详解transformer The Illustrated Transformer The Illustrated Transformer【译】
transformer最初是在NLP中提出的,其核心是注意力机制。之后研究人员将其应用到了CV领域,取得了不错的结果。
RNN的不足
- 不能够实现并行计算,因为
 时刻的结果依赖于
时刻的结果依赖于  时刻的结果;
时刻的结果; - LSTM能够在一定程度上解决长期依赖的问题,但是对于特别长的依赖无能为力
Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence aligned RNNs or convolution。
Transformer结构
在机器语言翻译中所用到的网络结构通常是“编码器-解码器”结构;编码器读入带翻译的语言将其编码为深层信息,解码器利用深层次信息产生对应的语言。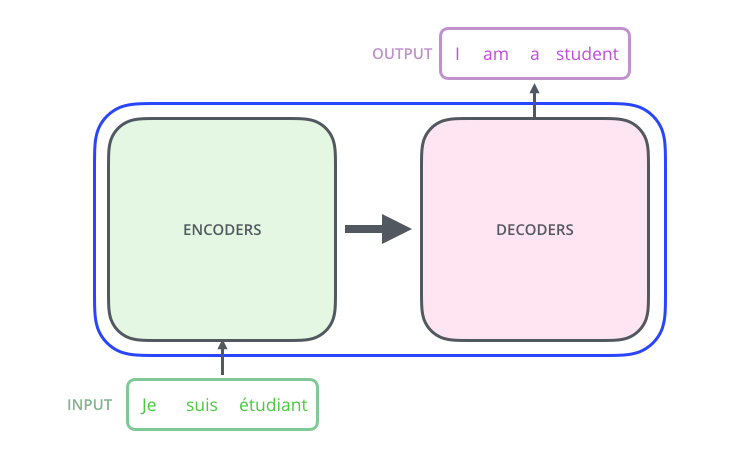
Encoder and Decoder
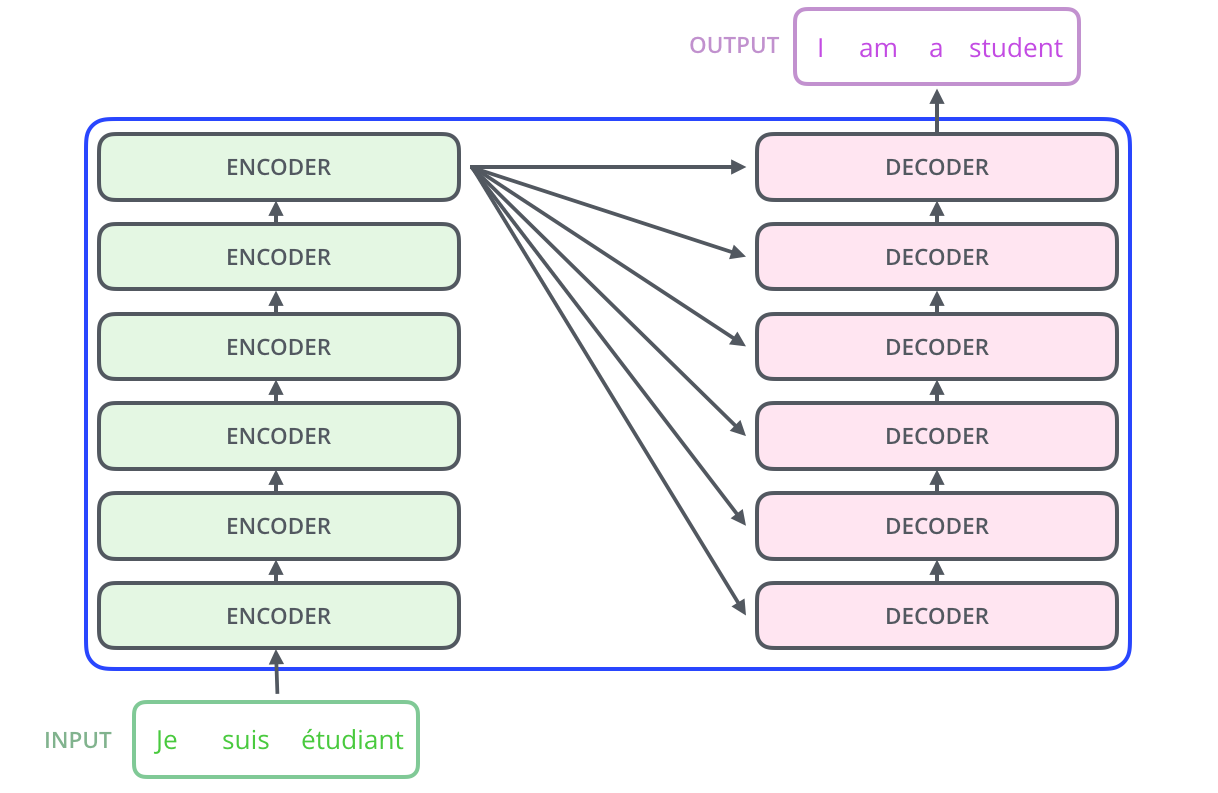
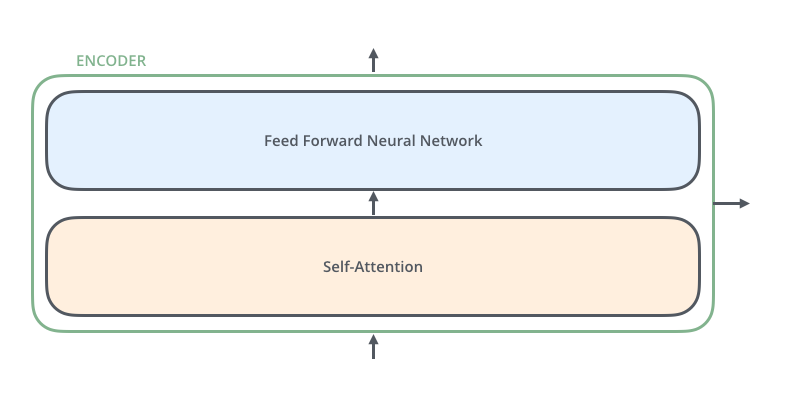
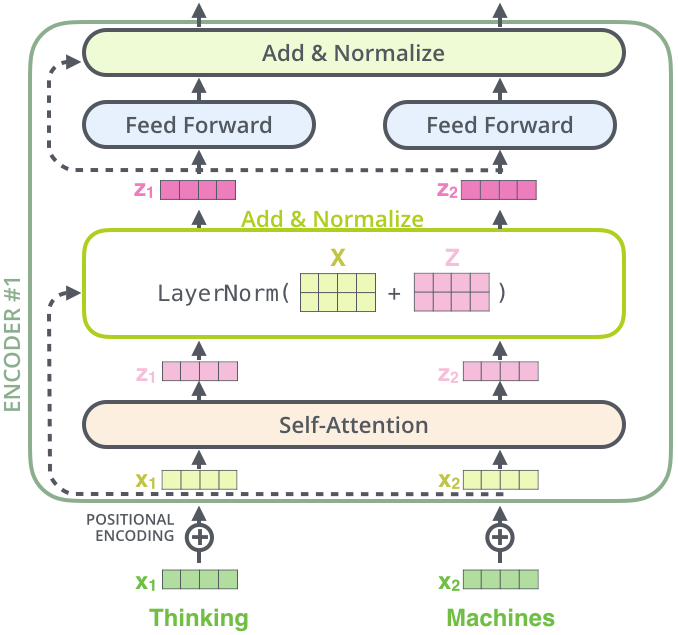
transformer中的 Encoders 有多个 Encoder 堆叠而成;它们的结构是完全一样的:Self-Attention + Feed Forward Neural Network,与 RNN 共享参数不同,每个 Encoder 都是独立的。
Self-Attention层,该层帮助编码器能够看到输入序列中的其他单词当它编码某个词时。 Self-Attention的输出流向一个前向网络,每个输入位置对应的前向网络是独立互不干扰的。
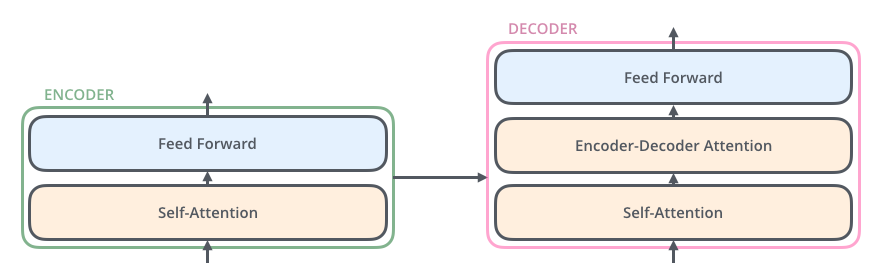
Decoder 相对于 Encoder 来说在中间多了个 Encoder-Decoder Attention层,这使得它能够关注到输入句子相关的部分。
数据输入
对于句子来说,为了方便其处理,需要首先将其进行向量化。每一个单词都将被向量化层一个512维的向量,所有单词组成一个 list(list 长度作为一个超参数)之后 list 将会被输入到网络中进行学习。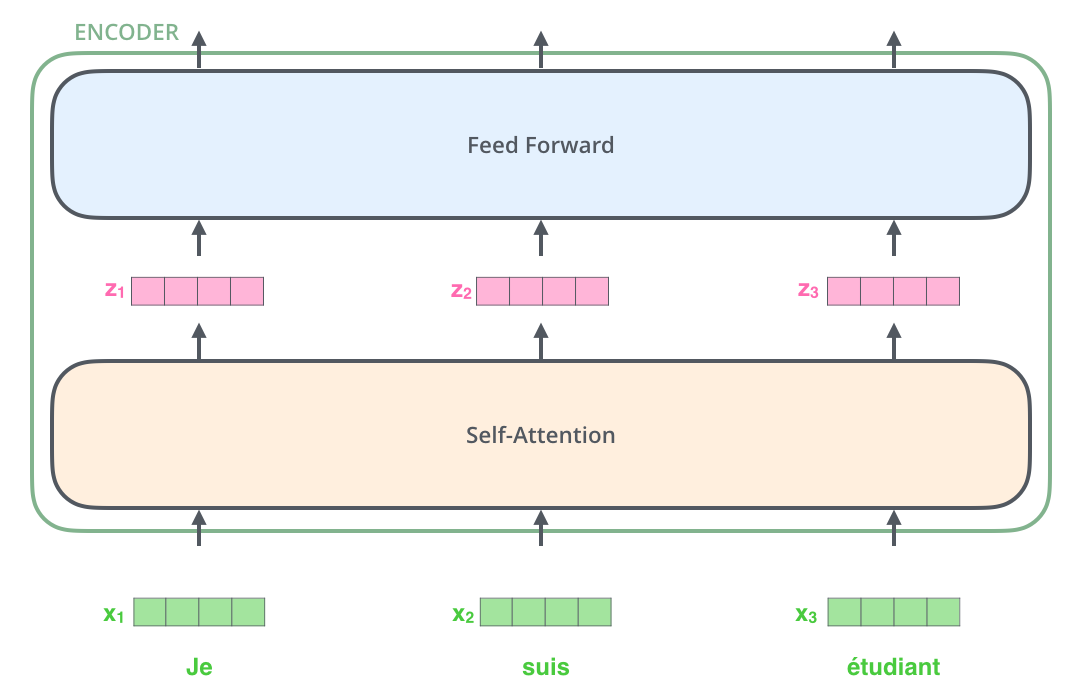
“这里能看到 Transformer 的一个关键特性,每个位置的词仅仅流过它自己的编码器路径。在self-attention层中,这些路径两两之间是相互依赖的。前向网络层则没有这些依赖性,但这些路径在流经前向网络时可以并行执行。”
这段话不是很理解,上面那张图被拓宽了图是表示数据并行的意思吗?这里的意思指的是,网络是匹配 list 的长度的,从而所有的词向量能够一起被处理? => 可以继续看后面的内容获得答案
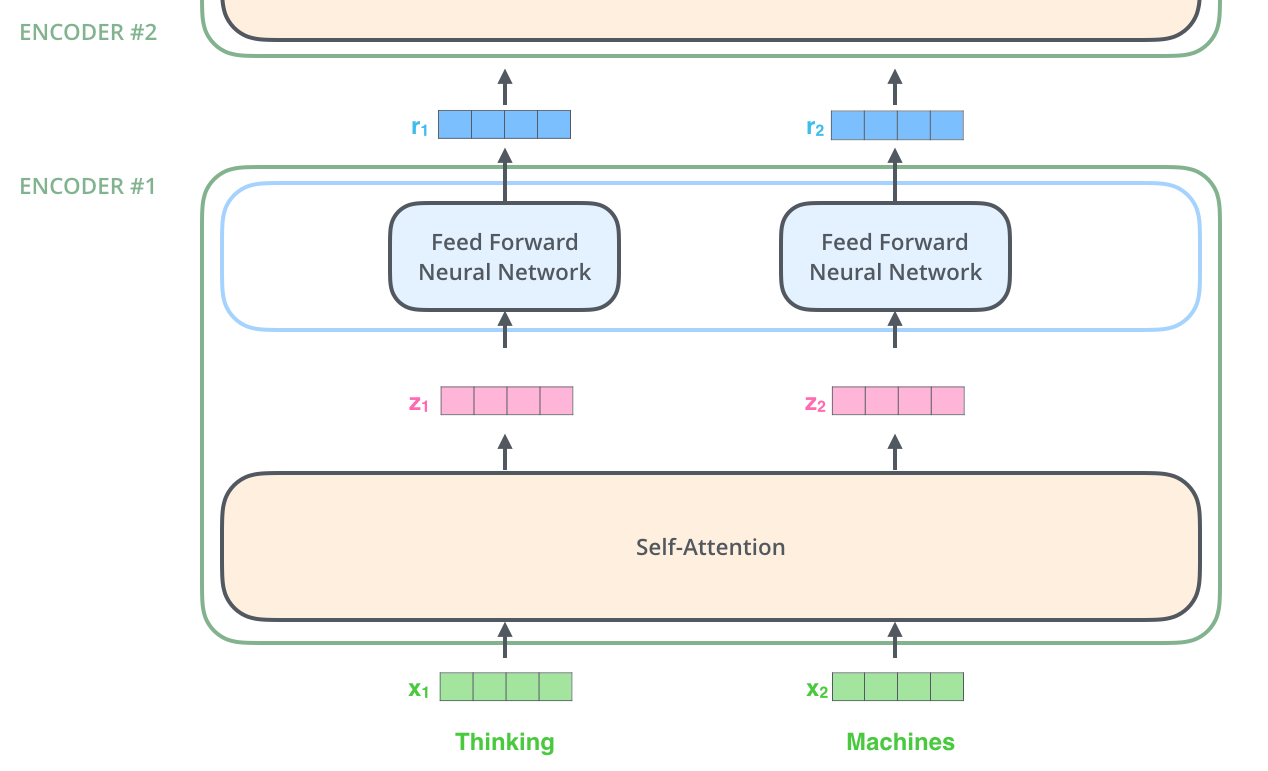
上面这张图和前面引用的那句话是匹配的,也就是说所有的向量是被同时处理的。并且在 Self-Attention 层中针对每个向量的部分是相互依赖的(前面说的两两相互依赖),而在 Feed Forward Neural Network 中针对每个向量的部分是独立的。
从图上可以看出数据的并行处理
Self-Attention
当模型处理每个位置的词时,self-attention 允许模型看到句子的其他位置信息作辅助线索来更好地编码当前词。
Self-attention is the method the Transformer uses to bake the “understanding” of other relevant words into the one we’re currently processing.

当编码”it”时(编码器的最后层输出),部分attention集中于”the animal”,并将其表示合并进入到“it”的编码中
利用Tensor2Tensor notebook对 Transformer 中 self-attention 的编码关系进行可视化,可以得到每个单词向量被编码时的依赖情况。
实现 Self-Attention
实现的具体细节,可以参考前面所提到的博客。此处简单记录其大概步骤:
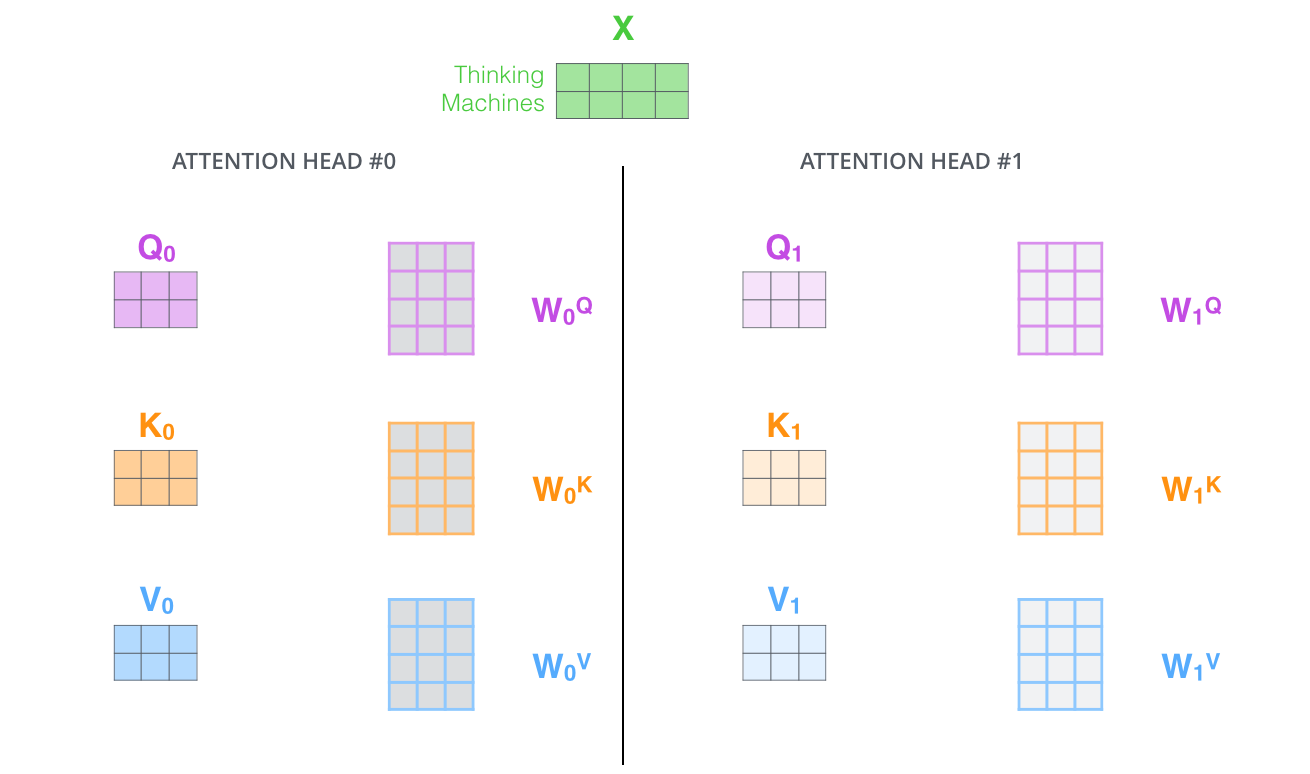
对于每个词向量产生三个向量,记作
 (有输入词向量和对应的矩阵做矩阵乘法得到)
(有输入词向量和对应的矩阵做矩阵乘法得到)主要产生三个向量需要用到的矩阵是所有词向量共享的;所以可以说是 Self-Attention 注意力机制(加权操作)依赖于前面所说的对应的矩阵的训练情况。
利用
 向量乘法得到加权分数,分数进行一定的缩小后通过 Softmax 层进行归一化得到加权分数:
向量乘法得到加权分数,分数进行一定的缩小后通过 Softmax 层进行归一化得到加权分数:
- 利用加权分数以及所有的词向量,通过加权求和得到对应位置的结果:

多头机制
也就是在上一步的基础上,采用多组矩阵进行注意力的提取。
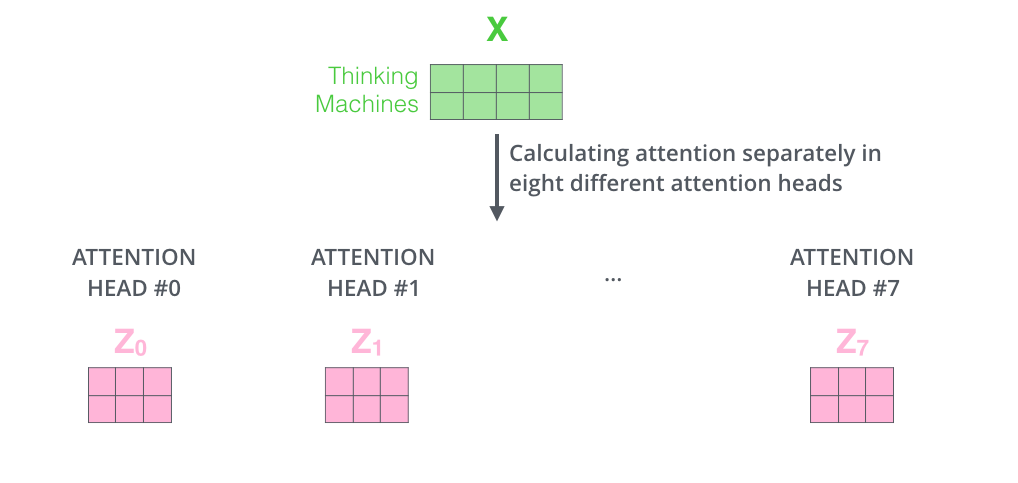
然后将每个头提取的矩阵进行拼接,然后与一个矩阵进行乘法操作之后,输入到后面的“前向网络”中。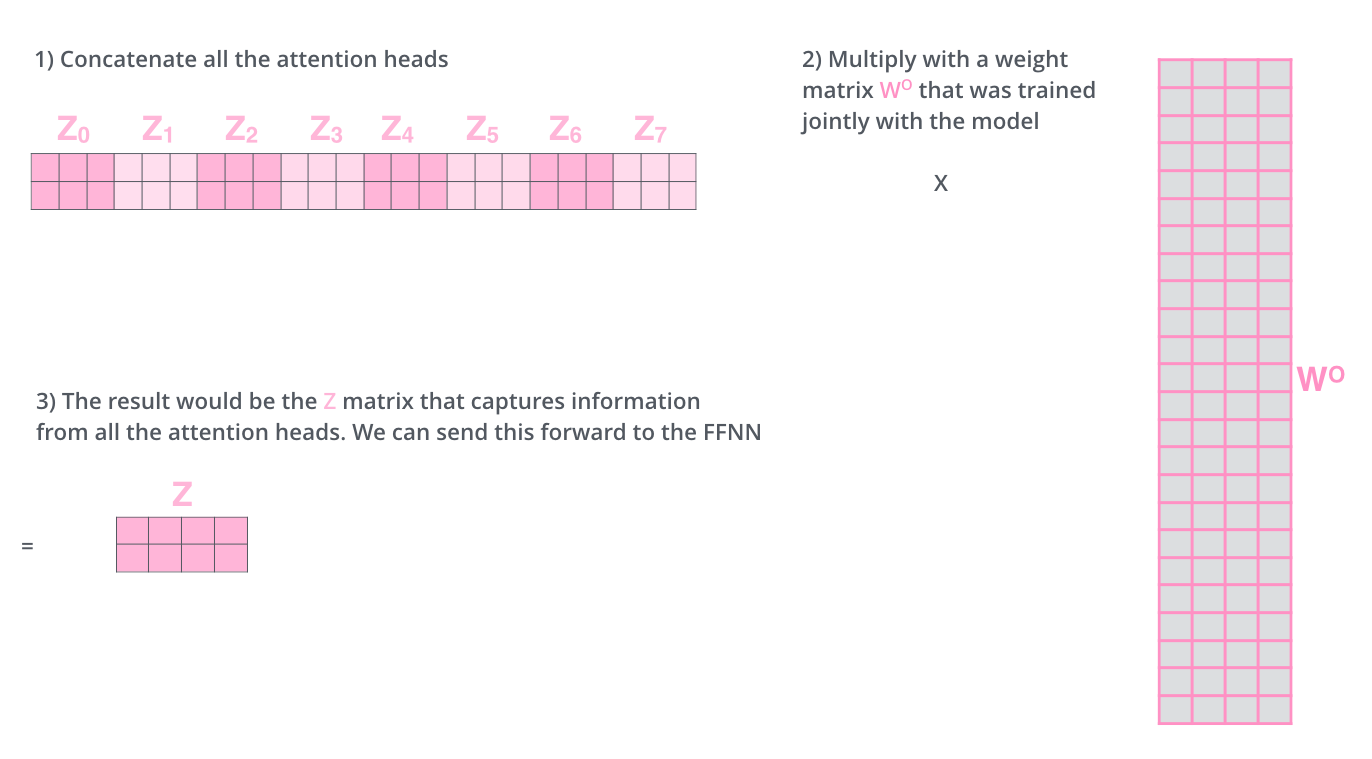
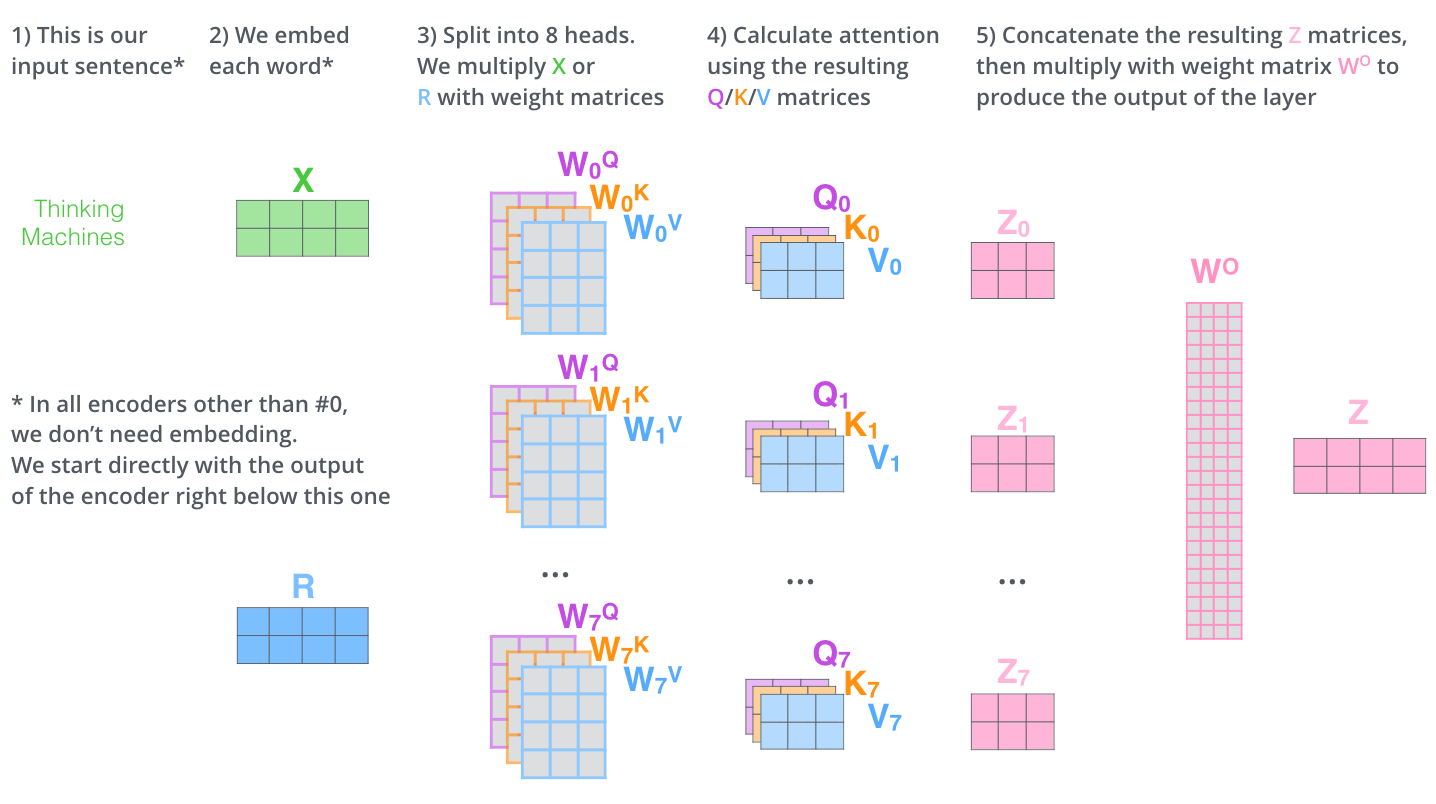
同样,按照前面所说的方式对注意力机制进行可视化,得到:
编码”it”时,一个attention head集中于”the animal”,另一个head集中于“tired”,某种意义上讲,模型对“it”的表达合成了的“animal”和“tired”两者
可以看到,多头能够组合更为复杂并且更加合理的信息。
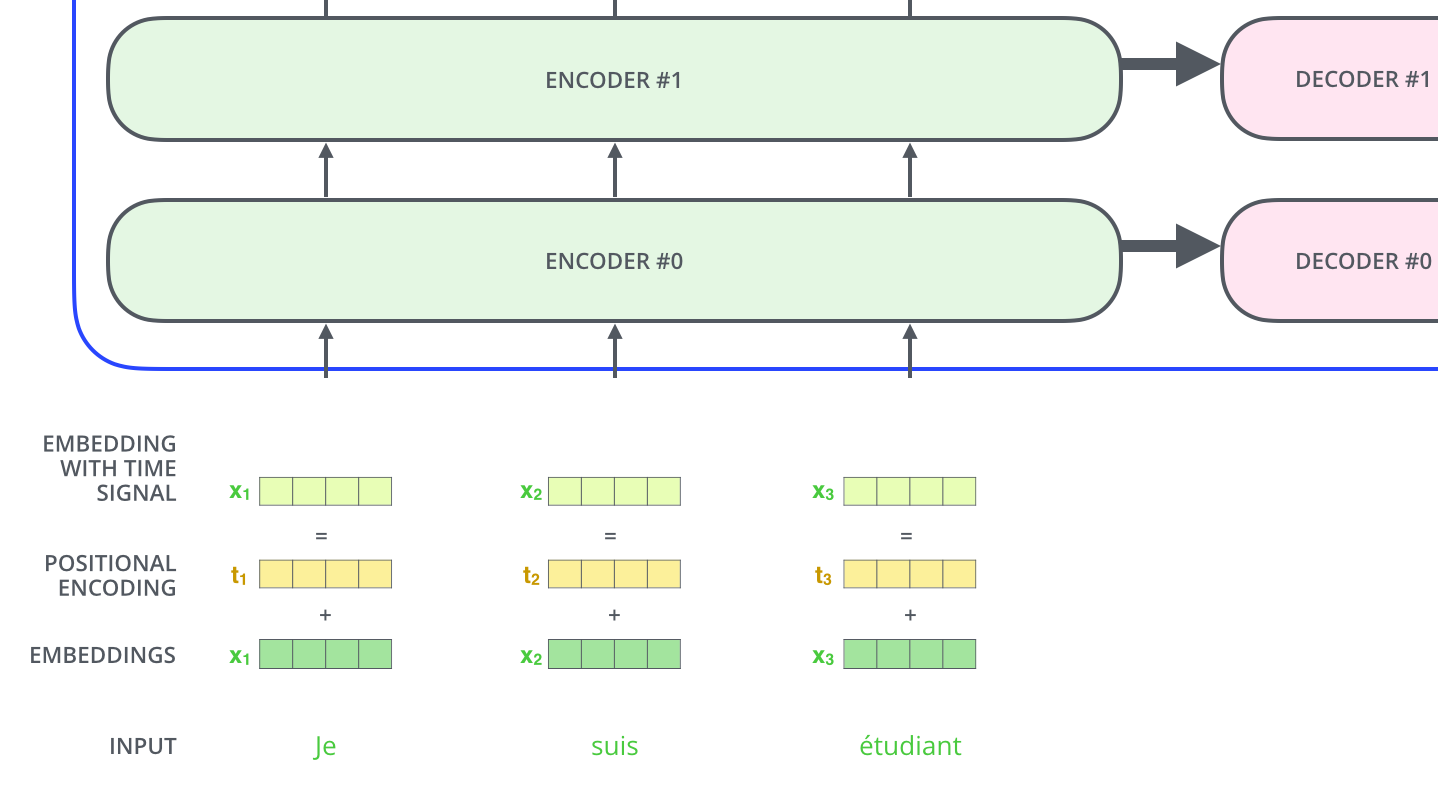
Representing The Order of The Sequence Using Positional Encoding
“One thing that’s missing from the model as we have described it so far is a way to account for the order of the words in the input sequence.”(对于同一个句子打乱之后输出同样的结果)These vectors follow a specific pattern that the model learns, which helps it determine the position of each word, or the distance between different words in the sequence. The intuition here is that adding these values to the embeddings provides meaningful distances between the embedding vectors once they’re projected into Q/K/V vectors and during dot-product attention.
这个单词顺序问题?我感觉生成的
矩阵本身不就是包括了顺序在里面吗?比如上面
To address this, the transformer adds a vector to each input embedding. 这些向量遵循特定的模式。
那么怎么编码这个位置信息呢?常见的模式有:a. 根据数据学习;b. 自己设计编码规则。在这里作者采用了第二种方式。那么这个位置编码该是什么样子呢?通常位置编码是一个长度为  的特征向量,这样便于和词向量进行单位加的操作(见上图)。
的特征向量,这样便于和词向量进行单位加的操作(见上图)。
可能我前面所提到的就是上面所说的 a
残差结构
残差结构如下图所示: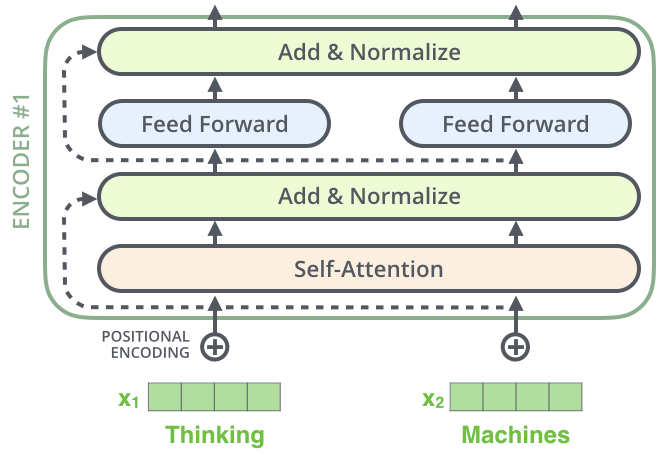
残差结构在 Decoder 中同样存在: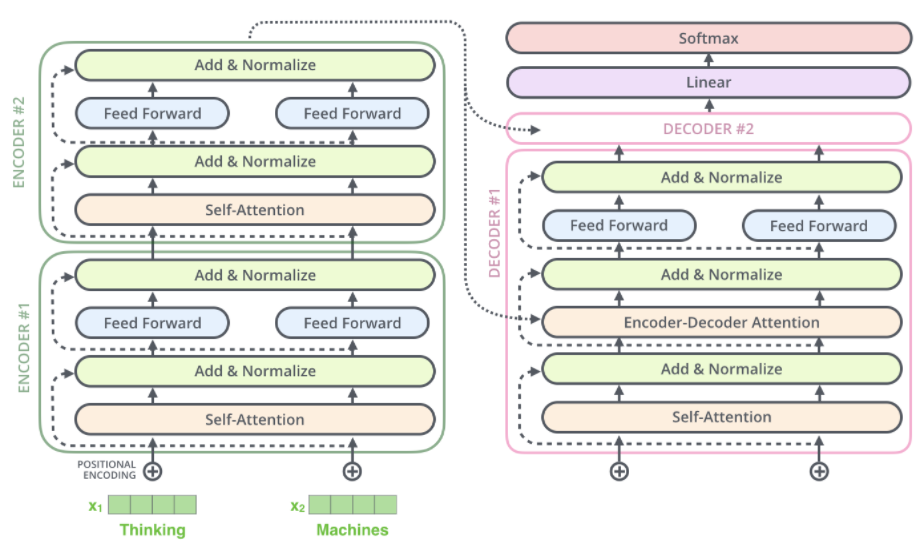
Decoder
Encoder 产生向量 list,类似于 Encoder 输入的向量 list。这些产生的向量 list,与输入一样与对应矩阵进行乘法得到向量 ,如果采用多头则参数矩阵。
,如果采用多头则参数矩阵。
所以 Decoder 的 Encoder-Decoder Attention 部分就有两个部分了,另外的  来源于上一个 Decoder 的输出(通过了 Self-Attention层)。
来源于上一个 Decoder 的输出(通过了 Self-Attention层)。
这里的 Self-Attention呢? => Self-Attention 层产生对应的
)


下面的步骤一直重复直到一个特殊符号出现表示解码器完成了翻译输出。每一步的输出被喂到下一个解码器中。正如编码器的输入所做的处理,对解码器的输入增加位置向量(看上上图,具体可以了解到位置向量在哪里加)。
文章中,Decoder 最后一层,不同 Feed-Forward 网络的输出最后转换成了一个?这样才会符合图中的一个单词一个单词的产生。
在 Decoder 中,每一个词获取时,只能访问到前面的输出结果 => masked multi-head attention.

若有收获,就点个赞吧
0 人点赞
