论文原文:https://www.sciencedirect.com/science/article/pii/S0167639320302466 发表时间:2020-9-1
很多疾病都会对患者的语言表达能力产生影响,比如帕金森、唇裂等。这些疾病导致患者说话过程中相对于正常人来说更易表现出口齿不清、语调混乱等。所以,通过对语言特征的提取和分析,可以将患者和正常人进行区分。
本文采取的方法
通过编码器和解码器来进行特征提取,以 DNN,SVM 作为特征分类器。编码器事实上就是一个特征提取器,也可以将其看做一个数据压缩器。解码器以编码器特征为输入,从特征还原输入数据。同时训练编码器和解码器,更能够提取到能够充分表征输入数据的特征。
数据
这里的数据涉及到两个部分:一部分是训练 Encoder-Decoder 的数据,另一部分是进行分类的数据。
其中 CIEMPIESS corpus was used to train the convolutional and recurrent autoencoders.
进行分类的 CLP Data 和 PD Data 来自另外两个数据库。
数据预处理
从一维的语音信号中得到 Mel 频谱,以 Mel 谱图作为后续网络的输入。(将一维信号转为了二维,结合了时域和频域的信息)
编码器和解码器
基于 CNN 的编码解码器和基于 RNN 的编码解码器。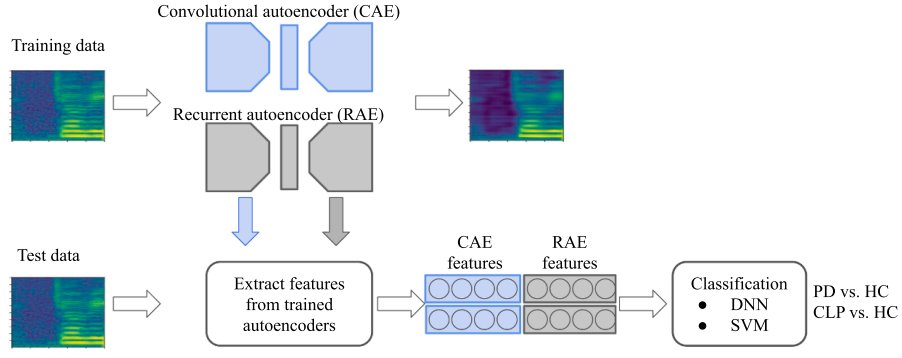
CNN 编码解码器
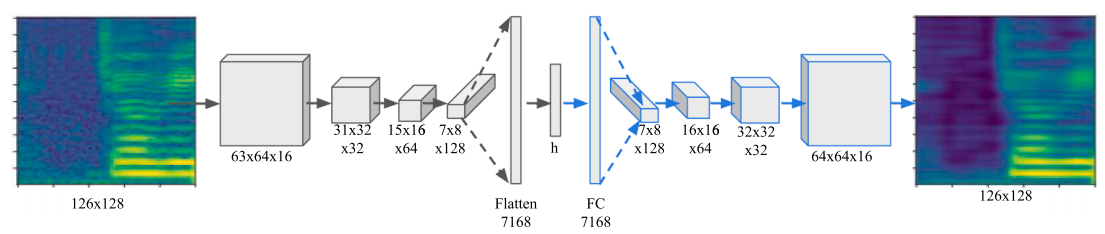
类似于图像分割的架构:首先不断进行卷积,增加 channel 数量的同时,降低 feature map 的 size;在得到特征向量
之后,不断进行反卷积(上采样)恢复分辨率,最终得到原图的估计。
CNN 编码器
class CAEenc(nn.Module):def __init__(self, dim=256, nc=1):super().__init__()self.conv1=nn.Conv2d(nc, 16, kernel_size=3, stride=1, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(16)self.pool=nn.MaxPool2d((2, 2))self.conv2=nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(32)self.conv3=nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1, bias=False)self.bn3 = nn.BatchNorm2d(64)self.conv4=nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1, bias=False)self.bn4 = nn.BatchNorm2d(128)self.linear = nn.Linear(128*8*7, dim)def forward(self, x):x =F.leaky_relu((self.bn1(self.pool(self.conv1(x)))))x =F.leaky_relu((self.bn2(self.pool(self.conv2(x)))))x =F.leaky_relu((self.bn3(self.pool(self.conv3(x)))))x =F.leaky_relu((self.bn4(self.pool(self.conv4(x)))))x = x.view(x.size(0), -1)x = self.linear(x)return x
CNN 解码器
class CAEdec(nn.Module):def __init__(self, dim=256, nc=1):super().__init__()self.conv1=nn.ConvTranspose2d(128, 64, kernel_size=3, stride=1, padding=(1,0), bias=False)self.bn1 = nn.BatchNorm2d(64)self.conv2=nn.ConvTranspose2d(64, 32, kernel_size=3, stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(32)self.conv3=nn.ConvTranspose2d(32, 16, kernel_size=3, stride=1, padding=1, bias=False)self.bn3 = nn.BatchNorm2d(16)self.conv4=nn.ConvTranspose2d(16, nc, kernel_size=3, stride=1, padding=1, bias=False)self.linear = nn.Linear(dim,128*8*7)def forward(self, x):x = self.linear(x)x = x.view(x.size(0), 128, 8, 7)x = F.interpolate(x, scale_factor=2)x =F.leaky_relu((self.bn1(self.conv1(x))))x = F.interpolate(x, scale_factor=2)x =F.leaky_relu((self.bn2(self.conv2(x))))x = F.interpolate(x, scale_factor=2)x =F.leaky_relu((self.bn3(self.conv3(x))))x = F.interpolate(x, scale_factor=2)x =F.sigmoid((self.conv4(x)))return x[:,:,:,0:-2]
上采样函数采用的默认的“最近邻插值”方法。
RNN 编码解码器
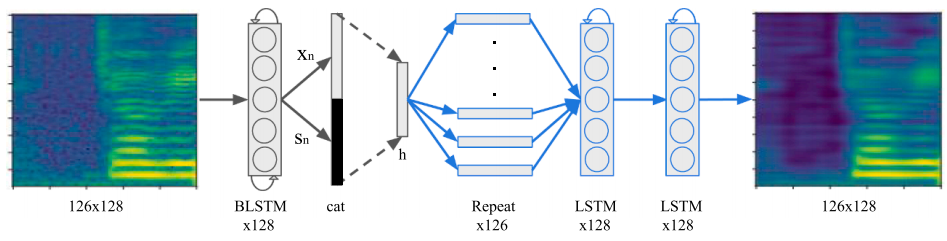
利用 LSTM 进行特征提取时,将 last time step 的输出 以及 隐藏层状态 进行 cat 之后通过一个全连接层之后的
作为特征。
RNN 编码器
class RAEenc(nn.Module):def __init__(self, dim=32):# input: batch * nc(1) * input_size(128) * seq_len(126)super().__init__()self.lstm1=nn.LSTM(128, 64, batch_first=True, bidirectional=True)self.linear = nn.Linear(256, dim)def forward(self, x):x=x[:,0,:,:]x=x.permute(0,2,1) # batch * seq_len * input_sizex,(hn,cn)=self.lstm1(x)#print(hn.size()) # hn: b * (nl * nd) * hshn=hn.permute(1,0,2) # hn: b * hs(64) * 2 cn: b * hs(64) * 2 x: b * seq_len * hs(64) * 2#print(hn.size())x=x[:,-1,:]hn=hn.contiguous().view(hn.size(0),-1)x = x.view(x.size(0), -1)x2=torch.cat((x,hn),1)x = F.leaky_relu(self.linear(x2))
就是一个 LSTM 加一个线性层
RNN 解码器
class RAEdec(nn.Module):def __init__(self, dim=32, seq_len=126):super().__init__()self.lstm = nn.LSTM(dim, 128, batch_first=True, num_layers=2)self.seq_len=seq_lendef forward(self, x):x = torch.cat([x] * self.seq_len, 1).view(x.size(0), self.seq_len, x.size(1))x, (h,c)=self.lstm(x)x=x.permute(0,2,1)x=x.view(x.size(0), 1, x.size(1), x.size(2))return x
编码器输出的特征重复 126 次(与输入数据对应:126 个 time steps) 通过一个 LSTM 进行一个维度变换,将 32 维向量变为 128 维。再结合 126 个 time step 的输出,组合成原来的 Mel 频谱图。
编码器和解码器的训练
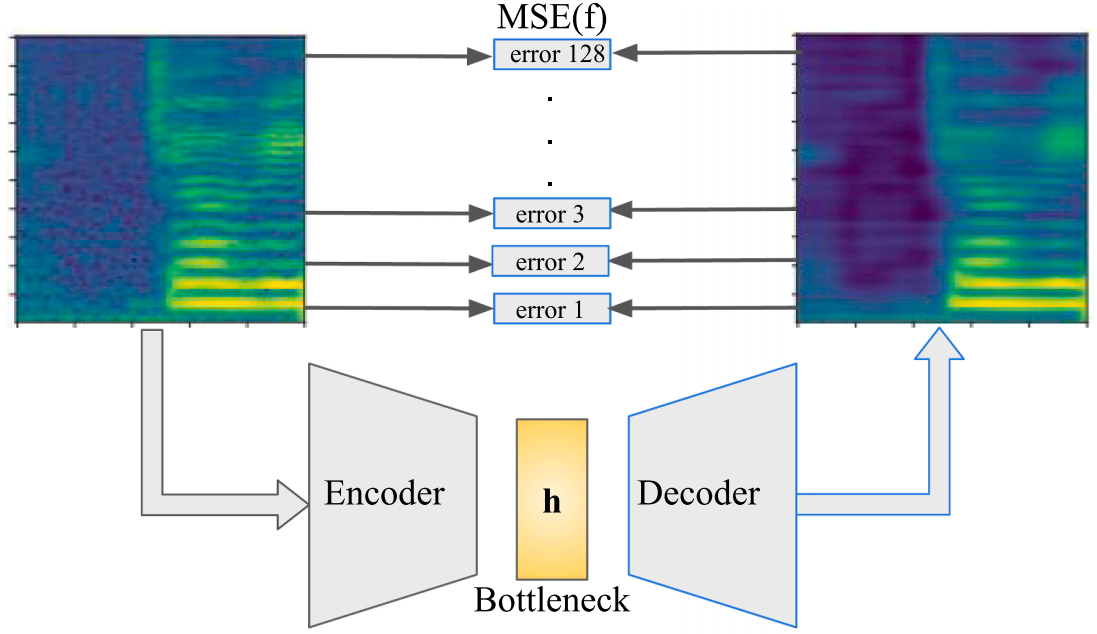
每一行表示的指定频率的信号随时间的分布情况;每一列表示的是每一个时刻不同频率信号的分布情况。 所以每一行产生的 error 是每一种频率信号的恢复的误差。
以 MSE 函数为损失函数,来度量输入数据和恢复数据之间的误差。训练目标:最小化原始数据和恢复数据之间的误差  特征 h 能够充分表征原始数据。
特征 h 能够充分表征原始数据。
if valid_loss <= valid_loss_min:print('Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(valid_loss_min,valid_loss))torch.save(model.state_dict(), PATH+'/'+str(BOTTLE_SIZE)+'_CAE.pt')
保存的模型,是在验证集上表现最好的结果。(我认为这种方式在样本量比较少的的情况下是不可取的;不具有代表性)
实验结果
重构误差分析
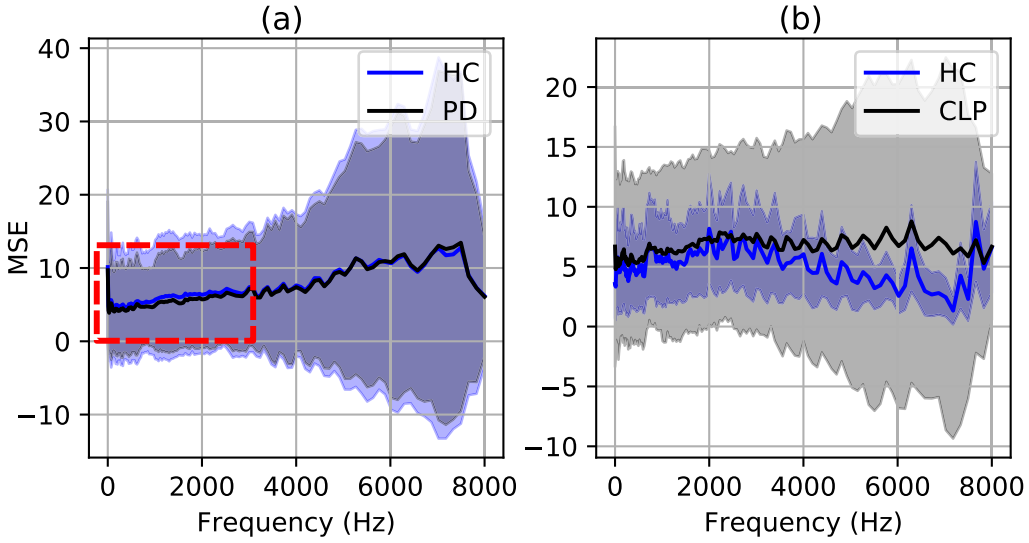
CAE 重构误差
RAE 重构误差
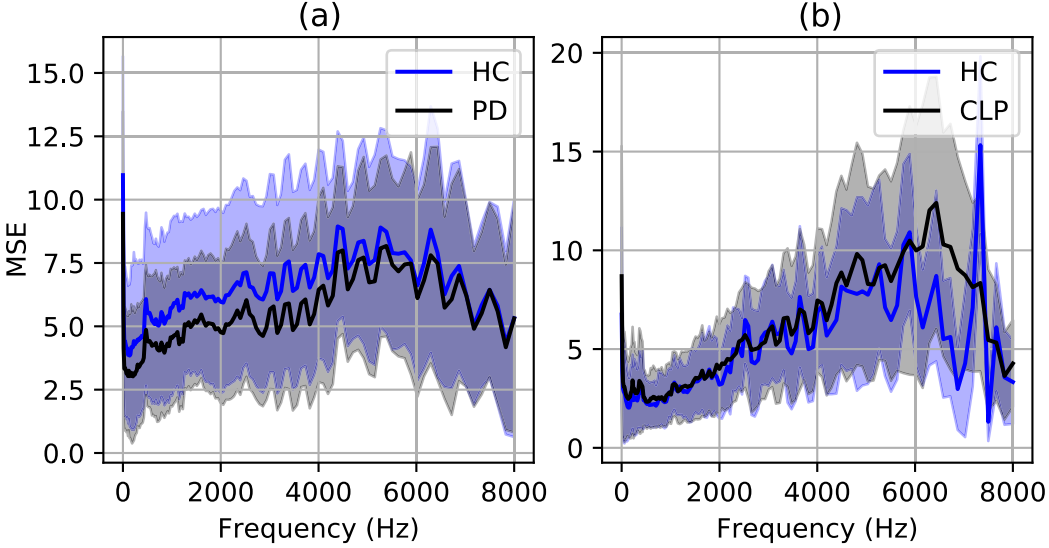
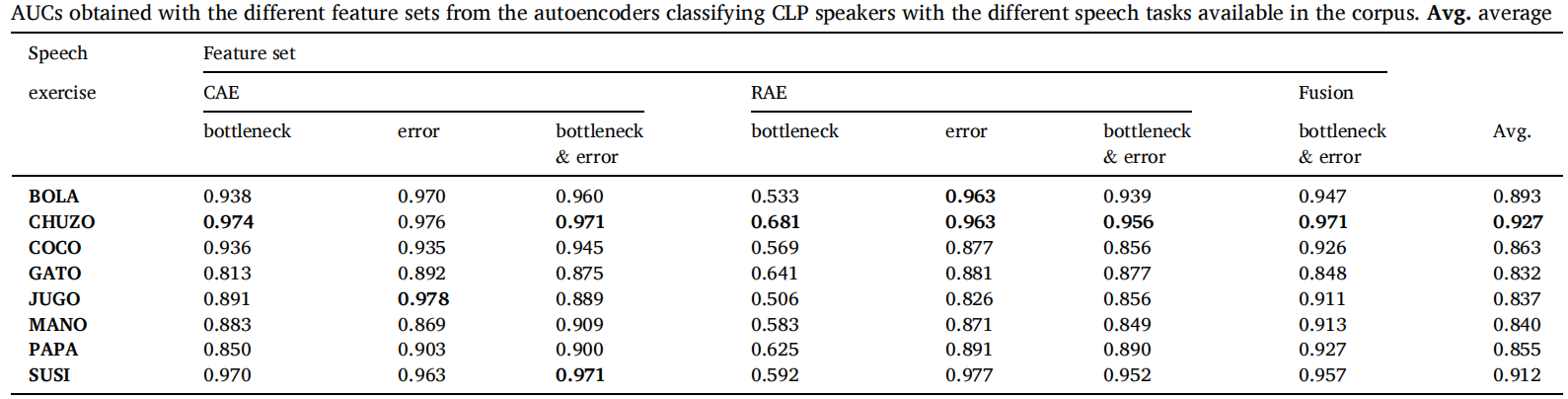
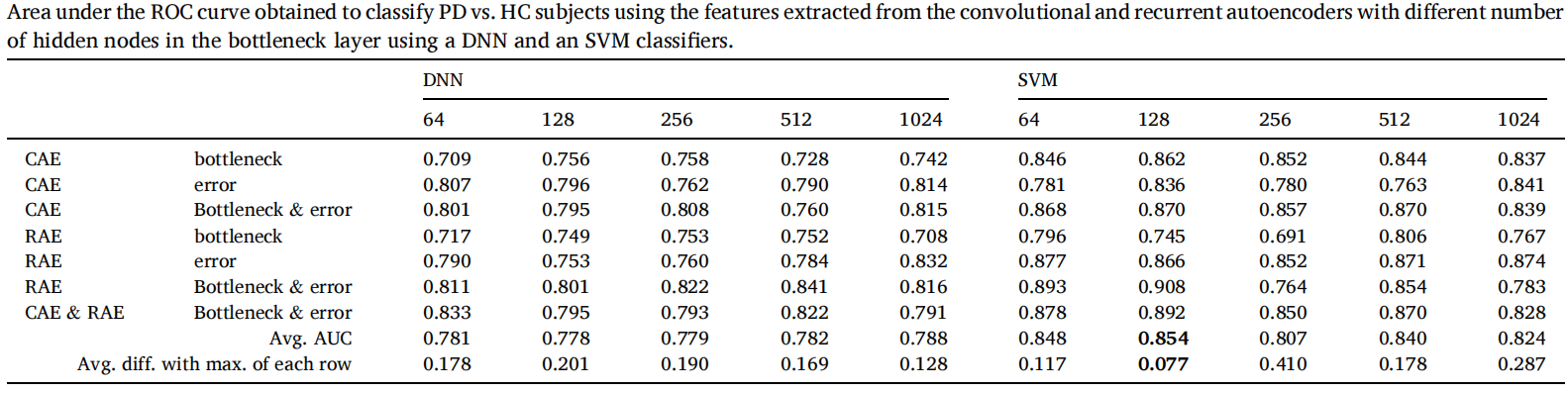
重构误差在 HC、CLP、PD上曲线是不同的(并且对 CAE 和 RAE 来说也是不同的)所以可以作为类别划分的信息。
结果统计
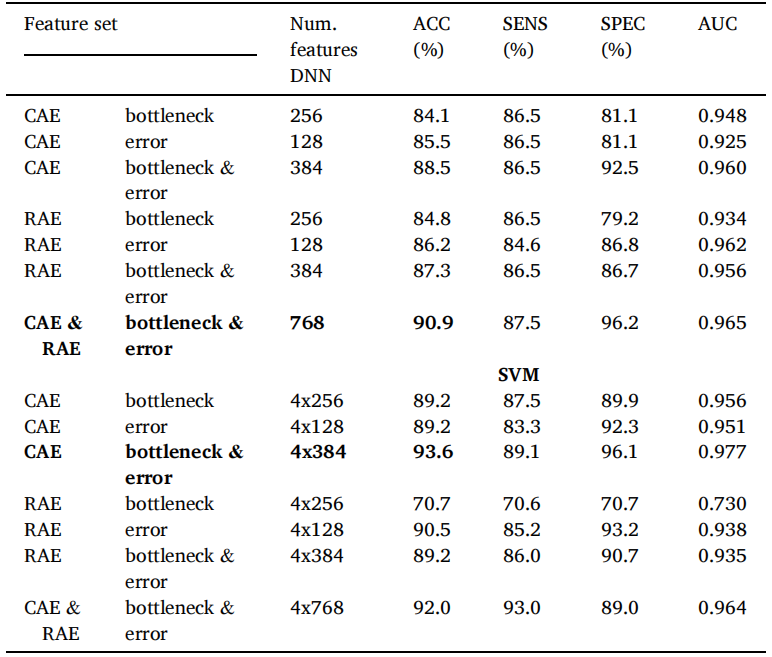
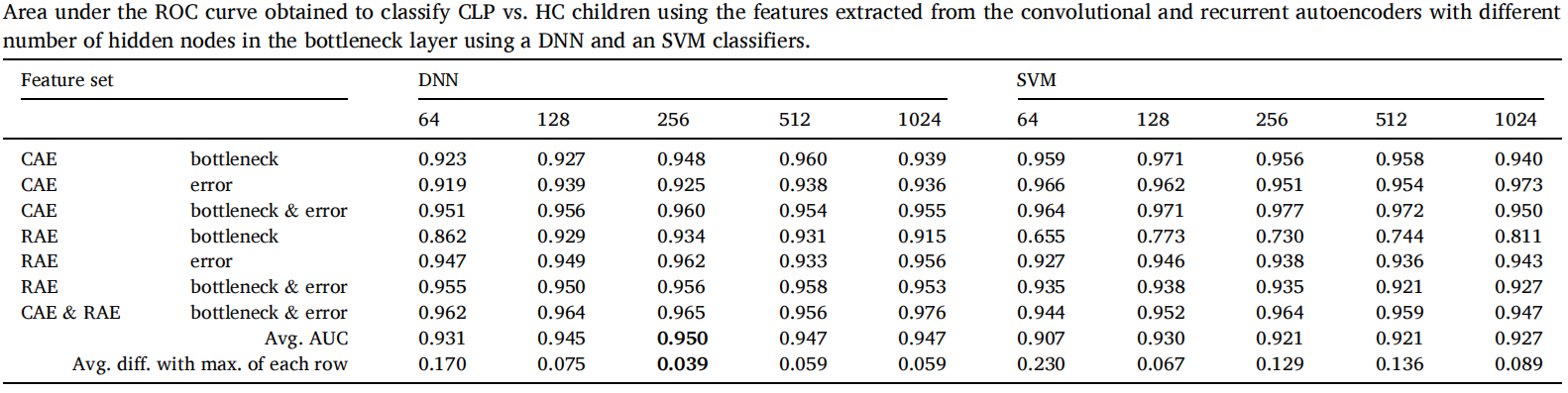

若有收获,就点个赞吧
0 人点赞
