论文原文:Human Pose Estimation with Iterative Error Feedback 代码链接:https://github.com/pulkitag/ief 博客参考:Human Pose Estimation with Iterative Error Feedback 论文解读 博客参考:https://blog.csdn.net/github_36923418/article/details/102861651
本文与其它网络不同之处,具有反馈,方法每次估计偏差然后迭代优化结果。
Our main contribution is in providing a generic framework for modeling rich structure in both input and output spaces by learning hierarchical feature extractors over their joint space.
本文大致方法
方法大致流程(回归坐标的方式,并不是预测heatmaps):
- 利用统计的平均值初始化

- 前向模型
 输入:RGB图像
输入:RGB图像 和visual representation
和visual representation  连接构成的增强输入空间(其中以
连接构成的增强输入空间(其中以 作为输入)
作为输入) - 前向模型输出:预测的一个修正值
 ,目的是让与真值更加接近(修正值每轮次都是有界的:输入空间往往是非线性的,所以local corrections应该容易学习)
,目的是让与真值更加接近(修正值每轮次都是有界的:输入空间往往是非线性的,所以local corrections应该容易学习) - 估计结果更新:

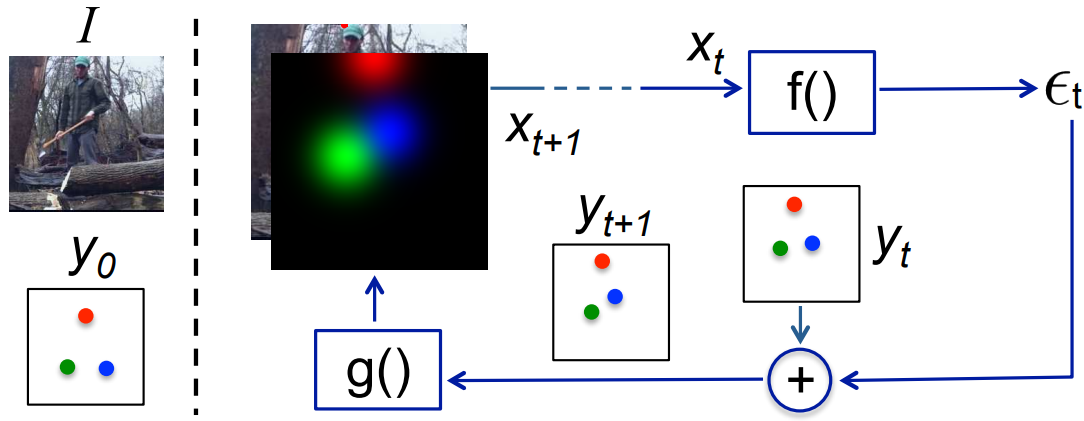
上图表示的内容公式描述:
其中:
- 表示输入图像
- 表示预测的偏差
- 表示第
 次迭代之后的预测输出(事实上这里可以用任意的非线性函数来操作
次迭代之后的预测输出(事实上这里可以用任意的非线性函数来操作 )
)  为卷积网络的输入,
为卷积网络的输入, 表示concat
表示concat 表示前馈网络
表示前馈网络 表示从预测输出到视觉表示的一个映射
表示从预测输出到视觉表示的一个映射
值得注意的是,产生的是heatmaps,利用高斯分布(K个关节点有K个heatmaps);利用ConvNet来表示,其输入size为
我们要估计什么内容,通常就是设计一个网络,对其训练之后来完成这个估计的任务
网络学习
参数学习时,是一个优化过程: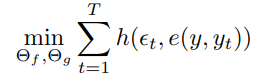
其中 可以是一个二次损失函数(凸函数),目的是使得网络输出的与真值和当前估计值直接无限接近。
可以是一个二次损失函数(凸函数),目的是使得网络输出的与真值和当前估计值直接无限接近。 是迭代轮次,可以是尝试,也可以是一个域相关的函数等。
是迭代轮次,可以是尝试,也可以是一个域相关的函数等。
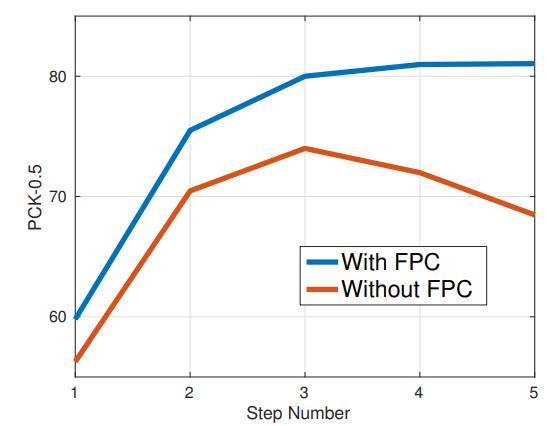
还有一个内容值得注意:在训练网络时,我们只有最终的真值 对于中间态的如何对其监督呢?作者采用的方式是事先计算好作为label的中间态
对于中间态的如何对其监督呢?作者采用的方式是事先计算好作为label的中间态 ,作者称其为Fixed Path Consolidation (FPC),实现时很简单,可以直接选用直线路径(参考后面的图)将
,作者称其为Fixed Path Consolidation (FPC),实现时很简单,可以直接选用直线路径(参考后面的图)将 之间的直线等分。
之间的直线等分。
那么难道网络不能直接用估计的
很难有界,它被期望的值是
,这个值是变化的(也就是说,每次
Learning Human Pose Estimation
此处内容是如何定义前面出现的 ,其中
,其中 ,
, 表示归一化的向量,
表示归一化的向量, 表示每个关节点的偏移的最大范围,文章中设为20个像素点
表示每个关节点的偏移的最大范围,文章中设为20个像素点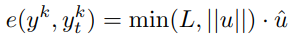
文章中的
很容易产生歧义,应该他可以表示预测的关节点位置,也可以表示作者定义的中继监督label。
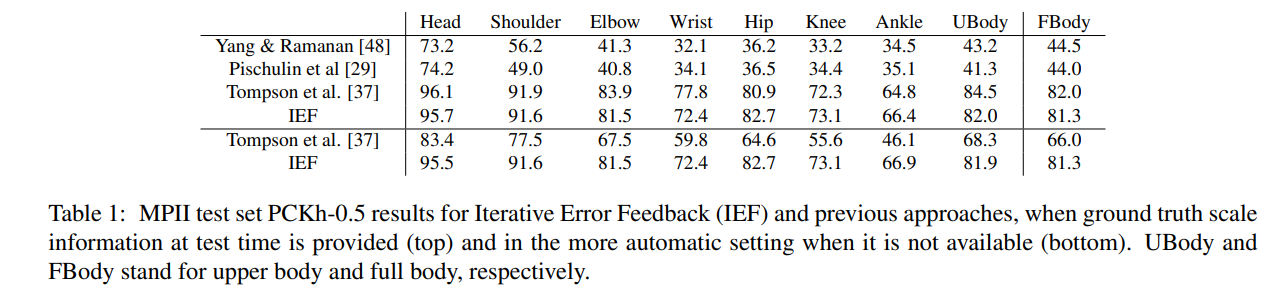
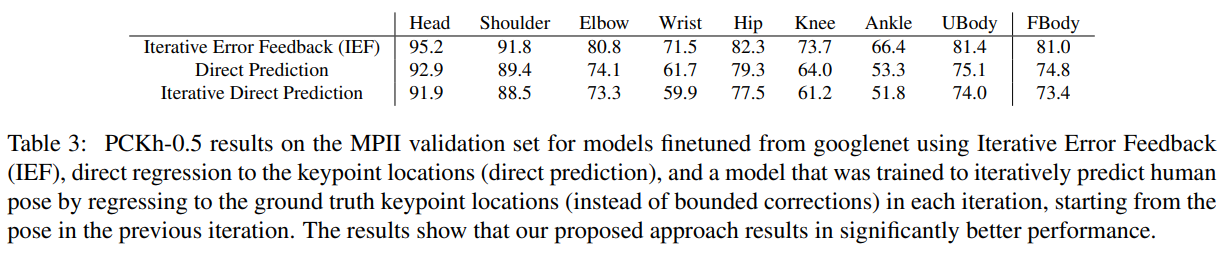
实验结果

若有收获,就点个赞吧
0 人点赞
