原论文链接: Learning spatiotemporal features with 3d convolutional networks-2015ICCV C3D github pytorch
单词汇总

介绍
本篇论文提出的C3D卷积网络是3D卷积网络的里程碑,以3D卷积核为基础的3D卷积网络从此发展起来。
之前了解了13年的一篇和3D卷积相关的论文,但是该论文中的3D卷积模型,并没有完全符合3D卷积的公式,只能算是2.5D卷积。
本文的贡献:
- 通过实验证明了3D卷积能够很好地学习时空信息;
- 通过实现发现
 卷积核效果最好;
卷积核效果最好; - 提取的特征加上简单的分类器就能够实现非常好的性能;

相关工作

Karpathy et al 在其论文中提到的 Slow Fusion 事实上和本文中的 C3D 非常类似。由于在2D卷积的论文中(VGG)有提到 的卷积核对于深层的网络效果最好,所以本文在设计卷积核大小的时候,在空间域采用的大小,时间域上面通过实验进行查找最优的 size ,最后确定为3。
的卷积核对于深层的网络效果最好,所以本文在设计卷积核大小的时候,在空间域采用的大小,时间域上面通过实验进行查找最优的 size ,最后确定为3。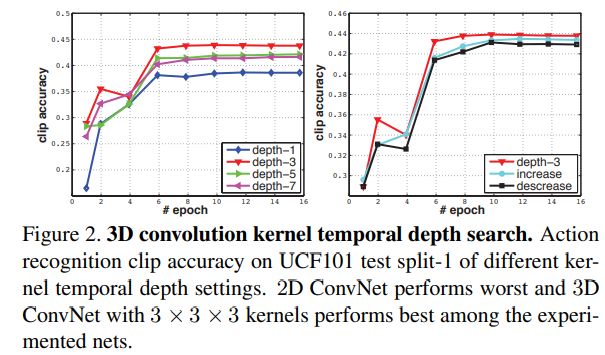
二维卷积向三维卷积拓展中合理利用二维卷积的性质来简化实验!这种思想非常重要(当然,这种借用的性质可能不是严格成立)他山之石,可以攻玉! 然后就是在网络性能对比的时候,还需要考虑网络的参数,因为通常来说参数量越大,那么网络表示能力就越强,所以在看网络性能好坏时,首先确保其参数量相差不大。
网络设置
对于三维卷积,通常表示如下:视频输入 shape 为 ,卷积核或者池化核的 shape 为
,卷积核或者池化核的 shape 为 。其中
。其中 表示数据的 channel ,
表示数据的 channel , 表示视频帧数;
表示视频帧数; 表示核在时域的跨度,
表示核在时域的跨度, 表示核在空间域的跨度。
表示核在空间域的跨度。
本文的数据视频帧的大小都被 resize 到 ,网络输入的维度为
,网络输入的维度为 ,数据输入网络之后还好采用 jittering 数据增强方式对数据随机切割为
,数据输入网络之后还好采用 jittering 数据增强方式对数据随机切割为 。网络包括5个卷积层、5个池化层(每个卷积层后面都立即跟一个池化层)、2个全连接层以及一个 softmax 损失层。
。网络包括5个卷积层、5个池化层(每个卷积层后面都立即跟一个池化层)、2个全连接层以及一个 softmax 损失层。
- 卷积核的数据从1到5层分别为:64,128,256,256,256(后面几个池化之后为何卷积核的数目没有增加?),所有卷积核的 size 都是一样的。卷积操作时在时域和空间域会进行 padding 操作,卷积过程中 stride 为 1 ,从而使得卷积操作的输入和输出 size 一样大;
- 所有的池化操作采用最大值池化,池化核大小为
 (除了第一层,第一层为
(除了第一层,第一层为 ,其目的是为了防止过早融合时序信息);
,其目的是为了防止过早融合时序信息); - 两个全连接层有2048个输出;
- 网络从0开始训练,没有选择特殊的 pre-train 方式;

若有收获,就点个赞吧
0 人点赞
