,可能的原因是图片中不存在,或者不确定在哪, 表示关键点无遮挡并且已经标注,
表示关键点无遮挡并且已经标注, 表示关键点有遮挡但已标注。同样,预测的关键点有两个属性:
表示关键点有遮挡但已标注。同样,预测的关键点有两个属性: 表示未预测出,
表示未预测出, 表示预测出
表示预测出 脉冲函数
脉冲函数 这个指标启发于目标检测中的IoU指标,目的就是为了计算真值和预测人体关键点的相似度,是目前非常重要的一个指标。
- OKS是计算两个人之间的骨骼点相似度的,那一张图片中有很多的人时,该怎么计算呢?这时候就是构造一个OKS矩阵了。
假设一张图中,一共有M个人(groudtruth中),现在算法预测出了N个人,那么我们就构造一个M×N的矩阵,矩阵中的位置(i,j)代表groudtruth中的第i个人和算法预测出的第j个人的OKS相似度,找到矩阵中每一行的最大值,作为对应于第i个人的OKS相似度值。
AP指标
根据前面的OKS矩阵,已经知道了某一张图像的所有人(groundtruth中出现的)的OKS分数,现在测试集中有很多图像,每张图像又有一些人,此时该如何衡量整个算法的好坏的。这个时候就用到了AP的概念,AP就是给定一个
 ,如果当前的OKS大于,那就说明当前这个人的骨骼点成功检测出来了,并且检测对了,如果小于,则说明检测失败或者误检漏检等,因此对于所有的OKS,统计其中大于的个数,并计算其占所有OKS的比值。即假设OKS一共有100个,其中大于阈值的共有30个,那么AP值就是30/100=0.3。
,如果当前的OKS大于,那就说明当前这个人的骨骼点成功检测出来了,并且检测对了,如果小于,则说明检测失败或者误检漏检等,因此对于所有的OKS,统计其中大于的个数,并计算其占所有OKS的比值。即假设OKS一共有100个,其中大于阈值的共有30个,那么AP值就是30/100=0.3。
mAP指标
具体计算方法就是给定不同的阈值t,计算不同阈值情况下对应的AP,然后求个均值就ok了。
论文内容简介
主要是提出了一个非常经典的数据集MPII,然后提出了一些量化的评价指标(Benchmark)。
更为复杂的数据集被提出来意味着:能够更加公平地来评判前面提出的网络的优劣!
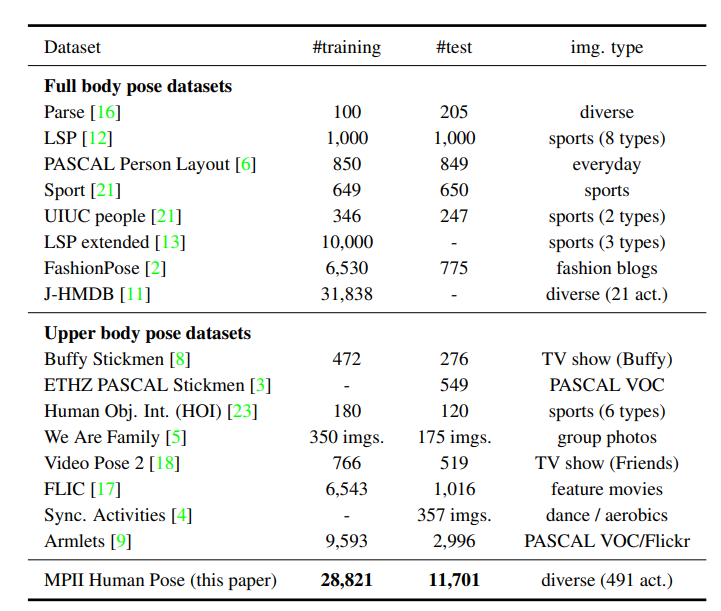
当时的一些比较主流的与人体姿态估计相关的数据集。
MPII采集的数据分为两个层次进行分类,第一个层次分大类(例如“Sports”等),第二个层次分小类(例如“Play football”等)。这种分类的好处:使得研究者可以从更多的角度或者说是层次来分析所提方法的性能。
由于该数据集覆盖的层次结构,该数据集中的图像代表了人类姿态的多样性,克服了以前的集合的主要局限性之一。对比Fig 2(b)和(c)可以看到,原来的数据集“Armlets”与(a)更加类似(大多数的动作都和正常直立类似),也就是其多样性相对较差;然而从(c)可以看到,关节点的分布更加多样化,所以其表征能力更强。
收集数据集时,应该要考虑到多样性问题,这关系到模型的泛化能力(思考:对于视频数据的采样又应该遵循哪些要求呢?)。当然,样本的分布特点还是需要更加具体的任务而定。
值得注意的一些点:
- Next, we annotate all people present in the collected images, but ignore dense people crowds in which significant number of people are almost fully occluded. Following this procedure we collect images of 40, 522 people.
- Images from the same video are either all in the training or all in the test set.(在患者步态视频分析中,切段之后,我们也是采用的这种方式)
数据标注: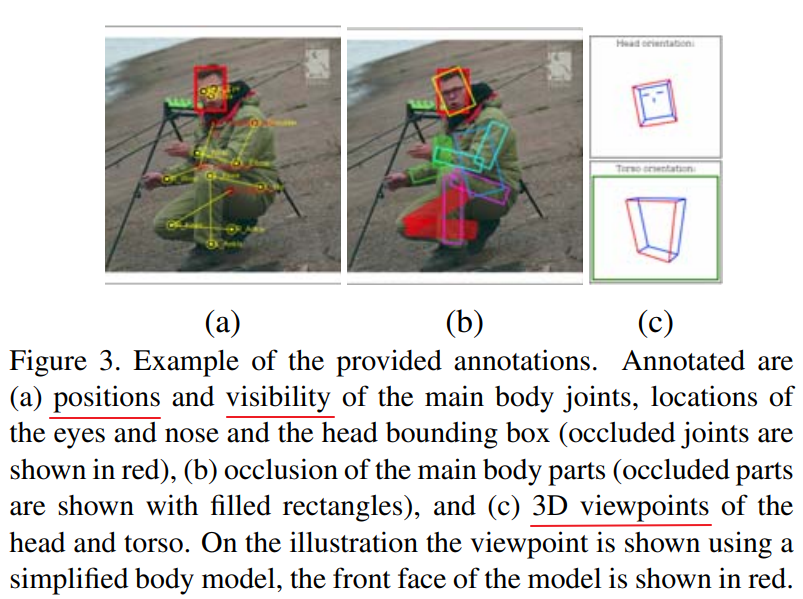
We provide rich annotations for the collected images, an example can be seen in Fig. 3. Annotated are the body joints, 3D viewpoint of the head and torso, and position of the eyes and nose. Additionally for all body joints and parts visibility is annotated.
作者总结并分析了几种对人体姿态估计产生影响的因素:Pose Complexity,ViewPoint,Occlusion,Part Length,Truncation and so on.
- Pose Complexity是对于准确率影响最大的因素
- 其次是ViewPoint对准确率的影响:正面或者接近正面的图像准确率最高
- We observe a large drop in performance for backward facing people when performance is measured in “person centric” manner, which suggests that large portion of incorrect pose estimates for backward views is due to incorrect matching of left/right limbs.(CapsuleNet利用向量表示来体现空间约束)
- Truncation是影响较小的因素:测试时,对于截断的关节点没有进行统计
 让模型对是否阶段进行判断
让模型对是否阶段进行判断
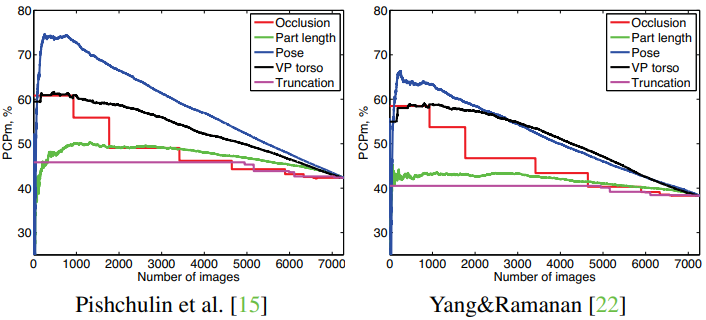
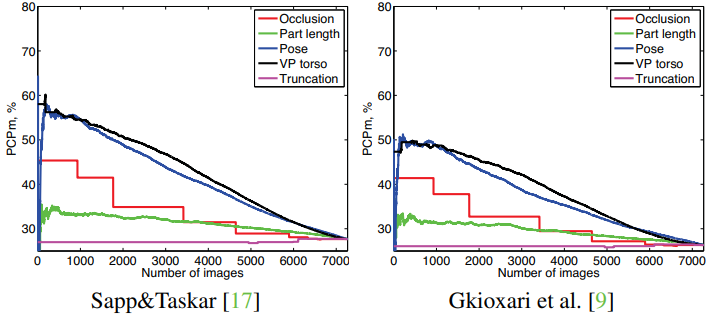
Figure 4. Performance (PCPm) as a function of the five complexity measures.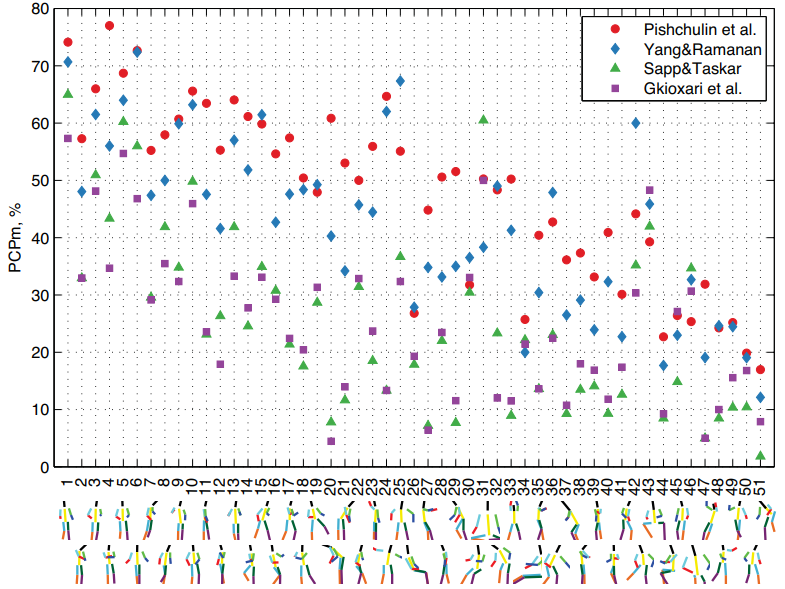
Figure 5. Performance (PCPm) on images clustered by full body pose. Clusters are ordered by increasing mean pose complexity and representatives are shown beneath. Results using upper body and lower body clusters can be found in supplementary material.
上图,作者对姿态进行聚类(例如k-means等),然后选取50类,按照复杂度进行排序得到了上面的图:姿态复杂度越高,模型的结果越差。
其它内容分析了动作类型对模型效果的影响,关节长度对模型影响等等…内容都是类似的

若有收获,就点个赞吧
0 人点赞
