原文链接:https://arxiv.org/pdf/1711.07971.pdf Pytorch 代码参考:https://github.com/AlexHex7/Non-local_pytorch
Abstract
Both convolutional and recurrent operations are building blocks that process one local neighborhood at a time. In this paper, we present non-local operations as a generic family of building blocks for capturing long-range dependencies. Inspired by the classical non-local means method [4] in computer vision, our non-local operation computes the response at a position as a weighted sum of the features at all positions. This building block can be plugged into many computer vision architectures. On the task of video classification, even without any bells and whistles, our nonlocal models can compete or outperform current competition winners on both Kinetics and Charades datasets. In static image recognition, our non-local models improve object detection/segmentation and pose estimation on the COCO suite of tasks.
Non-local means
很多的去噪方法都是利用局部信息进行去噪:假设噪声满足标准正态分布,那么噪声期望(离散求和)将为 0,所以将局部区域的信息进行求取均值将降低噪声的干扰(假设局部区域内图像信息近似为常量)。通常来说,像局域区域越大(保证内部的信息变化很小)那么去噪效果越好,所以有些去噪算法就脱离局部信息,从而结合多张图的信息或者一张图的不同相似块进行综合去噪,这种方法相对于局域去噪效果更好(毕竟区域大了,求和式结果更接近真实的均值)
NL-Means 方法: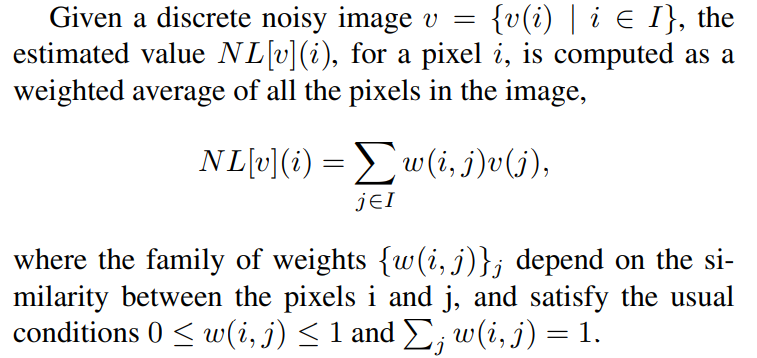
相似度定义如下,相似度以一个邻域进行定义(第二个公式中其中一个 i 为 j):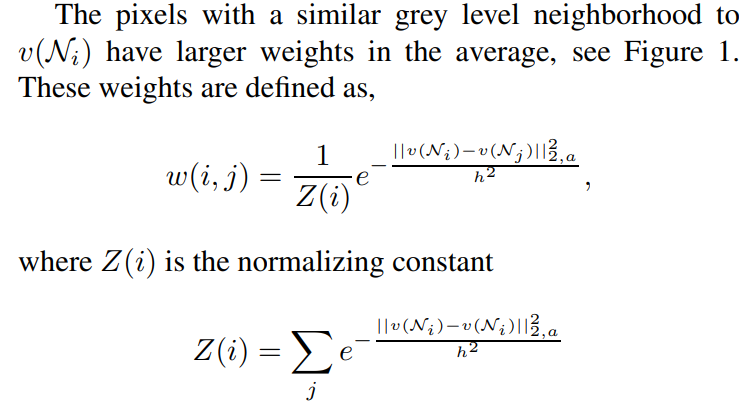

Feedforward modeling for sequences.
Recently there emerged a trend of using feedforward (i.e., non-recurrent) networks for modeling sequences in speech and language. In these methods, long-term dependencies are captured by the large receptive fields contributed by very deep 1-D convolutions. These feedforward models are amenable to parallelized implementations and can be more efficient than widely used recurrent models.
Self-Attention 机制
- 通过输入数据变换得到,Q,K,V;
- Q,K 作用产生权值 W;
- W 对 V 进行加权,产生最终 attention 结果。
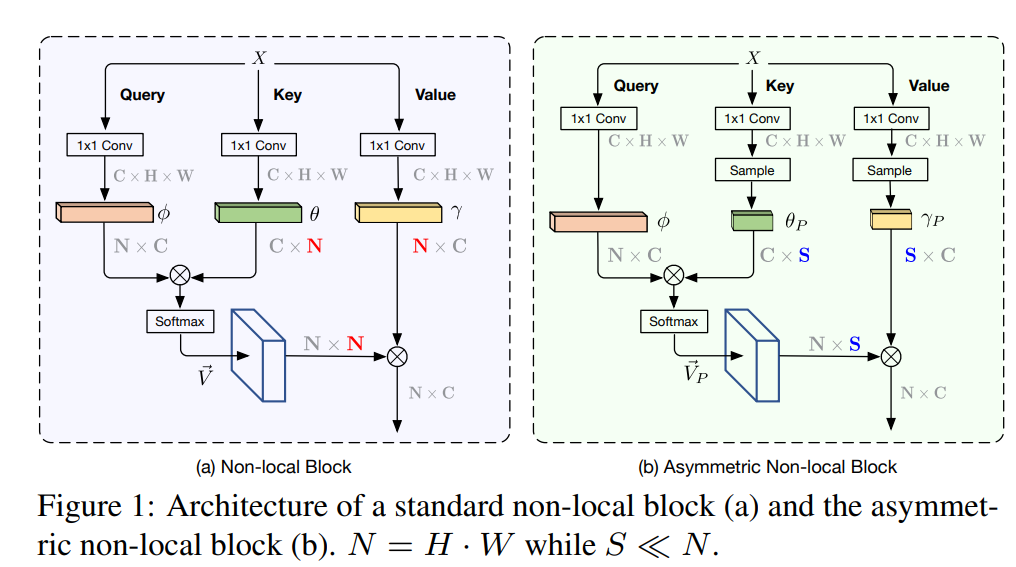
本文的 non-local 和 self-attention 机制非常像,如下图所示:

- 每个像素点的值在通过 non-local block 计算之后将得到全局的信息,从而对长时或者远距信息进行关联;
- 与常见的 self-attention 相比,non-local 是其泛化版本;
- 最大缺点时:计算量非常大!
解决计算量大
为了解决计算量大的问题,后面有改进论文:

以及
AANet: Asymmetric Non-local Neural Networks for Semantic Segmentation https://hub.fastgit.org/MendelXu/ANN


若有收获,就点个赞吧
0 人点赞
