论文原文:https://arxiv.org/pdf/1407.3399.pdf 作者信息:Xianjie Chen, Alan Yuille 博客参考:https://blog.csdn.net/u014625530/article/details/85385773 代码参考:https://github.com/chuxiaoselena/Aperture
出发点
In this paper, we present a graphical model with image dependent pairwise relations (IDPRs). 作者希望的方法是通过对局部区域进行分析,既能够预测每个关节点的位置,又能够根据已有关节点预测邻居节点的相对位置。这样就能够在关节点之间引入联系。This gives stronger pairwise terms because data independent relations are typically either too loose to be helpful or too strict to model highly variable poses.
Our approach requires us to have a method that can extract information about pairwise part relations, as well as part presence, from local image patches. 为了达到这个目的,作者训练了一个DCNN网络,在估计关节点位置的同时,估计关节点之间的关系。
模型
The Graphical Model and its Variables
本文利用一张图来表示人体: ,其中的
,其中的 表示节点,
表示节点, 表示边。为简单起见,作者把图构造成
表示边。为简单起见,作者把图构造成  个节点的树,其中
个节点的树,其中  。关节点的位置表示为
。关节点的位置表示为 ,其中
,其中 表示关节点
表示关节点 的像素位置,其中
的像素位置,其中 。对于图中的边
。对于图中的边 ,作者指定一个由
,作者指定一个由  索引的离散空间关系集,它对应于不同空间关系的混合(如 Fig 1所示,相对于为关节之间的关系建立了模板)。那么关节点的空间关系组成的集合为
索引的离散空间关系集,它对应于不同空间关系的混合(如 Fig 1所示,相对于为关节之间的关系建立了模板)。那么关节点的空间关系组成的集合为 。图像记为
。图像记为 ,定义 score function
,定义 score function  。
。
Unary Terms: The unary terms give local evidence for part  to lie at location
to lie at location  and is based on the local image patch
and is based on the local image patch  . They are of form:
. They are of form: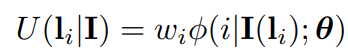
where  is the (scalar-valued) appearance term with
is the (scalar-valued) appearance term with  as its parameters (specified in the next section), and
as its parameters (specified in the next section), and  is a scalar weight parameter.
is a scalar weight parameter.
Image Dependent Pairwise Relational (IDPR) Terms: 这里的目的是为了通过相邻的关节点 以及局部图像信息来大致预测邻居的相对空间位置。在作者的模型中,部件 和
以及局部图像信息来大致预测邻居的相对空间位置。在作者的模型中,部件 和  的相对位置分为几种类型
的相对位置分为几种类型  (即不同关系的混合,或者前面所说的模板)包含对应的平均相对位置
(即不同关系的混合,或者前面所说的模板)包含对应的平均相对位置 加上由标准二次曲线建模的小的形变量 。更正式地说,每条边的成对关系得分 由下式给出:
加上由标准二次曲线建模的小的形变量 。更正式地说,每条边的成对关系得分 由下式给出: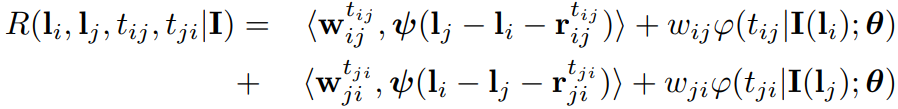
其中: 是标准的二次形变特征(
是标准的二次形变特征( 事实上就是真实的相对位置与统计平均相对位置之间的差异量),
事实上就是真实的相对位置与统计平均相对位置之间的差异量), 是图像相关成对关系(IDPR)项,其中
是图像相关成对关系(IDPR)项,其中 是参数,
是参数, 是权重参数,符号
是权重参数,符号  表示点积,加粗表示向量。
表示点积,加粗表示向量。
The Full Score: 最终得分函数为: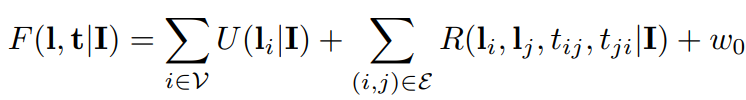
上面的过程没怎么看明白
Image Dependent Terms and DCNNs
appearance terms and IDPR terms都取决于图像块,也就是说,图像块给出了关节点存在的置信度以及它与它邻居之间的关系。这就需要模型学习一个条件分布,也就是在图像块的条件下,关节点存在以及其与其邻居之间的关系。为了指定这种分布,作者更加详细地定义了状态空间。
定义随机变量 来表示哪个关节点存在,当
来表示哪个关节点存在,当 表示关节点存在,当
表示关节点存在,当 表示无关节点存在。定义随机变量
表示无关节点存在。定义随机变量 ,其表决定了关节点的空间关系,并从
,其表决定了关节点的空间关系,并从 中取值。如果有一个邻居,那么
中取值。如果有一个邻居,那么 ,如果其有两个关节点
,如果其有两个关节点 那么
那么 ,如果,那么
,如果,那么 。所以总的状态空间定义为:
。所以总的状态空间定义为: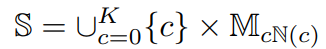
这种条件概率分布 ,采用DCNN来进行学习。此分布信息和前面定义的 appearance terms 以及 IDPR terms 对应起来:
,采用DCNN来进行学习。此分布信息和前面定义的 appearance terms 以及 IDPR terms 对应起来: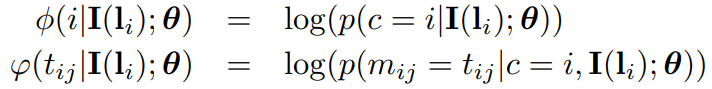
前面定义的公式是加和的形式
取对数 每次预测都是预测图像块中间的像素是否是某个像素
推理
目标是最大化 score function: 。由于关系图是一棵树,所以可以通过动态规划完成这个过程。
。由于关系图是一棵树,所以可以通过动态规划完成这个过程。
记 是节点的 children 集合(
是节点的 children 集合( ,如果是叶子节点)。
,如果是叶子节点)。 是根节点在关节点,关节点位于
是根节点在关节点,关节点位于 的子树的最大得分。每个子树的最大得分计算如下:
的子树的最大得分。每个子树的最大得分计算如下: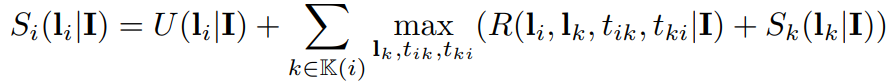
没怎么看懂,动态规划???
学习
作者的模型由三组参数组成:不同成对关系类型的平均相对位置  ;图像相关项的参数 ;和权值参数
;图像相关项的参数 ;和权值参数  。它们通过K-means算法用于 的求解 ,DCNN用于 的学习,S-SVM用于 的学习。
。它们通过K-means算法用于 的求解 ,DCNN用于 的学习,S-SVM用于 的学习。
Mean Relative Positions and Type Labels
给定标注的正样本图像 ,令
,令 表示关节点到的相对位置。作者对训练集中的这个相对位置进行了聚类从而产生
表示关节点到的相对位置。作者对训练集中的这个相对位置进行了聚类从而产生 个类(实验中,作者令所有的关节点对的
个类(实验中,作者令所有的关节点对的 ),每一个关系类用表示。所有的聚类中心定义为平均相对位置
),每一个关系类用表示。所有的聚类中心定义为平均相对位置 (每一个聚类中心都有一个平均值,聚类中心的类别由控制)
(每一个聚类中心都有一个平均值,聚类中心的类别由控制)
Parameters of Image Dependent Terms
每一个局部图像块 ,根据其中心是哪个关节点,那么可以对图像块进行类别标注
,根据其中心是哪个关节点,那么可以对图像块进行类别标注 以及关节点type标注
以及关节点type标注 ,那么我们就可以得到标注了的图像块集合
,那么我们就可以得到标注了的图像块集合 (每张正样本图像提供个图像块),对于背景的话,则是
(每张正样本图像提供个图像块),对于背景的话,则是
在这些图像块以及label下,作者训练DCNN。DCNN是一个分类器,其最终的输出维度为 ,即状态空间的size,也就是说DCNN最终输出一个向量,向量表征了图像块属于前面所定义的状态空间中任意一个状态的概率(包括了关节点,以及关节点的type等信息)
,即状态空间的size,也就是说DCNN最终输出一个向量,向量表征了图像块属于前面所定义的状态空间中任意一个状态的概率(包括了关节点,以及关节点的type等信息)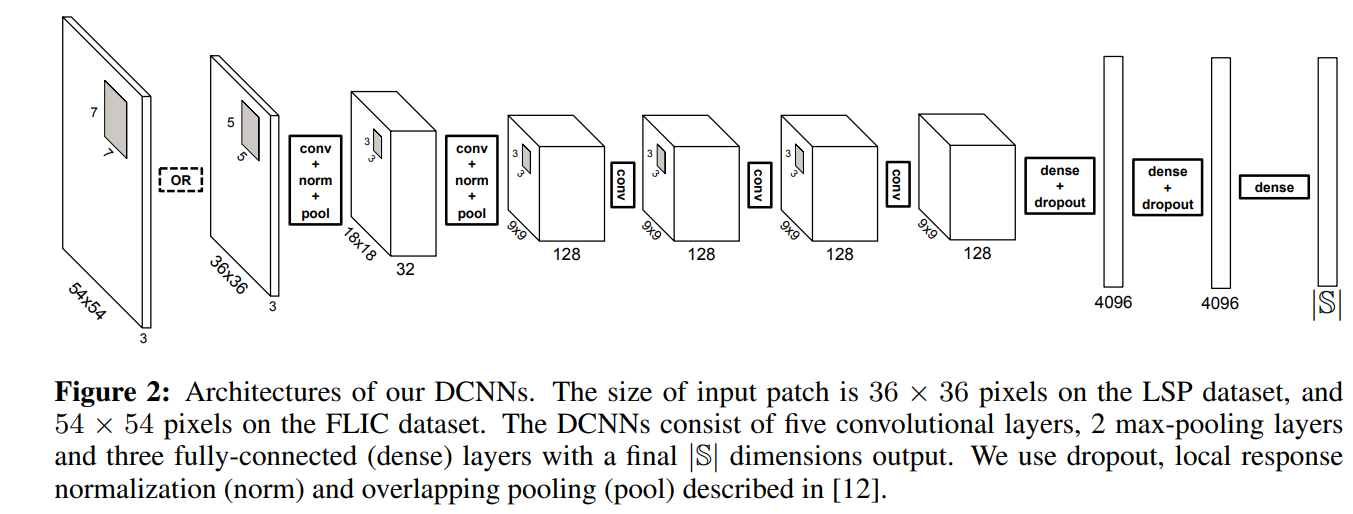
Weight Parameters
在前面的步骤中,已经有了关节点的位置以及类别信息: 。作者采用 S-SVM 来学习权值参数
。作者采用 S-SVM 来学习权值参数 。通过使用
。通过使用 损失简化结构预测问题。即所有训练示例或者其标签的所有维度都正确或者其标签的所有维度都是错误的。作者将前者表示为正例,将后者表示为负例(负例怎么来的?)。
损失简化结构预测问题。即所有训练示例或者其标签的所有维度都正确或者其标签的所有维度都是错误的。作者将前者表示为正例,将后者表示为负例(负例怎么来的?)。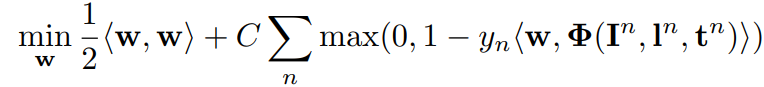
 是表示第
是表示第  个示例的稀疏特征向量,并且是(根据学习的DCNN)图像相关项、空间变形特征和常数1的 concatenation。如果
个示例的稀疏特征向量,并且是(根据学习的DCNN)图像相关项、空间变形特征和常数1的 concatenation。如果  ,则
,则  ,如果
,如果  ,则
,则  。
。
这个部分是什么意思?将前面学习到的向量利用S-SVM进行分类吗?如何和前面的得分函数联系起来? 注意:上面那个优化公式是和SVM的优化公式类似的(SVM的二分类问题)按照这种思路理解的话,就是通过前面方法得到的特征,将利用SVM对其进行分类。事实上就是一个线性问题,这里采用的SVM进行求解。和前面的关于
加权求和的 score function,进行对比。我们希望的是 score function 在正确的
上能够得到最大的响应,在不正确的地方能够得到小的响应。这里的S-SVM,我们同样是希望他在正确的样本上输出1(最大值),在错误的样本数输出0(最小值)。故利用这种方式是能够和前面的 score function对应起来的。
本文结构总结:
- 利用K-means来聚类关节点直接的相对位置关系,从而将同一个关节分为11种状态,并获取了每一种状态的平均相对位置,这可以作为一个先验知识
- 利用DCNN来提取每个图像块对应特定状态空间的概率
- 利用S-SVM将DCNN提取的特征(进行后续的转换,与score function对应)进行分类,从而判断出该图像块中是否包括关节点
- 基于以上三个步骤即可获取关节点的位置等信息
其可解释性感觉比其他方法相对要好,每一步的目的性非常的明确
结果
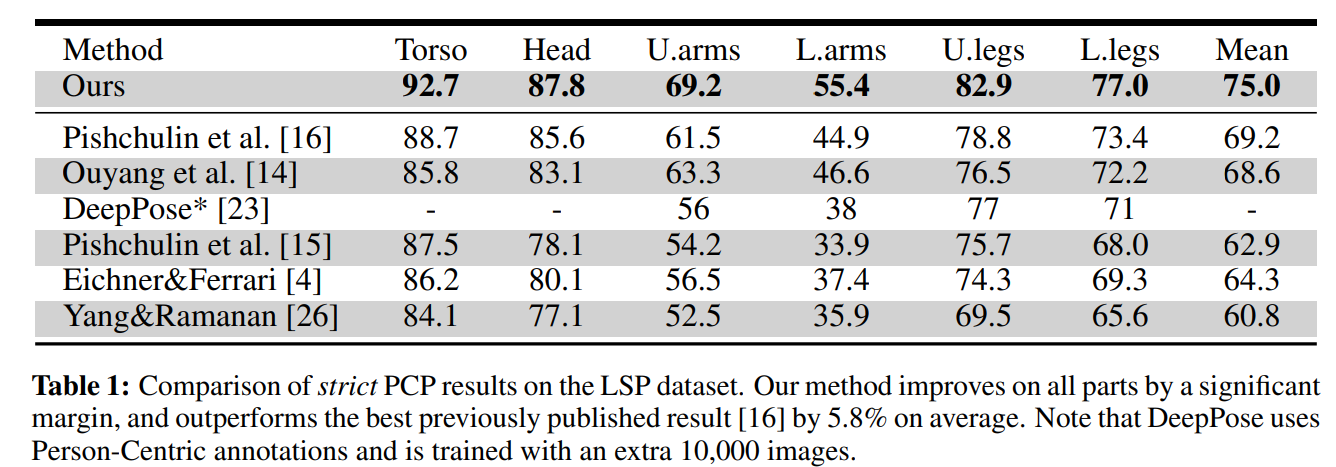
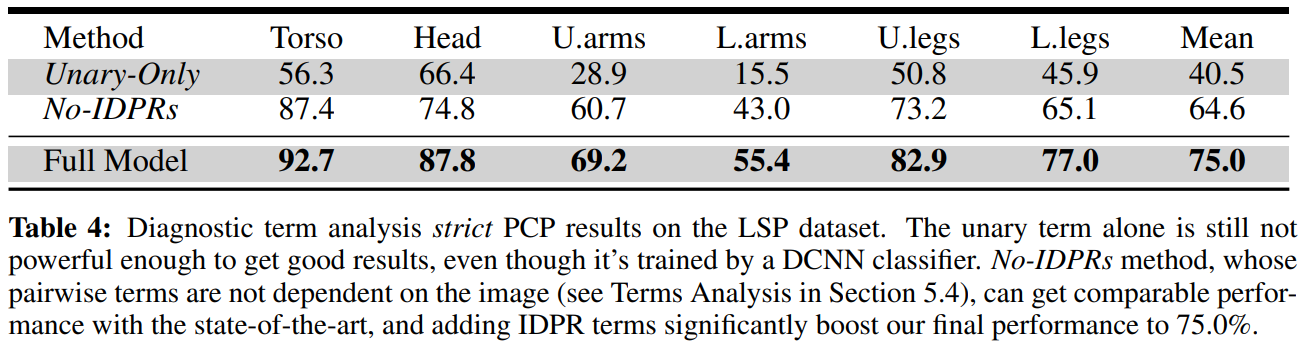

若有收获,就点个赞吧
0 人点赞
