单独编译
C++允许甚至鼓励程序员将组件函数放在独立文件中。可以单独编译这些文件,然后将它们链接成可执行文件。(通常C++编译器既编译程序,也管理链接器)当一个文件被修改时,只需要重新编译该文件即可,然后与其它文件的编译版本进行链接。这使得大程序的管理更便捷。另外大多数C++环境都提供了其它工具来帮助管理。例如UNIX和Linux的make程序,可以跟踪程序依赖的文件以及这些文件的最后修改时间。运行make时,如果它检测到上次编译后修改了源文件,make将记住重新构建程序所需的步骤。
文件组织
设想你自己编写了一个用于数学计算的函数,该函和main函数放在了同一个文件里。此时如果想将数学函数和main函数分作两个文件:main函数一个,数学函数原型及定义一个。如果在main函数中包括了数学函数的调用,将无法单独编译包括main函数的文件,因为编译时找不到被调函数。为了解决这个问题可以用#include。
在上述两个文件的基础上,设想一种情况,如果又有第三文件也需要调用数学函数,那么其又要使用#include将其包括进来,则同一个程序将包含同一个函数的两个定义(参数等完全相同,不可能是重载),除非是内联函数,否则会出错!
对于多次包含的问题,可以将数学函数原型和定义分为两个文件的方式解决:一个函数头文件(里面包括函数原型),一个函数实现。每次#include包含头文件即可。这两个文件组成软件包,可用于各种程序中。
头文件常包含内容
- 函数原型;
- 使用
#define或const定义的符号常量;(特殊的链接属性) - 结构声明;(不定义结构,只是告诉编译器如何创建该结构变量)
- 类声明;
- 模板声明;(注意模板声明不会定义函数)
- 内联函数;(特殊的链接属性)
头文件不包括函数定义,防止函数重复定义看懂了;结构声明等如何理解呢?(以下的代码也许可以提供一个浅显的认识?不是很明白)
struct hello;struct hello;template<class T>int www(T a, T b);template<class T>int www(T a, T b);struct hello{/* data */};
以上代码是能够通过编译的,但是如下代码会报错:重复定义!
struct hello{/* data */};struct hello{/* data */};// 或者template<class T>int www(T a, T b){int x = 100;return x;}template<class T>int www(T a, T b){int x = 100;return x;}
虽然上面的代码在一个文件里面将代码写了两遍,看起来错误很明显,但是多文件包括头文件,如果头文件里面有已经被定义的函数,同样与之是一个道理(重复定义),会报错!
亟待补充!!!(尤其是编译工具编译大项目相关的知识!!!)
但是:
- 头文件包括结构体、模板不会报错: ```cpp // test.h struct hello { / data / };
template
- 头文件包括函数定义会报错(重复定义):```cppvoid print(){;};
避免重复定义
同一个文件中,同一个头文件只能包括一次,但是有的时候很可能在不知情的情况将其包括多次。例如,可能使用了包含了另外一个头文件的头文件。以下的预编译指令可以解决这个问题。(避免头文件多次包括,事实上就是避免由于头文件重复包括带来的重复定义;重复定义不可以,但是重复声明却可以,并且如果两次声明参数列表不同则会产生重载)
// coordin.h#ifndef COORDIN_H_#define COORDIN_H_struct polar{double distance;double angle;};struct rect{double x;double y;};polar rect_to_polar(rect xypos);void show_polar(polar dapos);#endif
#ifndef COORDIN_H_,#define COORDIN_H_和#endif,搭配使得编译时#ifndef COORDIN_H_和#endif之间的内容只编译一次!借助此方式,可以避免重复定义结构体,同一个文件多次包括同一个头文件带来的错误等。
不同编译器创建的二进制模块很可能无法正确链接(不同编译器名称修饰可能存在差异)
存储持续性、作用域和链接性
C++使用四种不同方案来存储数据:
- 自动储存持续性:函数定义中声明的变量;它们在执行函数或者代码块时被创建,结束之后被销毁。
- 静态存储持续性:在函数定义外定义的和使用关键字static修饰的。他们在程序运行过程都存在。
- 线程存储持续性:适用于多核处理器,这些CPU可同时处理多个执行任务。如果变量时thread_local修饰的,则其生命周期与所属线程一样长。
动态存储持续性:使用new和delete进行操作。存储在堆中。
作用域和链接
作用域描述了名称在文件(翻译单元)的多大范围内可见。例如函数中定义的变量可在该函数中使用,但不能在其它函数中使用;而在文件中的函数定义之前的名称可在所有函数中使用。
链接性描述了名称如何在不同单元间共享。链接性为外部的名称可在文件间共享。链接性为内部的名称只能由一个文件中的函数共享。自动变量的名称没有链接性,因为它们不能共享。
C++变量作用域有很多种:局部:只在定义它的代码块中可用,比如说自动变量。代码块是由花括号括起的一系列语句。函数体就是代码块,代码块中可嵌入其它代码块。
- 全局:全局也称为文件作用域。全局变量在文件定义位置到文件结尾之间都可用。静态变量的作用域是全局还是局部取决于它是如何定义的,定义在函数体之外的静态变量作用域是全局的,定义在函数里面用static修饰的是局部的。
- 函数原型作用域:函数原型中使用的名称值在包含参数列表的括号内可用,这也是为什么函数原型参数列表中的名称是什么已经是否出现并不重要的原因。
- 类中声明的成员的作用域为整个类。
- 名称空间声明的变量作用域为整个名称空间。
注:值得注意的是C++中的函数作用域可以是整个类或者整个名称空间,但不能是局部的。因为代码块中定义的函数作用域为该代码块,则其只对自己可见,不能被其它函数调用!(由此可以看到,函数名称和变量名称有一定的相似性,定义函数和定义变量效果有同工之处)
不同的C++存储方式通过存储持续性、作用域和链接性来描述。
自动存储持续性
默认情况下,函数中声明的函数参数和变量的储存持续性为自动,作用域为局部,没有链接性。
- 不同函数同名变量:定义在main()中和oil()中的同名变量会分别创建,并且只有定义他们的函数才能使用他们;
- 相同函数不同代码块同名变量:如下面的例子所示,代码块内部的能够访问代码块外部的变量,但是代码块外部的不能访问内部的。当内部和外部变量重复时,将以内部的变量为准。(还要注意到代码时顺序执行的,在第一个cout中,代码块内部的abc还没有定义)
说白了就是:外部可见,内部不可见(内外部:花括号决定)
int main(){int abc = 10; // #1{cout << abc << endl; // #1int abc = 20; //#2cout << abc << endl; // #2}cout << abc << endl; // #1}
自动变量和栈
自动变量的数目随函数的开始和结束而增减,因此需要对其进行管理。常用的方法时留出一段空间,将其视作栈,以管理变量的增减。
寄存器变量
目前的C++ register的含义已经发生了变化,不再表示寄存器变量,其效果是:显式指出变量是自动的。
register int cout_fast;
静态持续变量
C++为静态持续变量提供了3种链接性:外部链接性(可在其它文件中访问)、内部链接性(当前文件可访问)和无链接性(只能在当前函数或者代码块访问)。这三种链接性都在整个程序执行期间存在。由于静态变量的数目在程序执行期间不会发生变化,因此程序不需要使用特殊的装置来管理他们,编译器将分配固定的内存块来储存所有的静态变量。没有显式初始化的静态变量,默认值为0。
三种链接性静态变量创建方式如下:外部链接:在代码块外面声明它;
- 内部链接:在代码块外面声明它,并利用static修饰;
- 无链接:代码块内部声明,并用static修饰;
注:两种链接都是用static修饰,但是效果完全不同,其结合具体的上下文决定含义,有人称之为关键字重载。
int global = 1000; // 外部链接static int one_file = 50; // 内部链接int main{//...}void func1(int n){static int n = 0; // 无链接}
静态持续性、外部链接性
单定义规则
一方面,在每个使用外部变量的文件中,都必须声明它;另一方面,C++有“单定义规则”,变量只能定义一次。为满足这样的要求,C++提供了两种变量声明:定义声明(简称定义)和引用声明(简称声明)。只有在定义声明才会为变量分配空间。其中,引用声明使用关键字extern(无extern则是定义声明),并且不能初始化变量。
// file1.cppint number = 100; // 定义声明double up = 30.4;
// file2.cppextern int number; //引用声明extern double up = 1.0; // 定义声明,因为有初始化
局部变量和全局变量
全局变量能够提供很大的便利,但是也有极大的风险,数据容易被修改。可以使用const修饰全局变量解决这个问题。
const char* const names[3]={"muye", "dhh", "zyr"};
值得注意的是全局变量和局部变量相遇时,局部优先级高于全局变量。
静态持续性、内部链接性
将static用于作用域为整个文件的变量时,该变量的链接性是内部的。如果链接性为内部的变量去掉static修饰将具有外部链接性。
// file1.cppint errors = 5;
// file2.cppint errors = -1;
以上的定义事实上会出错,程序会创建errors的两个定义(两个文件都试图创建一个外部变量errors),这违反单定义规则。但是将file2修改如下,将不会报错:
// file2.cppstatic int error2 = -1;
由于file2中的errors被static修饰,我们从文件的角度来看:file2中的errors只能被file2所访问,是内部的;但是file1中的errors能被所有文件访问,是外部的(“外部可见,内部不可见”)。
为了区分程序会创建两个errors,但是两个errors的存在很大的不同,就相当于在代码块内部和外都存在同名变量一样,不违背单定义原则。并且与局部优先级高的特点对应,在file2中,本地的内部静态errors会屏蔽外部变量errors。
注:C++中函数原型和函数定义可以分开,但是编译时需要将原型代码和定义代码链接。(编译和链接有待继续了解)
静态存储性、无链接性
静态局部变量是在代码块中被static修饰的变量,其只在程序启动时进行一次初始化,并且其生命周期与程序一样长,可以长期存在。如果其在函数中,那么两次调用该函数之间,其值不会改变。
说明符和限定符
存储说明符:
volatile关键字表明,即使程序代码没有对内存单元进行修改,其值也可能发生变化。volatile 关键字是一种类型修饰符,用它声明的类型变量表示可以被某些编译器未知的因素更改,比如:操作系统、硬件或者其它线程等。遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问。
关于优化:假设编译器发现,程序在几条语句中两次使用到了某个变量的值,则编译器可能不是让程序查找这个值两次,而是将这个值缓存到寄存器中,这种优化假设变量的值在这两次使用之间不会变化(从而硬件等无法改变该变量?)。
2、mutable
可以用它来指出,即是结构(或类)变量为const,其某个成员仍可以被修改。例如:
struct data{char name[20];mutable int accesses;// ...};const data veep = {"zju", 10, ...};// strcpy(veep.name, "hello"); // Invalidveep.accesses += 1; // Valid
3、再谈const
值得注意的是,const不仅包含常量之意,还对链接性有影响!默认情况下全局变量的链接性是外部的,但是用const修饰之后链接性将变为内部的,换言之,const修饰和static修饰效果一样了。
那么为何要如此设计呢?因为通常来说,常量都是放在头文件中,而头文件又可以被多个文件包含。这样导致的问题是,同一个常量将在多个文件中被定义,从而导致重复定义!但是,const变量被限定为内部链接性时,将不会产生这样的错误。每个包括头文件的文件都会创建一个const常量,虽然他们之间不共享,但是由于是常量将没有任何影响。
当然,也可取消常量的这种限制。方法:在其前面用extern修饰。这样其它文件通过关键字extern就可以访问到该常量。(当然只能有一个文件可对其初始化)
const int number = 100; // 内部链接性extern const int ex_number = 1000; //外部链接性,其它文件同样extern关键词进行访问
函数和链接性
C++不允许在一个函数中定义另一个函数,因此所有函数都是静态的,即在整个程序执行期间都一直存在。默认情况下,函数链接性都是外部的,可以在文件间共享。事实上可以函数原型中,使用extern来指出其是在另一个文件中定义的,不过这是可选的(要让程序在另一个文件中查找函数,该文件必须作为程序的组成部分被编译,或者是由链接程序搜索的库文件)。当然也可以使用static将函数的链接性设置为内部,但必须在原型和函数定义中同时使用该关键字。
#include<iostream>using namespace std;extern void print(char* cp); // print在其它文件被定义int main(){print("WTF?????");}
static int private(double);static int private(double x){// ...}
C++函数搜索
如果函数原型指出其为静态(static修饰的静态)的,则编译器只在该文件中查询函数定义;否则编译器将在所有程序文件中查找。如果找到多个定义,将报错。如果程序文件中没有找到,编译将转向库中进行搜索。(程序员自定义函数优先于库文件)
语言链接性
C++中,允许重载,使得同一个函数名可以有多重定义,但是每个定义之间为了区分编译器需要执行名称矫正或名称修饰,为重载函数生成不同的符号名称。这种方法称为被称为C++语言链接。
存储方案和动态分配
编译器使用三块独立的内存:一块用于静态变量,一块用于自动变量,另一块用于自动存储。自动存储的有new和delete管理,通常都是借助指针实现。而指针的链接性特性和一般的变量一样,根据关键词的修饰和指针的位置不同而不同。
new运算符
new失败时
new:运算符、函数和替换函数
运算符new和new[]分别调用如下函数:
void * operator new(std::size_t);void * operator new[](std::size_t);
这些函数被称为分配函数,他们位于全局名称空间。同样,也有由delete和delete[]调用的释放函数:
void * operator delete(void *);void * operator delete[](void *);
当然,对于这些函数,如果您有足够的知识可以自行编写其替代函数,这样每次使用new运算符是将会调用您定义的new()函数。
定位new运算符
通常new负责堆中找到一个足以满足要求的内存块。new还有另一个变体,被称为定位new运算符,它让您能够指定要使用的位置。可以使用这种特性来设置其内存管理规程、处理需要通过特定地址进行访问的硬件或在特定位置创建对象。
要使用new的定位特性,需要包含头文件new,他提供了这种版本的new运算符的原型;然后将new运算符由于提供了所需地址的参数。除需要指定参数外,句法和常规new运算符相同。使用new运算符时,变量后面可以有方括号,也可以没有。
#include<new>struct chaff{char dross[20];int slag;}char buffer1[50];char buffer2[500];int main(){chaff *p1, *p2;int *p3, *p4;// 分配空间p1 = new chaff;p3 = new int[20];// 进行定位p2 = new(buffer1) chaff; // p2指向的空间被定位到buffer1p4 = new(buffer2) int[20]; // p4指向的空间被定位到buffer2}
以下同样是一些相关例子:
#include<iostream>#include<new>const int BUF = 512;const int N = 5;char buffer[BUF];int main(){using namespace std;double *pd1, *pd2;int i;cout << "Calling new and placement new:\n";pd1 = new double[N];pd2 = new (buffer) double[N]; // 从buffer分配空间for(i=0;i<N;i++){pd2[i]=pd1[i]=1000+20*i;}cout << "Memory contents:\n";for(i=0;i<N;i++){cout << pd1[i] << " at " << &pd1[i] << ";";cout << pd2[i] << " at " << &pd2[i] << endl;}cout << "\nCalling new and placement new a second time:\n";double *pd3, *pd4;pd3 = new double[N];pd4 = new (buffer) double[N]; // 从buffer分配空间,会产生覆盖for(i=0;i<N;i++){pd4[i]=pd3[i]=1000+40*i;}cout << "Memory contents:\n";for(i=0;i<N;i++){cout << pd3[i] << " at " << &pd3[i] << ";";cout << pd4[i] << " at " << &pd4[i] << endl;}cout << "\nCalling new and placement new a third time:\n";delete [] pd1;pd1 = new double[N];pd2 = new (buffer + N * sizeof(double)) double[N]; // 提供的地址为buffer首地址,偏移5个double单位for(i=0;i<N;i++){pd2[i]=pd1[i]=1000+60*i;}cout << "Memory contents:\n";for(i=0;i<N;i++){cout << pd1[i] << " at " << &pd1[i] << ";";cout << pd2[i] << " at " << &pd2[i] << endl;}delete [] pd1;delete [] pd3;return 0;}
结果输出如下:
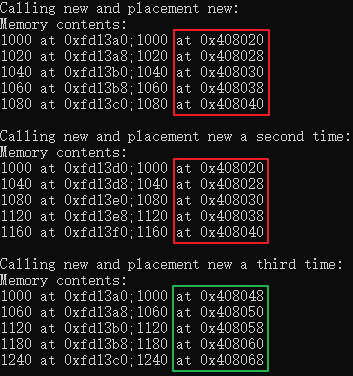
可以看到:
- 一个double占8个单位;
- N * sizeof(double)正好对应40个单位(0x408020 + 40 = 0x408048);
- 也就是说:new(x) var中的x即是一个地址;
- 对同一个内存块多次用new会发生覆盖,new作为定位运算符时,并不会跟踪哪些内存已被使用;
- 值得注意的是定位符分配的空间在此例中并不在堆中,因为buffer是静态数组,delete只能由于这样的指针:指向常规new运算符分配的堆内存。也就是说数组buffer在delete的管辖之外。但是如果buffer是通过常规new创建的,则可以使用delete运算符来释放整个内存块;
除此之外:
- 定位new函数不能替换,只能重载;
其工作原理:基本上,它只是返回传递给他的地址,将其转换为void,以便可以赋给任何指针类型;(void 可以赋给任意指针类型)
名称空间
名称空间能够解决名称冲突的问题,在不同名称空间的相同名称不会发生冲突。
之前我们讨论了变量或者函数的作用域,链接性等。其中比较重要的一点是:“单定义原则”,不允许函数或者变量被重复定义,诸如extern关键字在一定程度上也是为了解决重复定义的问题。此处的名称空间,更是如此。名称空间定义
namespace Jack{double pail;void fetch();int pal;struct Hill {// ...};}namespace Jill{double pail;void fetch();int pal;struct Hill {// ...};}
关键字namespace可以用来创建名称空间,名称空间特点如下:
其允许程序的其它部分使用该名称空间中声明的东西;
- 名称空间可以是全局的,也可以位于名称空间中,但不能位于代码块中。因此默认情况下,在名称空间中声明的名称链接性为外部的(除非他引用了常量—没懂?);
- 名称空间是开放的,可以把名称加入已有的名称空间中;
- 同样,对于原理名称空间中定义的原型,可以在后面进行追加定义; ```cpp namespace Jill{ char goose(const char ); }
namespace Jill{ void fetch(){ // … } }
- 访问名称空间中的名称最简单的方法:作用域解析运算符::(之后类成员方法定义也会遇到!)- 未被修饰的名称如pail称为为限定名称;包含名称空间的名称称为限定的名称;```cppJack::pail = 12.34;
- 除了用户定义的名称空间,还存在另一个名称空间:全局名称空间。他对应于文件级别声明区域,可以把所有的东西看作是其名称空间中的(诸如之前的没有限定名称空间的一些全局变量)
using声明和using编译指令
这其实就是为了方便对名称空间中的名称进行访问设置。您可以对名称空间中的某些名称使用using指令,也可以对整个名称空间使用using指令。
using指令将名称空间中的名称添加到当前的当前的声明区域,例如下面的代码将Jack中的pail添加到main函数定义的声明区域,那么之后就可以在main函数里面使用pail了,而无需利用Jack::pail进行访问。当然,既然pail已经添加到当前的声明区域,如果再定义与之相同的变量将会重复定义!
以下一个例子让我们再认识一下全局名称空间中名称的访问:(事实上,之前讨论了很多全局名称空间中变量访问,诸如extern访问链接性为外部的变量也是访问全局名称空间中名称的例子。注意下面代码访问的方式)int main(){using Jack::pail;// ...}
注:访问方法是:char pail;int main(){using Jack::pail;cin >> pail; // 使用的是Jack::pailcin >> ::pail; // 使用的是全局的pail(main函数外面的)}
::var!
当然也可以将命名空间中的所有名称添加到当前的声明空间:
使用using namespace Jack;
using namespace Jack;之后Jack命名空间中的所有名称就可以访问了(无需Jack::var,直接var)!当然使用using声明就相当于在指定区域进行变量等的声明定义(如果使用得不好,将会造成名称冲突!)。
值得注意的是:使用using声明时,就好像声明了相应的名称一样,如果某个名称已经在函数中声明了,则不能用using声明导入相同的名称。然而using编译指令在使用时,将进行名称解析,就像在包含using声明和名称空间本身的最小声明区域中声明了名称一样。由于名称空间通常是全局的,当使用using编译指令导入一个已经在函数中声明的名称,则局部名称将隐藏名称空间的名称(就像局部变量隐藏全局变量一样,但是由于using编译指令在函数里面,函数外面的空间无法访问using编译指令解析的空间)。(using声明和using编译指令的差异!)
假设Jack和Jill两个名称空间都有常量PI,那么如果采用Jack::PI,以及Jill::PI进行访问的确不会出错。但是如果同时用了using Jack::PI和using Jill::PI,将会报错!(同理using namespace Jack和using namespace Jill同时使用)。如何理解#include指令
事实上#include<iostream>指令使得头文件iostream被放到名称空间std,如果在之后再使用using namespace std将可以访问iostream里面的名称等。
上面的代码等价于:#include<iostream>using namespace std;int main(){;}
系统不支持名称空间时,就可以采用第二种方式。#include<iostream.h>int main(){;}
名称空间其它特性
名称空间可以实现嵌套
如果要访问flame:namespace elements{namespace fire{int flame;}float water;}
elements::fire::flame,当然也可以使内部名称可用:using namespace elements::fire。名称空间内部可以使用using
```cpp namespace myth{ using Jill::fetch; using namespace elements; using std::cout; }
myth::cout << myth::fetch << std::endl;
由于fetch,cout等现在在myth名称空间中,所以可以用`myth::cout`,`myth::fetch`进行访问!<a name="hXFIz"></a>### 名称空间别名```cppnamespace hello {//...}namespace world = hello;namespace MEF = myth::elements::fire;
未命名名称空间
namespace{int ice;int age;}
未命名名称空间有一个潜在作用域:从声明点到该声明区域的末尾(从这个方面来看,他们和全局变量类似)。不能在未命名名称空间所属文件之外的其它文件中,使用该名称空间名称。它提供了链接性为内部的静态变量的替代品。上面的代码效果和下面代码相同(都是在全局位置定义):
static int ice;static int age;
名称空间及其前途
关于名称空间编程的指导:
- 使用在已命名的名称空间中声明的变量,而不是使用外部全局变量;
- 使用在已命名的名称空间中声明的变量,而不是使用静态全局变量;
- 如果开发了一个函数库或类库,将其放在一个名称空间中;
- 仅将编译指令using作为一种旧代码转换为使用名称空间的权宜之计;
- 不要在头文件使用using编译指令。如果非要使用编译指令using(但是,using声明还是可以的),应将其放在所有预编译指令#include之后;
- 导入名称时,首选使用作用解析运算符或using声明的方法(不是using编译指令);
- 对于using声明,首选将其作用域设置为局部而不是全局。

若有收获,就点个赞吧
0 人点赞
