单词
interleaving: 交叉frontier: 前沿integrating: 集成incorporates: 包含了recalibration: 校准depicted: 描述aggregation: 聚合agnostic: 不可知论的accumulated: 积累regulating: 调节cardinality: 基数Algorithmic: 算法forgo: 放弃tackle: 解决viable: 可行的utility: 实用subsequent: 后续的exploiting: 利用mitigate: 减轻sophisticated: 复杂的criteria: 标准non mutually exclusive:非相互排斥ablation: 消融robust: 健壮的empirical: 经验
论文
提升CNN能力:
- 空间信息的表征能力;
- channel之间关系的处理;
论文思想

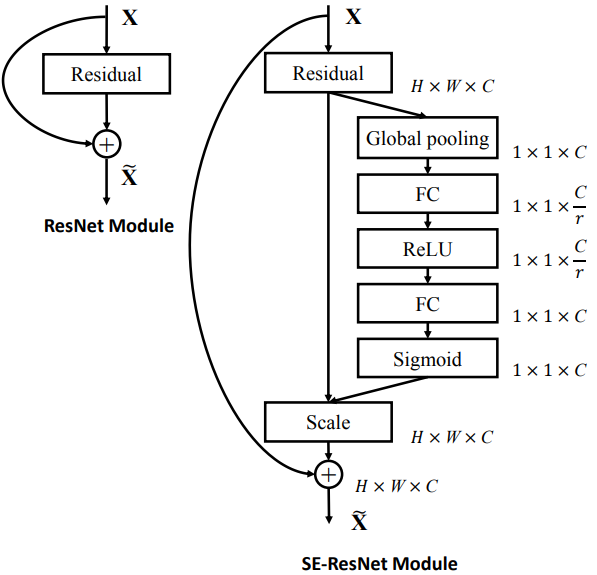
上图展示的是SE-Block,通过堆叠该Block可以构造SE network。(貌似有点像LRN)
- 对于任意将输入
 转为feature maps
转为feature maps  的转换
的转换 ,
, 首先将会被进行压缩操作
首先将会被进行压缩操作 ;
; - 压缩操作实现将每个channel的feature map(
 )信息进行聚合,产生channel 描述符(显然就是一个数字);
)信息进行聚合,产生channel 描述符(显然就是一个数字); - 然后进行激发操作
 ,其采用简单的自选门机制,以嵌入信息(就是上一个操作的输出)作为输入,产生每个通道的调制权值;
,其采用简单的自选门机制,以嵌入信息(就是上一个操作的输出)作为输入,产生每个通道的调制权值; -
转换函数
Squeeze压缩
采用global average pooling:
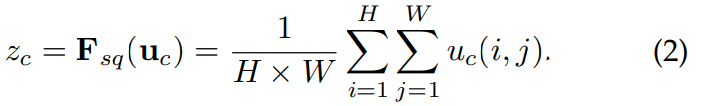
其中: 表示的是输出特征第
表示的是输出特征第 个channel对应的feature map,
个channel对应的feature map, 表示压缩后的channel descriptor。
表示压缩后的channel descriptor。
Excitation激发
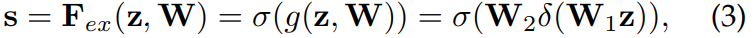
其中: 表示Relu激活函数,
表示Relu激活函数, ,
, 。实现方式:利用两个全连接层产生botttleneck(第一个FC会使维度降低r倍,第二个FC会使维度增加回来),从而降低模型复杂度,增强模型泛化能力。
。实现方式:利用两个全连接层产生botttleneck(第一个FC会使维度降低r倍,第二个FC会使维度增加回来),从而降低模型复杂度,增强模型泛化能力。
激发之后,将会将权重分配到中,产生 :
: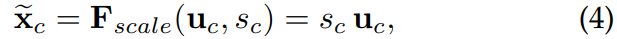
其中粗体表示向量,细体表示标量。 表示的是channel-wise的乘法操作。
表示的是channel-wise的乘法操作。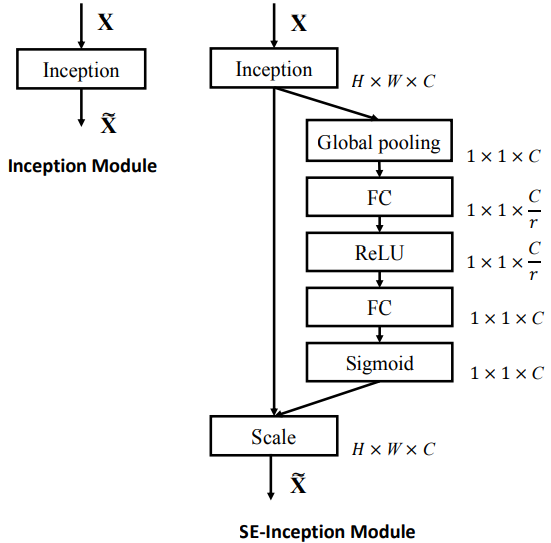
优点
能够提升网络性能;
-
代码实现
import torch.nn as nnclass SE_Block(nn.Module):def __init__(self, ch_in, reduction=16):super(SE_Block, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1) # 全局自适应池化self.fc = nn.Sequential(nn.Linear(ch_in, ch_in // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(ch_in // reduction, ch_in, bias=False),nn.Sigmoid())def forward(self, x):b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1, 1)return x * y.expand_as(x)
 ;
;

若有收获,就点个赞吧
0 人点赞
