论文地址:Joint Training of a Convolutional Network and a Graphical Model for Human Pose Estimation 参考代码:https://github.com/max-andr/joint-cnn-mrf 作者名称:Jonathan Tompson, Arjun Jain, Yann LeCun, Christoph Bregler MRF参考:
介绍
人体姿态估计的困难之处:Complex joint inter-dependencies, partial or full joint occlusions, variations in body shape, clothing or lighting, and unrestricted viewing angles result in a very high dimensional input space, making naive search methods intractable(关节点依赖、遮挡,人体形状、服饰、光照的变换,拍摄的角度等)
传统的方式是通过 deformable part models(DPM),通过设计部件检测器,是一种自底向上的检测方法(all these approaches suffer from the fact that they use hand crafted features such as HoG features, edges, contours, and color histograms)。并且传统方法采用一些诸如HOF、SHIFT之类的低维度的简单特征。深度学习通过对样本进行学习,学习到了一些高维特征,这些高维特征对于光照等变换更为鲁棒,但是其对于人体结构的先验知识的融入不能像传统方法那样直观。
However, incorporating priors about the structure of the human body (such as our prior knowledge about joint inter-connectivity) into such networks is difficult since the low-level mechanics of these networks is often hard to interpret.
本文希望,综合传统的方法和深度学习方法,来实现对关节点的检测。如此的话,框架就主要由Part-Detector和Spatial-Model两部分组成。
In this work we attempt to combine a Convolutional Network (ConvNet) Part-Detector – which alone outperforms all other existing methods – with a part-based Spatial-Model into a unified learning framework.
相关工作
目前能够取得state-of-art的工作是基于深度学习的方法,比如DeepPose,However, their method suffers from inaccuracy in the high-precision region, which we attribute to inefficient direct regression of pose vectors from images, which is a highly non-linear and difficult to learn mapping.(直接回归是低效的,它是一个高度非线性的过程)
CNN虽然理论上能够拟合一切的非线性函数,但是,其更偏爱于线性问题。直接回归的非线性过程主要体现在全连接层,全连接层直接将空间信息重新排列,是的空间顺序变得不那么直观。
本文的模型
Convolutional Network Part-Detector
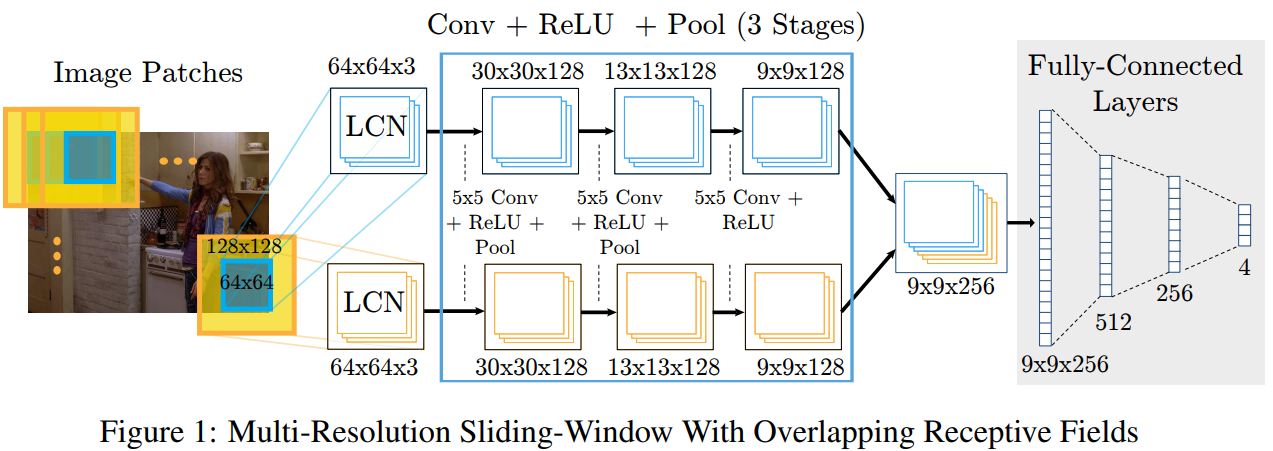
- 网络分为两支,上面一支以
大小的分辨率作为输入;下面一支以
分辨率经过下采样到
- 滑动窗口遍历图像时,窗口具有重叠。The advantage of using overlapping contexts is that it allows the network to see a larger portion of the input image with only a moderate increase in the number of weights.(???)
- 输入的图像首先经过一个LCN(Local Contrast Normalized)模块,利用LCN来产生近似的Laplace金字塔。(前面查到LCN貌似是对局部区域进行归一化处理???)The role of the Laplacian Pyramid is to provide each bank with non-overlapping spectral content(谱分析角度?)which minimizes network redundancy.
The first stage of our detection pipeline is a deep ConvNet architecture for body part localization. The input is an RGB image containing one or more people and the output is a heat-map, which produces a per-pixel likelihood for key joint locations on the human skeleton.
滑动窗口的优势:检测器具有平移不变性;劣势:具有冗余的卷积运算从而使得计算量大(特别是为了检测不同尺度的目标时问题尤其严重)为了解决这个问题可以采用目前主流的CNN架构进行特征的提取,例如下面所示的single resolution bank。(但是这是单尺度的架构)
这里所说的滑动窗口策略的冗余计算体现在何处?窗口内部每一次都需要进行“一整套”的计算。也就是说,滑动窗口滑动一下,那么对其内部的信息就通过网络进行一次计算得到其特征表示。类似于之前看到的基于HOG和SVM进行汽车检测的项目,这种方法从局部进行入手,不能整体把握整张图的信息。
但是基于CNN的方式是直接对整张图进行卷积,减少了很多的计算量,并且随着网络的深入我们越能把握图像整体的特征。后续我们对目标的检测也是从这个整体的特征入手。(与目标检测领域非常类似)
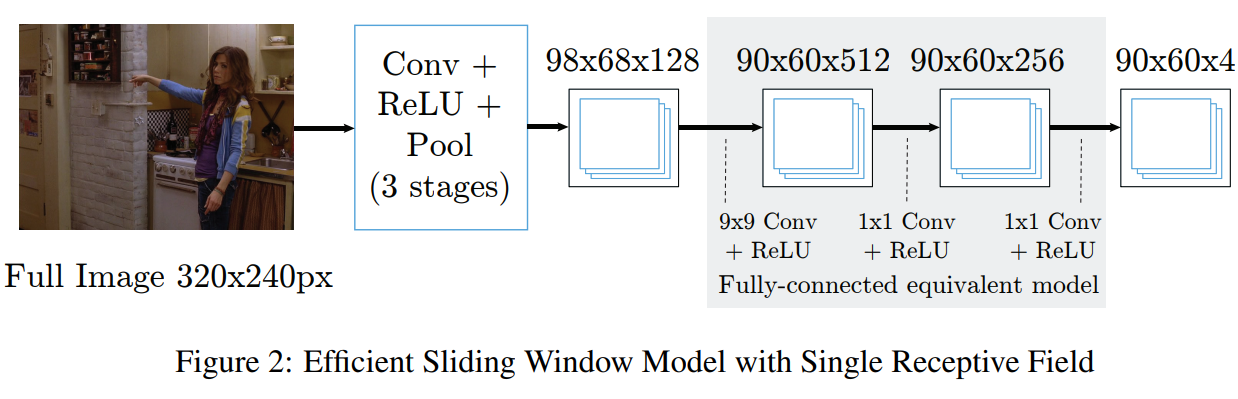
作者希望将图二中的更加高效的滑动窗口模型和多尺度已经重叠感受野进行组合,从而提出了下面所示的架构。并且为了与最前面的滑动窗口策略产生相同的Dense output,在低分辨率的bank需要处理四张下采样的图像(最前面的滑动窗口策略对应到下采样的图像,卷积步长应该为1/2;但是步长为1/2难以实现,所以采用4个下采样的图像进行近似表示?)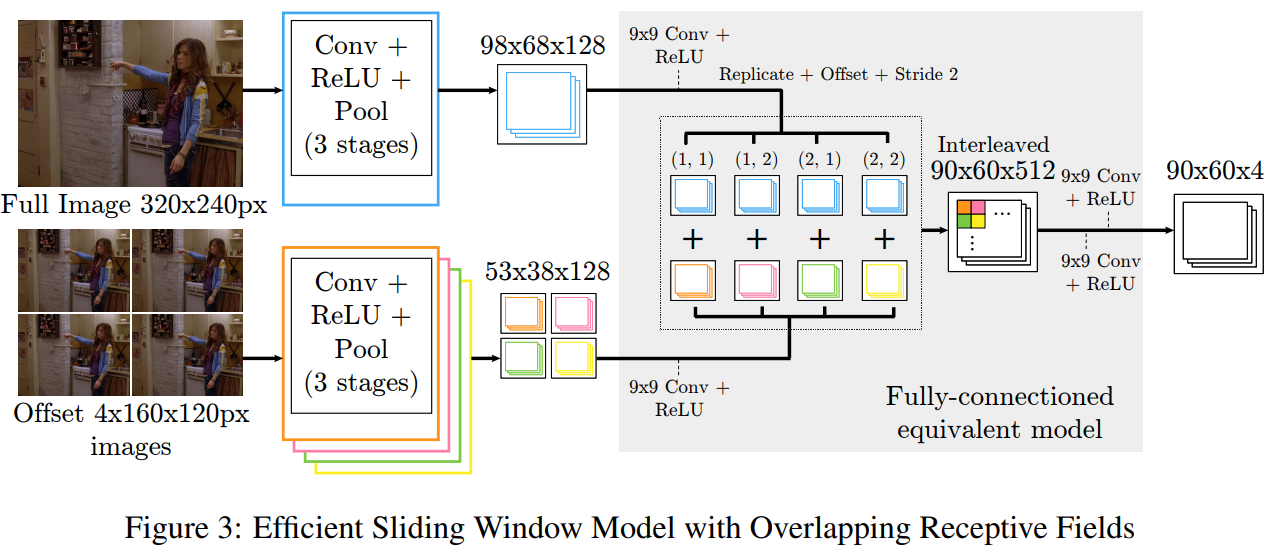
为了进一步简化训练的过程,作者直接将下面的低分辨率bank中的,为了与最原始的滑动窗口策略进行匹配的四张下采样图利用一张图进行替代。但是在后续过程有一个上采样的过程。从而产生最终的Part-Detector架构。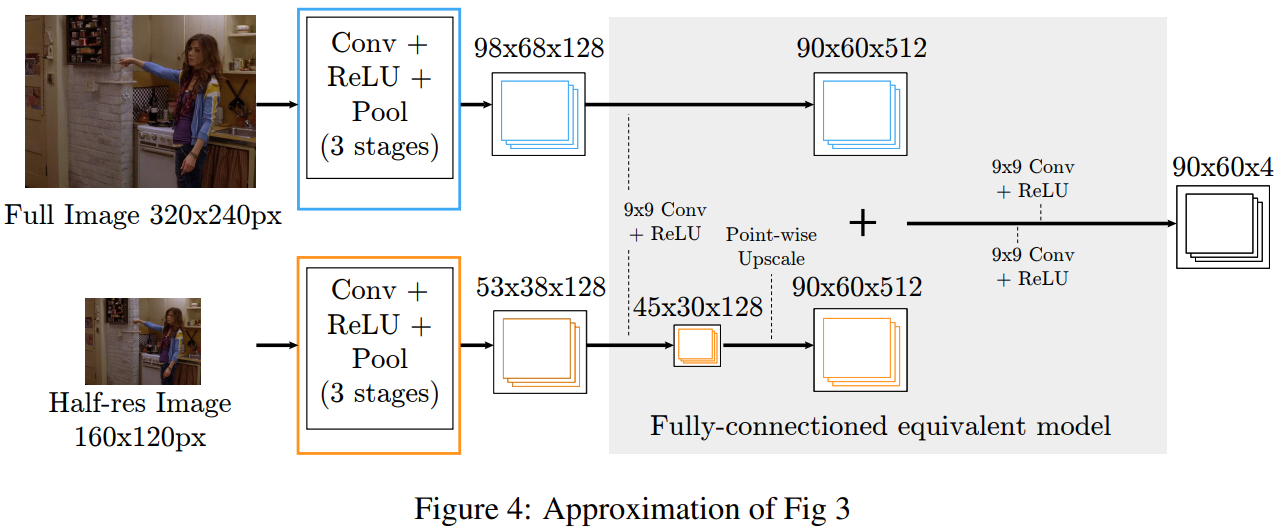
这种架构在目前来说是非常普通、常见的架构。但是在作者当时的时代背景下,这是一个从传统滑动窗口过渡到CNN的方法,所以在对网络架构的讨论非常详细,很好地展示了作者思考过程。
Higher-Level Spatial-Model
单单使用Part-Detector地话,得到的heatmap(不知这里的heatmap和后续主流的有没有区别?)往往包括很多的false positives以及不符合人体结构特征的结果,作者认为这是前馈网络难以学到身体各部位的身体部位约束的隐式模型。这从而引出了后面地Spatial-Model。
Therefore, in spite of the improved Part-Detector context, the feed forward network still has difficulty learning an implicit model of the constraints of the body parts for the full range of body poses. We use a higher-level Spatial-Model to constrain joint inter-connectivity and enforce global pose consistency. (虽然出现了很多不正确的检测结果,但是CNN网络还是能够检测到很多正确的结果的,也能对人体的结构信息进行一定的把握)
Spatial-Model的目的是去除掉那些false positives的结果(并不会改善检测器的检测结果)
Spatial-Model被建模为类似MRF(马尔可夫随机场)的模型(参考前人的工作),However, the biggest drawback of their model is that the body part priors and the graph structure are explicitly hand crafted. On the other hand, we learn the prior model and implicitly the structure of the spatial model.
graph structure是用来对人体结构进行建模的(尚未了结这具体是干嘛的?),对于这张图的构建,作者直接采用全连接,每个节点和其它节点都有连接,并且每个节点还有自连接。(后续补充:也就是将整个图,建模成一个“极大团”)
we start by connecting every body part to itself and to every other body part in a pair-wise fashion in the spatial model to create a fully connected graph.
之后作者将Part-Detector检测的heatmap结果作为先验知识进行概率建模。(直接上原文)
The Part-Detector provides the unary potentials for each body part location. The pair-wise potentials in the graph are computed using convolutional priors, which model the conditional distribution of the location of one body part to another._
以下通过一个例子进行说明:假设关节点 位于图像中心,convolution prior
位于图像中心,convolution prior 是关节点
是关节点 位于
位于 的概率。那么关节点的边际似然
的概率。那么关节点的边际似然 ,计算如下:
,计算如下: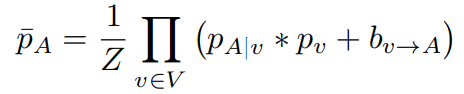
- 公式中的
表示所有与
- 其中的
是一个偏差项,用来描述
到
would prevent the output heat-map from having no maxima in the detected face region.(???)
是分配函数(类似于权值函数之类的,规范化???yes,在MRF模型中其为规范化因子)
- (后续补充)公式的理解需要借助作者前面提到的MRF模型。
只要有了条件概率,那么我们就可以通过关节点之间的关系来过滤掉一些多余的检测结果,如下图所示: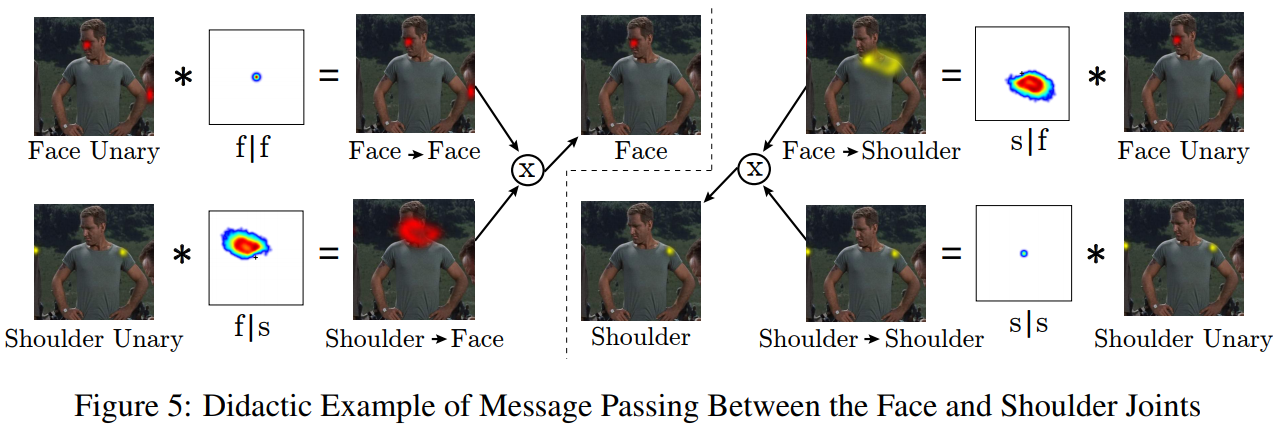
- 图中展示的是(face,shoulder)对之间的约束,通过条件概率来进行关节点的滤除。这种方式可以扩展到所有的关节点对之间
- The learned pair-wise distributions are purely uniform when any pairwise edge should to be removed from the graph structure
那么关键是如何来求取这个条件概率分布?
Fig 5 contains the conditional distributions for face and shoulder parts learned on the FLIC [27] dataset. 所以这个概率分布事实上是在数据集上学习到的。
For our practical implementation we treat the distributions above as energies to avoid the evaluation of . 作者列举了三个不考虑的原因,但是对于我还没有具体明白它是干嘛的,所以那三个原因也不是很能理解。
最终模型表示为: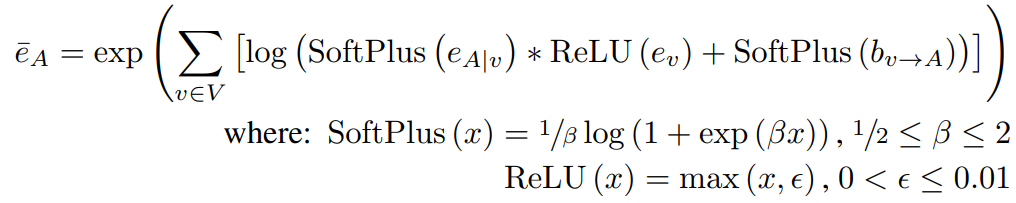
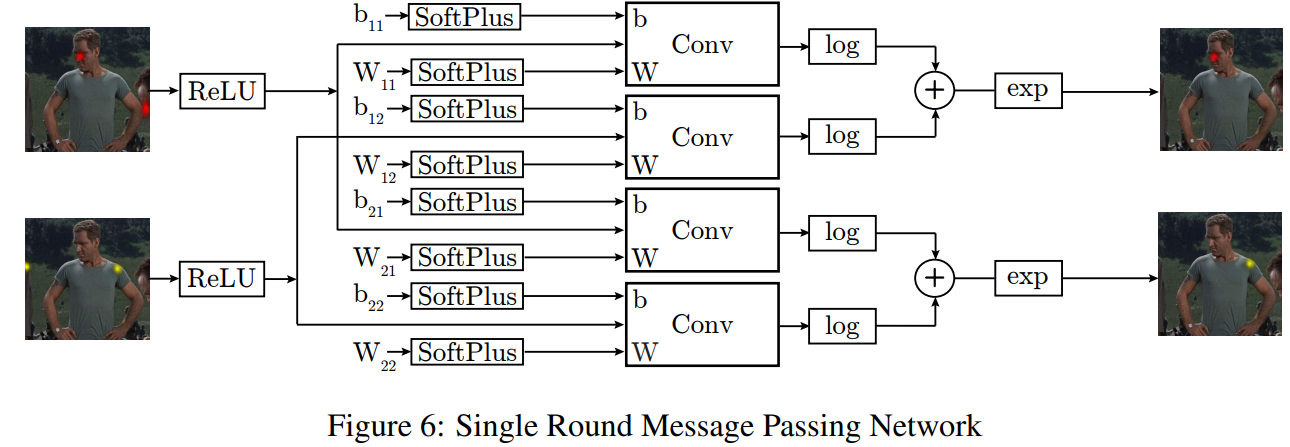
从上图来看应该是:数学模型指导如何构建卷积模型 对于MRF的建模需要在掌握MRF之后,继续来理解其中的含义
Unified Model
Since our Spatial-Model is trained using back-propagation, we can combine our PartDetector and Spatial-Model stages in a single Unified Model. To do so, we first train the PartDetector separately and store the heat-map outputs. We then use these heat-maps to train a SpatialModel. Finally, we combine the trained Part-Detector and Spatial-Models and back-propagate through the entire network.
结果
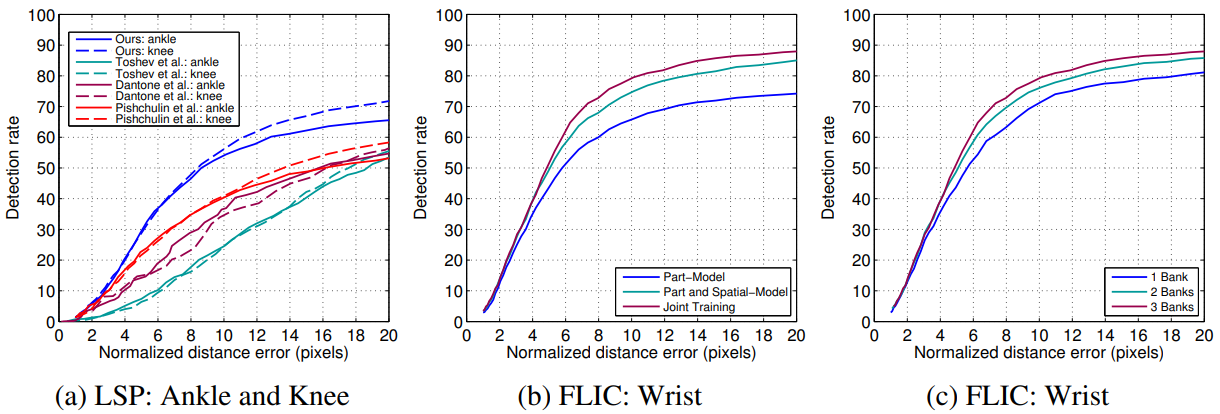
曲线非常完美,得出的结论也非常的完美


若有收获,就点个赞吧
0 人点赞
