论文原文:DeepPose: Human Pose Estimation via Deep Neural Networks 代码参考:https://github.com/mitmul/deeppose
这是首个利用深度学习方法进行人体姿态估计的尝试。传统方法一般是基于图结构和形变部件模型,设计2D
人体部件检测器,使用图模型建立各部件的连通性,并结合人体运动学的相关约束不断优化图结构模型来估
计人体姿态。常用的特征描述子包括HOG、SHIFT等(诸如行人检测等)。
为什么进行人体关键点识别:人体关键点识别的主要目的就是为了表征人体,简化人体。
作者观点
- 人体姿态识别需要整体把握全局信息,DNN相对来说更容易实现这种推理;(传统方法关注于局部信息)
- 采用回归的方式,直接回归关键点的坐标;
- 采用DNN级联方式提高精度;
后面研究者证明直接回归关键点比较困难,采用回归heatmap的形式?(为啥呢?CNN或者DNN到底应该有自己的偏好?)
直接回归关节点的困难之处在于:需要采用全连接层,使得空间信息变得不那么明显,从而使得空间泛化能力低;另一方面,基于heatmap的方式分辨率高,空间泛化能力高。基于回归的方法可以看做是在基于heatmap方法基础上再上了一层,所以它更为困难。
数据处理
- 输入为图像,标签为关节点向量;
- 引入归一化对于回归任务有利于准确回归;
假设以一个矩形区域
 为归一化区域(矩形区域可以直接是图像本身),其中
为归一化区域(矩形区域可以直接是图像本身),其中 分别表示矩形的中心,宽度以及高度。(其中
分别表示矩形的中心,宽度以及高度。(其中 表示标签,或者关节点的坐标(二维向量))
表示标签,或者关节点的坐标(二维向量))
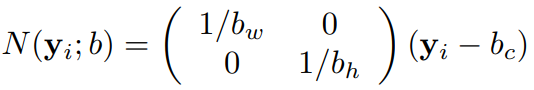
网络架构
下图中的结构只展示了包括参数的模块,无参数模块:LRN & Pooling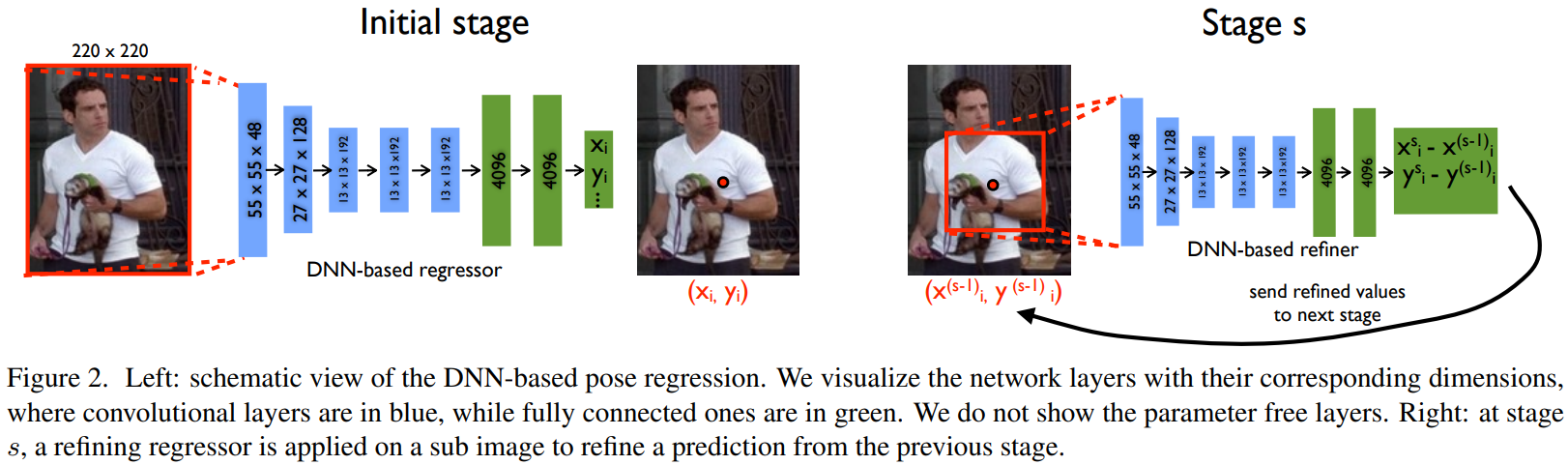
具体的网络架构表示(基本上参考了AlexNet的架构):
“Pooling is applied after three layers and contributes to increased performance despite the reduction of resolution.” 我在有的地方看到,Pooling层降低分辨率其实是会降低准确率的,其表现出来的提升准确率可能是由于模型难以训练的原因,很多论文出发的角度是“如何保证高的分辨率”(但是,不得不说,高分辨率的上限从直观角度来看是高于低分辨率的;但是其计算量大)
模型参数:大概为40M(基本上参考的AlexNet的架构,14年之前比较有名的就是AlexNet之类的了,VGG、GoogLeNet、Resnet等都是在14年及其之后才出来的;所以对于其的复现,完全可以采用后面更加先进的网络)
最终的Loss函数: distance
distance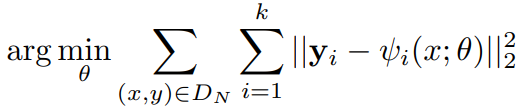
It should be noted, that the above objective can be used even if for some images not all joints are labeled. In this case, the corresponding terms in the sum would be omitted.(也就是说部分标注的图像同样可以训练,在求loss值时,我们只考虑有标注的关节点)
训练时的配置
网络输入图片大小:
mini-batch of size:128
学习率(最重要):0.0005
正则化手段:large number of randomly translated image crops, left/right flips as well as DropOut regularization for the F layers set to 0.6.
级联结构
DNN网络直接对整张图进行处理能够获取足够的全局信息,但是这种全局信息只能够得到一些比较粗略的坐标回归点。随着网络对全局信息的把握,他对细节信息的把握将不足,为了解决这个问题,从而需要引入级联结构,使得后续的结构输入是更加细节的信息,从而不断提高关节点的估计准确率。(实现方式,不断约束前面所提到的矩形框)
分级如下: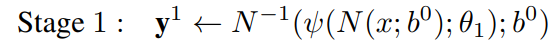
以整张图或者一个人体检测器进行初始化
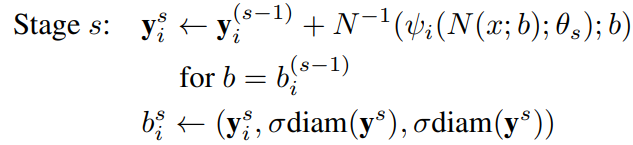
后续网络估计的是一个偏差
在对第
个关节点进行估计时需要选择第
表示直径(表示关节点和与之相对关节点的距离),显然后续其是一个正方形框
每级网络输入是啥
最开始的显然是整张图像,后续的是否需要切割?=> Yes,直接沿着估计的关节点处切割出来!切割出来的图像肯定需要resize到。(resize对结果影响如何?了解一下大家对resize的看法)
每级label
由于知道前级的输出,那么就可以利用前级的输出和GroundTrue进行中间级label的一个生成(根据指定点对关节点记性归一化)。
由于每次都是通过重点进行了归一化的,所以,每次网络输出的结果都是相对于中心点(上一级估计点)的偏移
模型训练
对图像和关节点采取多种标准化手段:
- 对于第stage
 的标签,真值为
的标签,真值为 ,作者基于真值以及预测的关节点位置产生仿真的预测输出。该输出采样于以所有训练样本的(对应关节点,对应stage)的均值和方差为均值和方差的二元正态分布,在下面公式中记为
,作者基于真值以及预测的关节点位置产生仿真的预测输出。该输出采样于以所有训练样本的(对应关节点,对应stage)的均值和方差为均值和方差的二元正态分布,在下面公式中记为 (通过这个随机性来增强输入到网络中的样本的多样性)
(通过这个随机性来增强输入到网络中的样本的多样性)
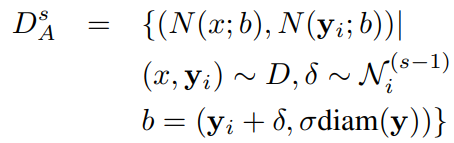
The full augmented training data can be defined by first sampling an example and a joint from the original data at uniform and then generating a simulated prediction based on a sampled displacement
from
;这里所有训练样本的
- 与之对应的方形框的选取也会相对于前面所述的方式有的中心偏移
验证
Metrics
Percentage of Correct Parts (PCP)PCP measures detection rate of limbs, where a limb is considered detected if the distance between the two predicted joint locations and the true limb joint locations is at most half of the limb length. PCP was the initially preferred metric for evaluation, however it has the drawback of penalizing shorter limbs, such as lower arms, which are usually harder to detect. 更为科学的是PDJ(Percent of Detected Joints):估计点与真值之间的归一化偏差与一个阈值进行比较 FLIC 中是以躯干直径(torso size) 作为归一化参考. MPII 中是以头部长度(head length) 作为归一化参考,即 PCKh.
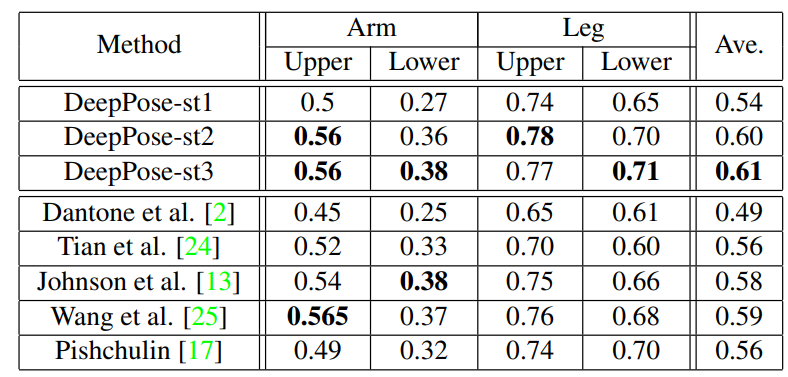
实验细节
部分统计结果

若有收获,就点个赞吧
0 人点赞
