论文地址: Real-Time Human Pose Recognition in Parts from Single Depth Images 一篇复现的硕士论文: 基于深度图的实时部位识别和姿态估计技术与系统
摘要部分
- We take an object recognition approach, designing an intermediate body parts representation that maps the difficult pose estimation problem into a simpler per-pixel classification problem.
- The system runs at 200 frames per second on consumer hardware.
Introduction部分
In this paper, we focus on pose recognition in parts: detecting from a single depth image a small set of 3D position candidates for each skeletal joint.
Illustrated in Fig. 1 and inspired by recent object recognition work that divides objects into parts, our approach is driven by two key design goals: computational efficiency and robustness. A single input depth image is segmented into a dense probabilistic body part labeling, with the parts defined to be spatially localized near skeletal joints of interest. Reprojecting the inferred parts into world space, we localize spatial modes of each part distribution and thus generate (possibly several) confidence-weighted proposals for the 3D locations of each skeletal joint.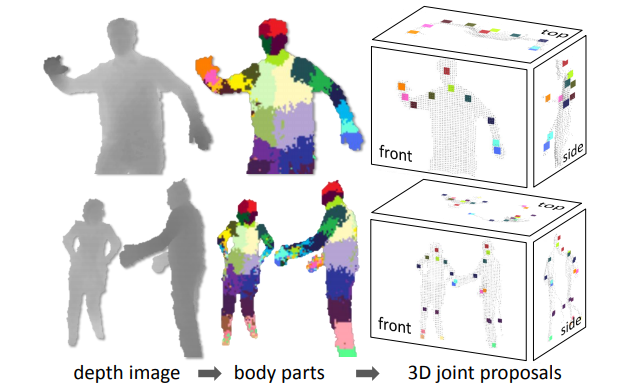
Figure 1. Overview. From an single input depth image, a per-pixel body part distribution is inferred. (Colors indicate
the most likely part labels at each pixel, and correspond in the joint proposals). Local modes of this signal are
estimated to give high-quality proposals for the 3D locations of body joints, even for multiple users.
We train a deep randomized decision forest classifier which avoids overfitting by using hundreds of thousands of training images. Simple, discriminative depth comparison image features yield 3D translation invariance while maintaining high computational efficiency. For further speed, the classifier can be run in parallel on each pixel on a GPU. Finally, spatial modes of the inferred per-pixel distributions are computed using mean shift resulting in the 3D joint proposals.
mean shift: 一种聚类算法
We demonstrate that our part proposals generalize at least as well as exact nearest-neighbor in both an idealized and realistic setting, and show a substantial improvement over the state of the art. Further, results on silhouette images suggest more general applicability of our approach.
nearest-neighbor(NN): 临近算法(类似的KNN),是一种分类器
Our main contribution is to treat pose estimation as object recognition using a novel intermediate body parts representation designed to spatially localize joints of interest at low computational cost and high accuracy. Our experiments also carry several insights: (i) synthetic depth training data is an excellent proxy for real data; (ii) scaling up the learning problem with varied synthetic data is important for high accuracy; and (iii) our parts-based approach generalizes better than even an oracular exact nearest neighbor.
相关工作部分
Data
Pose estimation research has often focused on techniques to overcome lack of training data, because of two problems. First, generating realistic intensity images using computer graphics techniques is hampered by the huge color and texture variability induced by clothing, hair, and skin, often meaning that the data are reduced to 2D silhouettes. Although depth cameras significantly reduce this difficulty, considerable variation in body and clothing shape remains. The second limitation is that synthetic body pose images are of necessity fed by motion-capture (mocap) data. Although techniques exist to simulate human motion, they do not yet produce the range of volitional motions of a human subject.
Depth imaging
Depth cameras offer several advantages over traditional intensity sensors, working in low light levels, giving a calibrated scale estimate, being color and texture invariant, and resolving silhouette ambiguities in pose. They also greatly simplify the task of background subtraction which we assume in this work. But most importantly for our approach, it is straightforward to synthesize realistic depth images of people and thus build a large training dataset cheaply.
Motion capture data
The database consists of approximately 500k frames in a few hundred sequences of driving, dancing, kicking, running, navigating menus, etc.
We expect our semi-local body part classifier to generalize somewhat to unseen poses. In particular, we need not record all possible combinations of the different limbs; in practice, a wide range of poses proves sufficient. Further, we need not record mocap with variation in rotation about the vertical axis, mirroring left-right, scene position, body shape and size, or camera pose, all of which can be added in (semi-)automatically.
Since the classifier uses no temporal information, we are interested only in static poses and not motion. Often, changes in pose from one mocap frame to the next are so small as to be insignificant. We thus discard many similar, redundant poses from the initial mocap data using ‘furthest neighbor’ clustering where the distance between poses  and
and  is defined as
is defined as  , the maximum Euclidean distance over body joints
, the maximum Euclidean distance over body joints  . We use a subset of 100k poses such that no two poses are closer than 5cm.
. We use a subset of 100k poses such that no two poses are closer than 5cm.
furthest neighbor: 与最临近相比,距离定义为最大差值
(Our early experiments employed the CMU mocap database which gave acceptable results though covered far less of pose space.)
Generating synthetic data
We build a randomized rendering pipeline from which we can sample fully labeled training images. Our goals in building this pipeline were twofold: realism and variety.
For the learned model to work well, the samples must closely resemble real camera images, and contain good coverage of the appearance variations we hope to recognize at test time. While depth/scale and translation variations are handled explicitly in our features (see below), other invariances cannot be encoded efficiently. Instead we learn invariance from the data to camera pose, body pose, and body size and shape.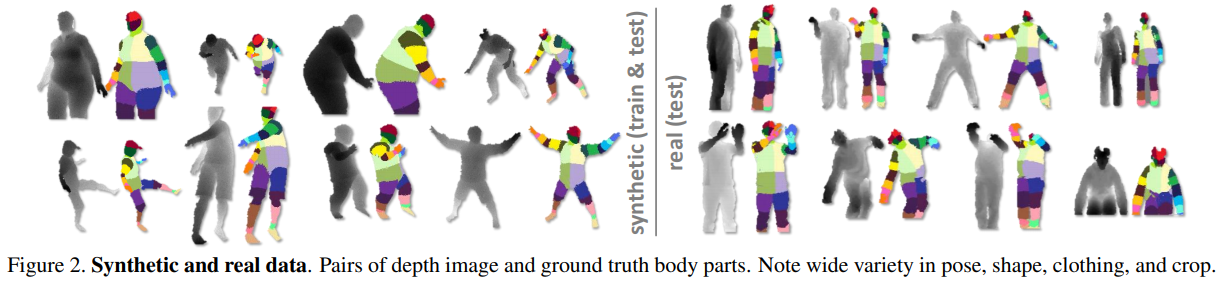
The synthesis pipeline first randomly samples a set of parameters, and then uses standard computer graphics techniques to render depth and (see below) body part images from texture mapped 3D meshes.
Body Part Inference and Joint Proposals
In this section we describe our intermediate body parts representation, detail the discriminative depth image features, review decision forests and their application to body part recognition, and finally discuss how a mode finding algorithm is used to generate joint position proposals.
Body part labeling
A key contribution of this work is our intermediate body part representation.
We define several localized body part labels that densely cover the body, as color-coded in Fig. 2. Some of these parts are defined to directly localize particular skeletal joints of interest, while others fill the gaps or could be used in combination to predict other joints. Our intermediate representation transforms the problem into one that can readily be solved by efficient classification algorithms; we show in Sec. 4.3 that the penalty paid for this transformation is small.
The parts are specified in a texture map that is retargetted to skin the various characters during rendering. The pairs of depth and body part images are used as fully labeled data for learning the classifier (see below).
Distinct parts for left and right allow the classifier to disambiguate the left and right sides of the body.
一共有31个关节点
Depth image features
We employ simple depth comparison features, inspired by those in [20]. At a given pixel  , the features compute
, the features compute
where  is the depth at pixel
is the depth at pixel  in image
in image  , and parameters
, and parameters  describe offsets
describe offsets  and
and  . The normalization of the offsets by
. The normalization of the offsets by  ensures the features are depth invariant: at a given point on the body, a fixed world space offset will result whether the pixel is close or far from the camera. The features are thus 3D translation invariant (modulo perspective effects). If an offset pixel lies on the background or outside the bounds of the image, the depth probe
ensures the features are depth invariant: at a given point on the body, a fixed world space offset will result whether the pixel is close or far from the camera. The features are thus 3D translation invariant (modulo perspective effects). If an offset pixel lies on the background or outside the bounds of the image, the depth probe  is given a large positive constant value.
is given a large positive constant value.
公式意思?
Fig. 3 illustrates two features at different pixel locations . Feature  looks upwards: Eq. 1 will give a large positive response for pixels near the top of the body, but a value close to zero for pixels lower down the body. Feature
looks upwards: Eq. 1 will give a large positive response for pixels near the top of the body, but a value close to zero for pixels lower down the body. Feature  may instead help find thin vertical structures such as the arm.
may instead help find thin vertical structures such as the arm.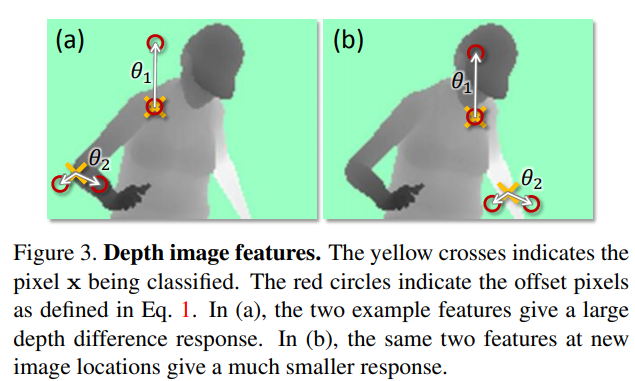
Individually these features provide only a weak signal about which part of the body the pixel belongs to, but in combination in a decision forest they are sufficient to accurately disambiguate all trained parts. The design of these features was strongly motivated by their computational efficiency: no preprocessing is needed; each feature need only read at most 3 image pixels and perform at most 5 arithmetic operations; and the features can be straightforwardly implemented on the GPU. Given a larger computational budget, one could employ potentially more powerful features based on, for example, depth integrals over regions, curvature, or local descriptors e.g. [5].
Randomized decision forests
Randomized decision trees and forests have proven fast and effective multi-class classifiers for many tasks [20, 23, 36], and can be implemented efficiently on the GPU. As illustrated in Fig. 4, a forest is an ensemble of  decision trees, each consisting of split and leaf nodes. Each split node consists of a feature
decision trees, each consisting of split and leaf nodes. Each split node consists of a feature  and a threshold
and a threshold  . To classify pixel in image , one starts at the root and repeatedly evaluates Eq. 1, branching left or right according to the comparison to threshold . At the leaf node reached in tree
. To classify pixel in image , one starts at the root and repeatedly evaluates Eq. 1, branching left or right according to the comparison to threshold . At the leaf node reached in tree  , a learned distribution
, a learned distribution  over body part labels
over body part labels  is stored. The distributions are averaged together for all trees in the forest to give the final classification
is stored. The distributions are averaged together for all trees in the forest to give the final classification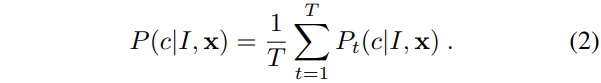
Training. Each tree is trained on a different set of randomly synthesized images. A random subset of 2000 example pixels from each image is chosen to ensure a roughly even distribution across body parts. Each tree is trained using the following algorithm [20]:
- Randomly propose a set of splitting candidates
 (feature parameters
(feature parameters  and thresholds
and thresholds  ).
). - Partition the set of examples
 into left and right subsets by each
into left and right subsets by each  :
:
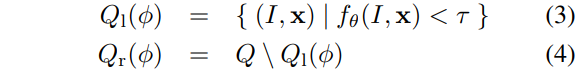
- Compute the giving the largest gain in information:
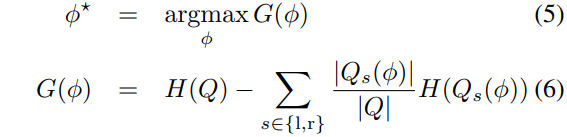
where Shannon entropy  is computed on the normalized histogram of body part labels
is computed on the normalized histogram of body part labels  for all
for all  .
.
- If the largest gain
 is sufficient, and the depth in the tree is below a maximum, then recurse for left and right subsets
is sufficient, and the depth in the tree is below a maximum, then recurse for left and right subsets  and
and  .
.

To keep the training times down we employ a distributed implementation. Training 3 trees to depth 20 from 1 million images takes about a day on a 1000 core cluster.
Joint position proposals
Body part recognition as described above infers per-pixel information. This information must now be pooled across pixels to generate reliable proposals for the positions of 3D skeletal joints.
A simple option is to accumulate the global 3D centers of probability mass for each part, using the known calibrated depth. However, outlying pixels severely degrade the quality of such a global estimate. Instead we employ a local mode-finding approach based on** mean shift with a weighted Gaussian kernel**.
We define a density estimator per body part as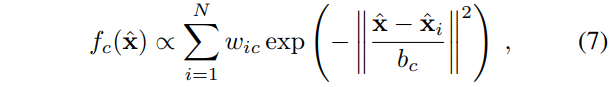
where  is a coordinate in 3D world space,
is a coordinate in 3D world space,  is the number of image pixels,
is the number of image pixels,  is a pixel weighting,
is a pixel weighting,  is the reprojection of image pixel
is the reprojection of image pixel  into world space given depth
into world space given depth  , and
, and  is a learned per-part bandwidth. The pixel weighting considers both the inferred body part probability at the pixel and the world surface area of the pixel:
is a learned per-part bandwidth. The pixel weighting considers both the inferred body part probability at the pixel and the world surface area of the pixel: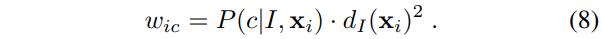
This ensures density estimates are depth invariant and gave a small but significant improvement in joint prediction accuracy. Depending on the definition of body parts, the posterior  can be pre-accumulated over a small set of parts. For example, in our experiments the four body parts covering the head are merged to localize the head joint.
can be pre-accumulated over a small set of parts. For example, in our experiments the four body parts covering the head are merged to localize the head joint.
Mean shift is used to find modes in this density efficiently. All pixels above a learned probability threshold  are used as starting points for part . A final confidence estimate is given as a sum of the pixel weights reaching each mode. This proved more reliable than taking the modal density estimate.
are used as starting points for part . A final confidence estimate is given as a sum of the pixel weights reaching each mode. This proved more reliable than taking the modal density estimate.
The detected modes lie on the surface of the body. Each mode is therefore pushed back into the scene by a learned  offset
offset  to produce a final joint position proposal. This simple, efficient approach works well in practice. The bandwidths , probability threshold , and surface-to-interior offset are optimized per-part on a hold-out validation set of 5000 images by grid search. (As an indication, this resulted in mean bandwidth 0.065m, probability threshold 0.14, and z offset 0.039m).
to produce a final joint position proposal. This simple, efficient approach works well in practice. The bandwidths , probability threshold , and surface-to-interior offset are optimized per-part on a hold-out validation set of 5000 images by grid search. (As an indication, this resulted in mean bandwidth 0.065m, probability threshold 0.14, and z offset 0.039m).
Experiments
问题
没有数据集…

若有收获,就点个赞吧
0 人点赞
