Efficient Training of Audio Transformers with Patchout
采用语音频谱作为输入,长音就对应长频谱呗!频谱采用 vit 技术进行特征提取,为了降低时序计算的复杂度(二次时间复杂度的 self attention 计算)采用随机 drop patches 的方式。最终在 audioSet 数据集上得到 SOTA 结果。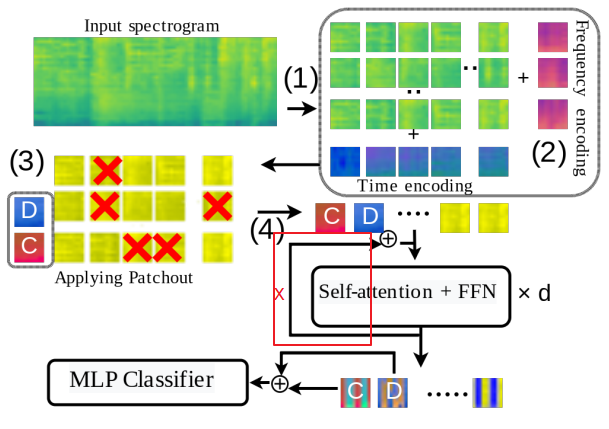
图中的 X 回路应该不存在。

若有收获,就点个赞吧
0 人点赞
Efficient Training of Audio Transformers with Patchout
采用语音频谱作为输入,长音就对应长频谱呗!频谱采用 vit 技术进行特征提取,为了降低时序计算的复杂度(二次时间复杂度的 self attention 计算)采用随机 drop patches 的方式。最终在 audioSet 数据集上得到 SOTA 结果。
图中的 X 回路应该不存在。
若有收获,就点个赞吧
0 人点赞
让时间为你证明
