单词参考

神经网络的浪潮到目前为止已经有三波了,其中最成功的是从2000开始的第三波浪潮,其成功的关键在于:大的数据集、高性能的计算机(GPU)。值得一提的是,事实上基本上所有神经网络的基本想法在第二波浪潮就已经被发展起来了,当时只是缺少了必要的条件。
神经网络灵感来自于人的大脑的神经网络,但事实上二者存在非常大的区别,人大脑的研究一直是神经科学研究中的重大挑战。当然,我们对人神经网络的简化抽象就可以实现非常强大的功能,这也显示着对人神经网络研究的巨大价值。
在深度学习的学习过程中,不应该只追求学习最新的知识,过去的老方法也应该被掌握!
深度学习成果案例
深度学习在图形分类、目标检测、边缘检测、语义分割、遮挡检测(具有边界所有权的边缘检测)、对称轴检测、人体关节检测、人体分割、双目立体视觉、3维人体姿态估计(基于单张图片)、场景分类等都取得了很好的效果。虽然,他们看似成果,但是有如下三个限制:
- 网络是为特定的视觉任务而设计的。为了解决这个问题呢,出现了迁移学习:利用针对某个任务的网络在另一个相似任务的标注数据集上面进行训练,从而完成另一个任务。
网络在基准数据集上表现良好,但在数据集之外的真实世界图像上可能会失败。现实世界如果用图像表示那么它将是一个无穷大的集合,是不可能用某个数据集来表示的;再加上深度网络的泛化能力是非常有限的,这使得深度网络在有限数据集上训练之后很可能在现实世界无效。
值得注意的是,我们的数据集来源于现实世界,但是它不能很好地表征现实世界的分布,它是有自己的“偏见”的。也即是说我们很难在采样时进行合理的采样。由于数据集的“偏见”,很多研究者都会利用这个“偏见”来提升自己模型的准确率。
几乎所有的网络都需要被标注的数据来进行训练和测试。解决方法:无监督学习、计算机合成数据等。
理解神经网络
事实上,理解深度网络非常困难,我们无法得知网络内部到底在干什么。但是通过理论证明了,多层感知机能够拟合任何函数。
我们对于CNN的理解,目前大概是从它每层到底提取了什么特征来进行:最低层提取的是局部纹理,越往高层感受野越大,那么其提供的特征更具全局性。
有研究表明,CNN在建模纯由几何指定的视觉属性时效果较差,尤其是输入图像的边界存在与否由二值化的纹理组成时。Deep Nets和生物视觉
DeepNets的挑战
监督学习:
首先是DeepNets需要大量标注数据学习的问题。“迁移学习”可以在一定程度上解决这个问题,使得少量数据就可以取得很好的效果。比如最开始DeepNets在PASCAL数据集上面做目标检测,不能成功,但是将在ImageNet数据集上面训练的模型拿到PASCAL进行训练可以解决PASCAL数据集过小的问题!除此之外,弱监督和非监督方式同样可以解决数据标注的麻烦。
- 对抗样本(对抗攻击):
很多时候,我们对原图像进行细微的改变,可能就会导致DeepNets的分类错误。其部分原因来自于,训练集有限,只包括所有可能图像的极小部分,所有存在大量以任意方式接近训练集数据的图像,从而有可能导致分类错误。(解释不太有说服力)
为了解决对抗样本的问题,一种方法是将对抗样本作为训练集中的样本进行学习,从而产生“对抗学习”;另一种方法是通过在图像中引入微小随机振动,利用“攻击图像”非常不稳定的假设,因此小的随机扰动可以防御它们。
- 上下文过于敏感
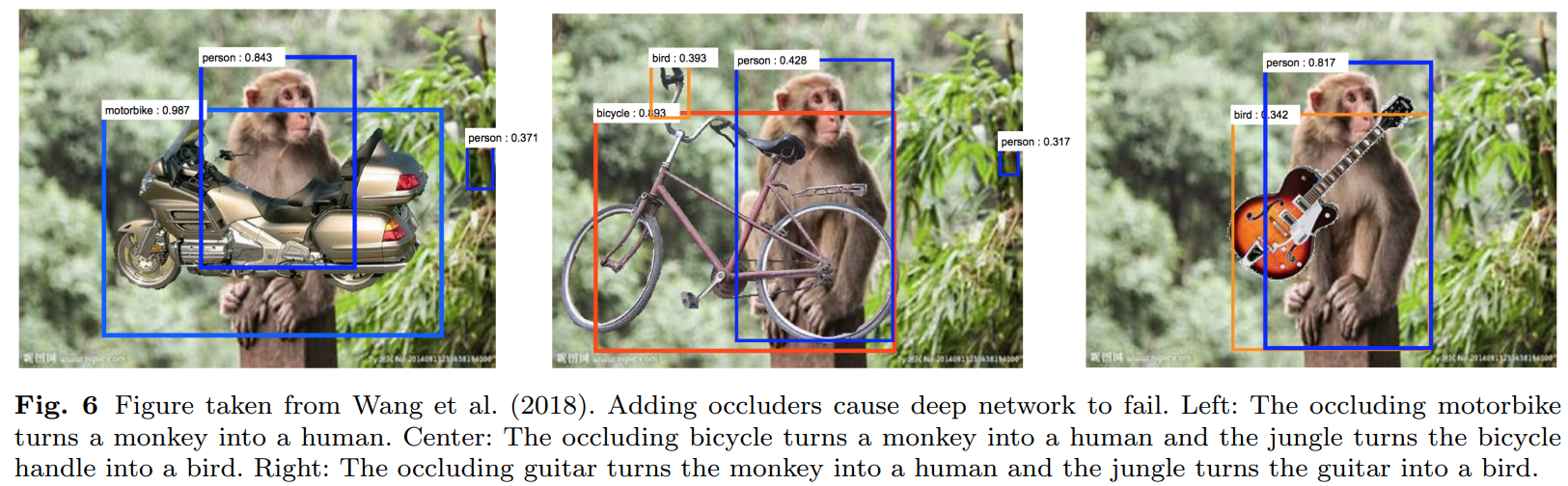
上图,将猴子前面放置一些其它与人关系很密切的事物之后,它将猴子识别成了人!这说明,网络在学习的过程中,对一个物体类别的判断不仅仅是根据物体本身,还和物体所在的场景相关!
对于上下文的过度敏感,本文认为其主要原因是数据集的有限性
人工合成数据集。 事实上网络是非常笨的,如果数据集只包括某一个角度的信息,对于其它角度的数据,网络泛化能力极弱。 (感觉还是网络提取的信息不太对头,关键是这个目标检测输入数据本身特性导致网络在学习过程中,很容易学到上下文信息。反过来看,由于网络容易学到上下文信息,那么何不加以利用呢,其利弊应该从具体任务出发。)

对于以上的问题,“组合”可能是一个好的解决方案。我们认为:复杂结构是按照一套语法规则由更基本的子结构分层组成的,而这些子结构和语法是可以通过有限的数据进行学习的。 组合模型
组合模型
这是一个普遍的原则,可以诗意地描述为:”我们信仰世界是可知的,人们可以随意分解,理解,重组事物”。 生成对抗网络可用于产生图像?(Yes!GAN的一个用途)

若有收获,就点个赞吧
0 人点赞
