有趣单词
novel: 新颖的tradeoff: 权衡distinct: 截然不同的leverage: 利用robustness: 鲁棒性vocabulary: 词汇表hinge: 使以什么为条件convergence:收敛decouple: 使分离fine-grained:细粒度的robust: 健壮的
值得注意的
softmax将输出转为概率分布,其前提是各个类别是互相排斥的;
yolov2的改进
yolov1相对来说,定位的准确度比较差;
- yolov2主要目的就是在保证分类准确率的情况下,提高定位的准确度;
- 提高准确率不是以更深的网络为代价,而是简化网络,是的表征学习更简单;
- 能够识别的类别变多,yolov1为20,yolov2扩展到9000类;
- 利用已有的分类目标的数据集来扩充目标检测的数据集;(?)
- yolov1直接回归检测框坐标,yolov2采用了anchor boxes
- 采用anchor boxes之后,就用anchor boxes去预测类(仍旧是one-stage,就是位置回归方式不同了),而不是同时实现位置回归和类别分类;
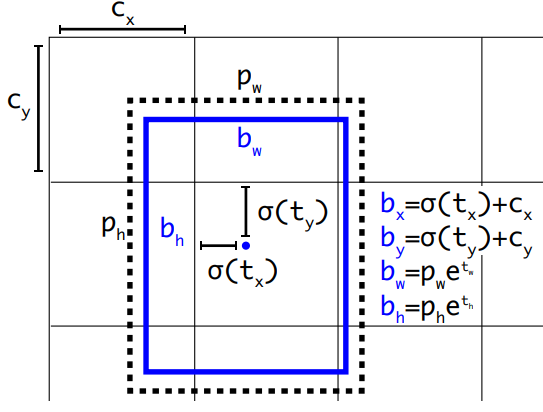
- anchor boxes通过k-means进行聚类得到,权衡之后k取值为5;(之前的anchor boxes都是通过人进行挑选的)
- 聚类产生的5个anchor boxes作为,boxes长宽的初始值;
- 后期预测boxes的长宽相对于聚类的anchor boxes进行偏移(参考下图所示);
- yolov2的坐标预测和yolov1类似,还是预测中心点相对于格子的偏移;(每个格子预测5个boxes)
- 网络中有short-cut实现不同层的feature融合;(通常来说,浅层网络的分辨率更高)
- 此操作的目的就是为了适应对不同size目标的检测;
- 不同层的特征直接通过通道进行连接;
- 对于feature map size不同的需要对高分辨率的特征进行reshape;
- 比如26261024和13132048的连接,需要将前者变为13134096;
- 多尺度训练;
- 每10个epoch改变输入图片的size,最小为360360,最大为608608;
- 这说明网络不包括全连接层;
- yolov2每个grid包括5个boxes,每个boxes预测一个物体;
- 5*(5+20)
- 综合目标检测和分类任务的图片进行训练;
- 对于目标检测的数据,对整个损失函数进行反向传播;
- 对于分类任务的数据,只对网络损失函数中的分类部分进行反向传播;

若有收获,就点个赞吧
0 人点赞
