论文参考:ImageNet Classification with Deep Convolutional Neural Networks
网络结构
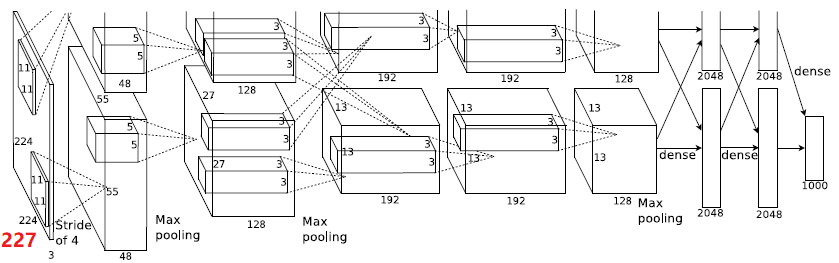
- 单GPU的话,计算量显然要大于两个GPU,应该单GPU相当于在两个GPU里面每层都是有两个GPU的交互;
- 经过Max pooling之后又patching操作;(除了第一个卷积,后面都有patching)
- 没有特殊说明的卷积都是步长为1;
技巧
- 对于非线性单元,利用Rectified Linear Units(Relu)取代tanh、sigmoid等易于饱和的非线性单元。
- 更快;
- 只有在正输入时才进行学习;
- 都是用在线性变换之后(conv、fc)
- 多GPU训练,分在两块GPU训练
- 单个 3GB的GPU 就不足以AlexNet训练!如何计算需要的GPU memory?(利用GPU的parallelization)两块GPU之间的数据交互只在特定的layer
LRN(Local Response Normalization)
- 其通常用在激活或者池化之后,与Relu搭配能够取得好的效果;
- 一种提高准确率的方法(饱受争议,现在一般被dropout替代);
- 灵感:神经生物学的“侧抑制”— 被激活的神经元抑制周围的神经元;
- 对于输入feature map经过
 之后,仍旧保持原来的大小;
之后,仍旧保持原来的大小;
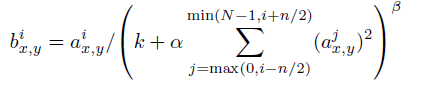
其中: 表示的是像素在此feature map的位置(与公式关系不是很大);
表示的是像素在此feature map的位置(与公式关系不是很大);- 原图经过第i个核以及relu操作之后生成的那个feature map;(对同一张图片,由于要输出很多个channel,所以核也有多个)
- N表示的是核的总个数;
 超参数,通过validation set进行调整;
超参数,通过validation set进行调整;- 也就是说其实是引入了核的竞争。
- 重叠池化
 ;
;- 数据增强
数据增强就是相当于扩大数据集;
- 方法1:随机切割、水平镜像翻转;
- 方法2:改变RGB通道的强度(利用PCA)(在每个像素都加上一定的值,计算较为复杂,有待继续深入掌握)
- 引入

- 引入
- 等价于综合多个网络预测结果得到更好结果,但是代价比较大;
- dropout技术在论文中被描述为一种模型综合方式(训练的代价大约为不带dropout的两倍);理解方式,每次训练时,隐藏的神经元有一定的概率被drop out掉,所以如果每次drop out掉的神经元不同,那么每次训练的就是不同的结构,这样就相当于综合了许多的模型;在测试的时候用所有的神经元(不drop out),但是对于每个神经元的输出都乘上一个数(该数具有一定的含义,论文中取的是0.5,表示的意义是预测结果分布的几何平均啥的:当然,由于是综合多个模型,在综合过程中需要进行一定的操作)
- 用了drop out收敛时变得更慢(书中网络,增加了一倍的时间);
- drop out用在了全连接层;
模型训练
batch size 128
**查资料显示,batch size不仅仅是为了提升训练的速度,还影响到最终的训练结果,尤其是引入了BN层的时 候**
momentum 0.9
momentum是一种网络的优化算法。
理解momentum:
如果用最简单的权值更新算法,将会出现:plateau更新慢,鞍点(saddle point)不更新,局部最小值不更新等情况。这时候引入动量,就能够解决这些问题。引入了动量就可以将训练过程类比为一个小球从山坡上往下滚的情况,显然只要有足够动量就可以脱离局部最优解等。
- weight decay 0.0005
weight decay使得网络中某些权重趋于0 ,去掉一些无用的连接,是一种正则化技术(drop out,BN也是正 则化技术,而且效果比weight decay好,正则化:提高泛化能力的方法-参考自某网页),能够防止过拟合。 (有待深入理解)
- 网络初始化
网络参数的初始化对于学习也很重要,好的初始化值能够提高收敛速度,更好地找到全局最优解等;论文中 的方法:
- 卷积层:高斯分布,mean-0,standard deviation-0.01;
- 全连接层:常数1;
- 神经元的biases:0。
- 训练过程中改变学习率
随着err降低到一定程度,lr也跟着降低
总结
AlexNet可以算是深度学习的开山之作,在论文中提出了深度学习网络的基本架构,并涉及了一些深度学习方面的技巧。
- 网络结构:卷积
 激活 池化
激活 池化  全连接;
全连接; - 数据增强方式;
- 网络正则化方式:dropout;
- 网络初始化;
- LRN等;

若有收获,就点个赞吧
0 人点赞
