论文地址: 链接
Abstract
We propose a viewpoint invariant model for 3D human pose estimation from a single depth image. To achieve this, our discriminative model embeds local regions into a learned viewpoint invariant feature space. Formulated as a multi-task learning problem, our model is able to selectively predict partial poses in the presence of noise and occlusion. Our approach leverages a convolutional and recurrent network architecture with a top-down error feedback mechanism to self-correct previous pose estimates in an end-to-end manner. We evaluate our model on a previously published depth dataset and a newly collected human pose dataset containing 100K annotated depth images from extreme viewpoints. Experiments show that our model achieves competitive performance on frontal views while achieving state-of-the-art performance on alternate viewpoints.
可以预测遮挡关节点。采用架构:CNN+RNN 本文主要就是解决视角问题(视角不同造成关节点的遮挡)
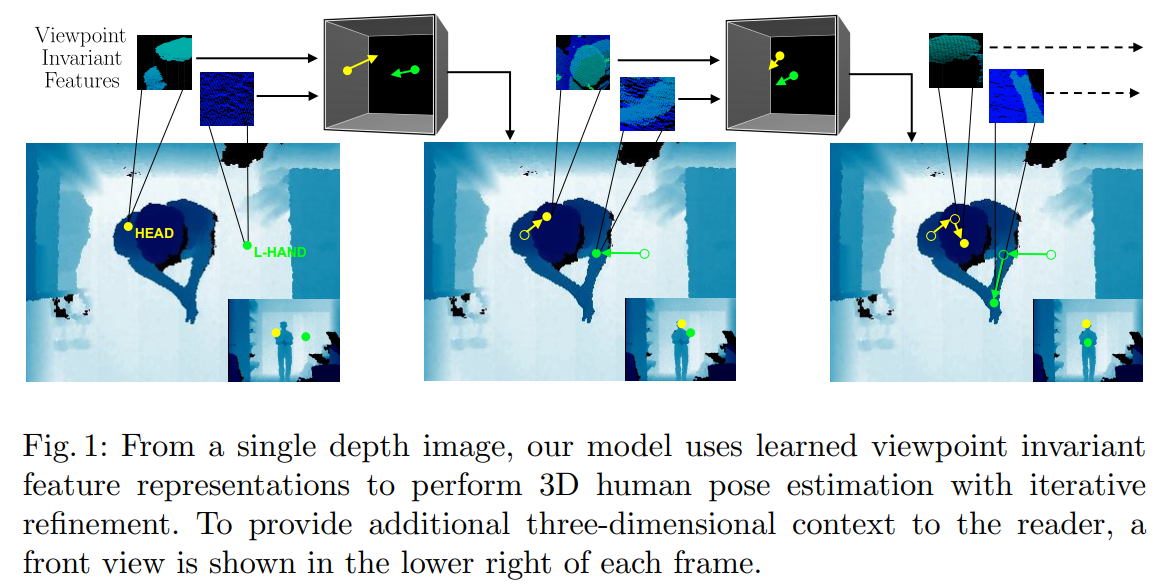
使得模型学得具有视角不变性的特征
Introduction
There are two challenges towards this goal. The first challenge is designing a model that is not only rich enough to reason about 3D spatial information but also robust to viewpoint changes. The model must understand both local and global human pose structure. That is, it must fuse techniques from local part-based discriminative models and global skeleton-driven generative models. Additionally, it must be able to reason about 3D volumes, geometric, and viewpoint transformations. The second challenge is that existing real-world depth datasets are often small in size, both in terms of number of frames and number of classes [21,20]. As a result, the use of representation learning methods and viewpoint transfer techniques has been limited.
模型设计的困难以及数据集的困难
To address these challenges, our contributions are as follows: First, on the technical side, we embed local pose information into a learned, viewpoint invariant feature space. Furthermore, we extend the iterative error feedback model [10] to model higher-order temporal dependencies (Figure 1). To handle occlusions, we formulate our model with a multi-task learning objective. Second, we introduce a new dataset of 100K depth images with pixel-wise body part labels and 3D human joint locations. The dataset consists of extreme cases of viewpoint variance with front, top, and side views of people performing 15 actions with occluded body parts. We evaluate our model on an existing public dataset [21] and our newly collected dataset demonstrating state-of-the-art performance on viewpoint invariant pose estimation.
迭代误差反馈模型效果好像不是很好
Because human pose estimation is ultimately a structured prediction task, it is difficult for convolutional networks to correctly regress the full pose in a single pass. Recently, iterative refinement techniques have been proposed to address this issue.
Depth-Based Human Pose Estimation
可以分为两类:生成模型和判别模型。生成模型进行模板匹配,判别模型检测身体部位的实例
Shotton et al. trained a random forest classifier for body part segmentation from a single depth image and used mean shift to estimate joint locations. 随机森林进行点的分类;mean shift选取最佳估计的点作为关节点。后续有一些对其的改进方法,都是基于“森林”
Occlusion Handling and Viewpoint Invariance
One popular approach to model occlusions is to treat visibility as a binary mask and jointly reason on this mask with the input images. Other approaches such as [7,23], include templates for occluded versions of each part. More sophisticated models introduce occlusion priors [32,9] or semantic information [22].
For rigid body pose estimation and 3D object analysis, several descriptors have been proposed. 例如SIFT等.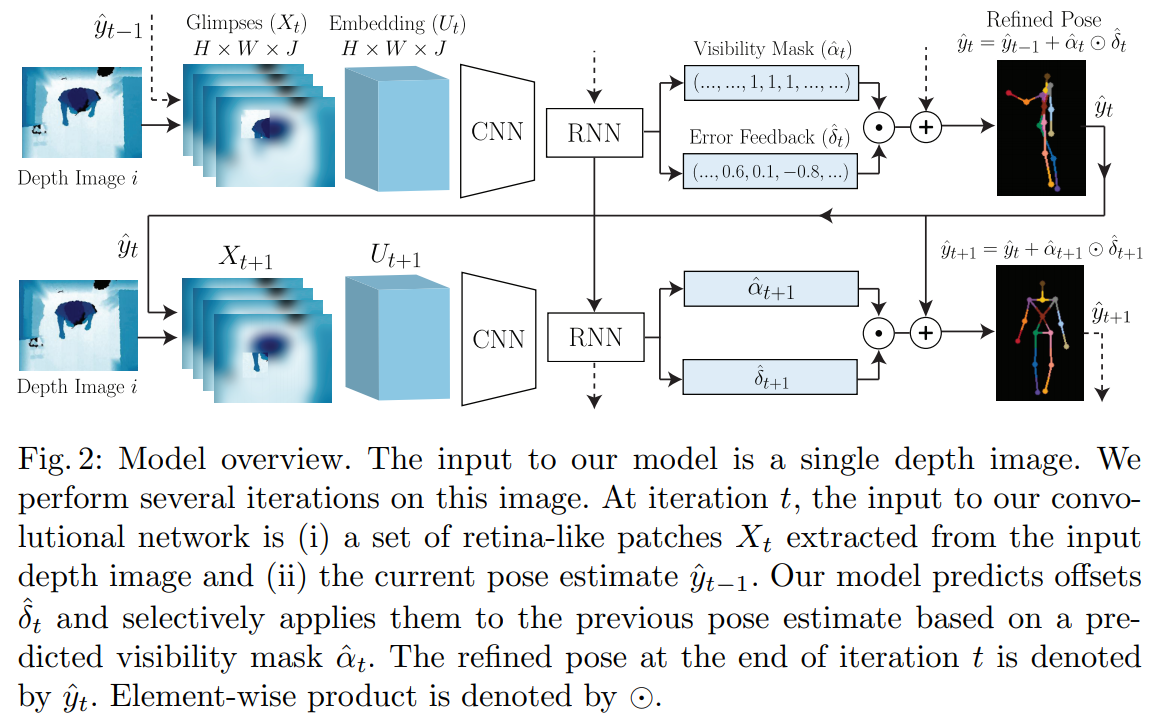
Model
Our core contribution is as follows: we leverage depth data to embed local patches into a learned viewpoint invariant feature space. As a result, we can train a body part detector to be invariant to viewpoint changes. To provide richer context, we also introduce recurrent connections to enable our model to reason on past actions and guide downstream global pose estimation (see Figure 2).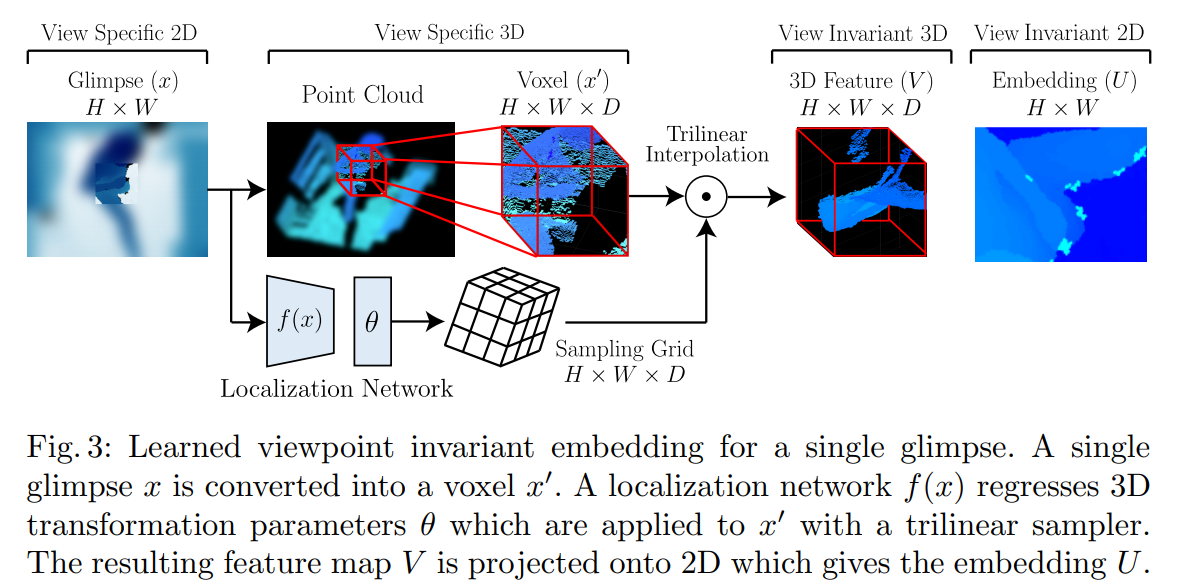
embedding 如何得到?CNN提取吗? 需要涉及到点云或者体素吗?
Model Architecture
Local Input Representation.
One of our goals is to use local body part context to guide downstream global pose prediction. To achieve this, we propose a two-step process. First, we extract a set of patches from the input depth image where each patch is centered around each predicted body part. By feeding these patches into our model, it can reason on low-level, local part information. We transform these patches into patches called glimpses [47,38]. A glimpse is a retina-like encoding of the original input that encodes pixels further from the center with a progressively lower resolution. As a result, the model must focus on specific input regions with high resolution while maintaining some, but not all spatial information. These glimpses are stacked and denoted by  where
where  is the number of joints,
is the number of joints,  is the glimpse height, and
is the glimpse height, and  is the glimpse and width. Glimpses for iteration
is the glimpse and width. Glimpses for iteration  are generated using the predicted pose
are generated using the predicted pose  from the previous iteration
from the previous iteration  . When
. When  , we use the average pose
, we use the average pose  .
.
Glimpses是什么东西???对原输入进行编码,编码效果:对远离中心的像素采用逐渐降低的分辨率进行编码。=> 输入区域必须是高分辨的
Learned Viewpoint Invariant Embedding.
将输入嵌入到具有视角不变性特征空间。输入 是一个真实世界的深度图,可以将其转换为体素
是一个真实世界的深度图,可以将其转换为体素 。体素是深度图的体积表示,不是一个完整的3D模型。This representation allows us to transform the glimpse in 3D thereby simulating occlusions and geometric variations which may be present from other viewpoints. 在体素的基础上,例如记体素为
。体素是深度图的体积表示,不是一个完整的3D模型。This representation allows us to transform the glimpse in 3D thereby simulating occlusions and geometric variations which may be present from other viewpoints. 在体素的基础上,例如记体素为 ,我们通过一个two-step process将其转为一个具有视角不变性的特征图
,我们通过一个two-step process将其转为一个具有视角不变性的特征图 :First, we use a localization network
:First, we use a localization network  to estimate a set of 3D transformation parameters
to estimate a set of 3D transformation parameters  which will be applied to the voxel
which will be applied to the voxel  . Second, we compute a sampling grid defined as
. Second, we compute a sampling grid defined as  . 在此基础上得到相关的特征,然后将其输入CNN网络中。
. 在此基础上得到相关的特征,然后将其输入CNN网络中。
Convolutional and Recurrent Networks.
Directly regressing body part positions from the dense activation layers2 has proven to be difficult due to the highly non-linear mapping present in traditional human pose estimation [59]. Inspired by [10]’s work in the RGB domain, we adopt an iterative refinement technique which uses multiple steps to fine-tune the pose by correcting previous pose estimates. we introduce recurrent connections between each iteration; specifically a long short term memory (LSTM) module [31]. This enables our model to directly access the underlying hidden network state which generated prior feedback and model higher-order temporal dependencies.
Multi-Task Loss
Our primary goal is to achieve viewpoint invariance. In extreme cases such as top views, many human joints are occluded. To be robust to such occlusions, we want our model to reason on the visibility of joints. We formulate the optimization procedure as a multi-task problem consisting of two objectives: (i) a body-part detection task, where the goal is to determine whether a body part is visible or occluded in the input and (ii) a pose regression task, where we predict the offsets to the correct real world 3D position of visible human body joints.
Body-Part Detection.
For body part detection, the goal is to determine whether a particular body part is visible or occluded in the input. This is denoted by the predicted visibility mask  which is a
which is a  binary vector, where is the total number of body joints. The ground truth visibility mask is denoted by
binary vector, where is the total number of body joints. The ground truth visibility mask is denoted by  . If a body part is predicted to be visible, then
. If a body part is predicted to be visible, then  , otherwise
, otherwise  denotes occlusion. The visibility mask is computed using a softmax over the unnormalized log probabilities
denotes occlusion. The visibility mask is computed using a softmax over the unnormalized log probabilities  generated by the LSTM. Hence, our objective is to minimize the cross-entropy. The visibility loss for a single example is:
generated by the LSTM. Hence, our objective is to minimize the cross-entropy. The visibility loss for a single example is: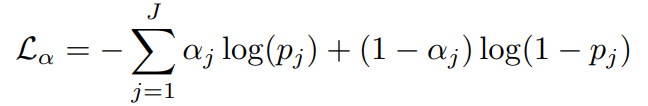
Partial Error Feedback.
Ultimately, our goal is to predict the location of the joint corresponding to each visible human body part. To achieve this, we refine our previous pose prediction by learning correction offsets (i.e. feedback) denoted by  . Furthermore, we only learn correction offsets for joints that are visible. At each time step, a regression predicts offsets
. Furthermore, we only learn correction offsets for joints that are visible. At each time step, a regression predicts offsets  which are used to update the current pose estimate
which are used to update the current pose estimate  . Specifically:
. Specifically:  denote real-world
denote real-world  positions of each joint.
positions of each joint.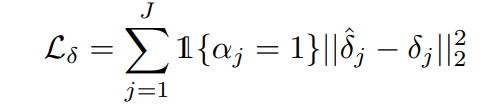
The loss shown in (4) is motivated by our goal of predicting partial poses. Consider the case of when the right knee is not visible in the input. If our model successfully labels the right knee as occluded, we wish to prevent the error feedback loss from backpropagating through our network. To achieve this, we include the indicator term  which only backpropagates pose error feedback if a particular joint is visible in the original image. A secondary benefit is that we do not force the regressor to output dummy real values (if a joint is occluded) which may skew the model’s understanding of output magnitude.
which only backpropagates pose error feedback if a particular joint is visible in the original image. A secondary benefit is that we do not force the regressor to output dummy real values (if a joint is occluded) which may skew the model’s understanding of output magnitude.
Global Loss.
The resulting objective is the linear combination of the error feedback cost function for all joints and the detection cost function for all body parts: . The mixing parameters λα and λδ define the relative weight of each sub-objective.
. The mixing parameters λα and λδ define the relative weight of each sub-objective.
Training and Optimization
端到端训练,初始化参数为高斯分布 。优化器Adam,initial learning rate of 1 × 10−5 , β1 = 0.9, and β2 = 0.999. An exponential learning rate decay schedule is applied with a decay rate of 0.99 every 1,000 iterations.
。优化器Adam,initial learning rate of 1 × 10−5 , β1 = 0.9, and β2 = 0.999. An exponential learning rate decay schedule is applied with a decay rate of 0.99 every 1,000 iterations.
Datasets
Stanford EVAL dataset
Similar to leave-one-out cross validation, we adopt a leave-one-out train-test procedure. One person is selected as the test set and the other two people are designated as the training set. This is performed three times such that each person is the test set once.
交叉验证真的好吗?
ITOP(项目地址)
Experiments
Evaluation Metrics
Percentage of correct keypoints (PCKh)、mAP(A successful detection occurs when the predicted joint is less than 10 cm from the ground truth in 3D space)
Implementation Details
mini-batches of size 10 and 10 refinement steps per batch.
We use the VGG-16 architecture for our convolutional network but instead modify the first layer to accommodate the increased number of input channels. Additionally, we reduce the number of neurons in the dense layers to 2048. We remove the final softmax layer and use the second dense layer activations as input into a recurrent network. For the recurrent network, we use a long short term memory (LSTM) module consisting of 2048 hidden units. The LSTM hidden state is duplicated and passed to a softmax layer and a regression layer for loss computation and pose-error computation. The model is trained from scratch.
The grid generator is a convolutional network with four layers. Each layer contains: (i) a convolutional layer with 32 filters of size 3 × 3 with stride 1 and padding 1, (ii) a rectified linear unit (iii) a max-pooling over a 2 ×2 region with stride 2. The fourth layer’s output is 10 × 10 × 32 and is connected to a dense layer consisting of 12 output nodes which defines . The specific 3D transformation parameters are defined in [33].
To generate glimpses for the first refinement iteration, the mean 3D pose from the training set is used. Glimpses are 160 pixels in height and width and centered at each joint location (in the image plane). Each glimpse consists of 4 patches where each patch is quadratically downsampled according to the patch number (i.e. its distance from the glimpse center). The input to our convolutional network is  where is the number of body part joints.
where is the number of body part joints.

若有收获,就点个赞吧
0 人点赞
