原论文链接: Temporal Segment Networks: Towards Good Practices for Deep Action Recognition-2016 其它参考: [行为识别论文详解]TSN(Temporal Segment Networks) 代码链接
单词汇总

介绍
TSN基于two-stream方法构建。
论文主要贡献:
- 提出了TSN(Temporal Segment Networks),基于长范围时间结构(long-range temporal structure)建模,结合了稀疏时间采样策略(sparse temporal sampling strategy)和视频级监督(video-level supervision)来保证使用整段视频时学习得有效和高效;
- 在TSN的帮助下,研究了一系列关于视频数据学习卷积网络的实践问题;
在本文之前主流的方法都是着重于提取图像空间信息以及短期的运动信息,不能很好地处理长期时间依赖问题(long-range temporal structure),所以本文需要解决这个问题。然后考虑到密集采样会造成很多的冗余计算,本文采用了稀疏时间采样策略。
和two-stream一样,TSN也是由空间流卷积网络和时间流卷积网络构成。但不同于two-stream采用单帧或者单堆帧,TSN使用从整个视频中稀疏地采样一系列短片段,每个片段都将给出其本身对于行为类别的初步预测,从这些片段的“共识”来得到视频级的预测结果。在学习过程中,通过迭代更新模型参数来优化视频级预测的损失值(loss value)。
TSN正是利用这种整个视频采样的方式来获取长时间的依赖信息的。
对于数据不足的问题,本文采用了以下方式:(1)交叉模式预训练;(2)正则化;(3)数据增强。
为了充分利用视频中的视觉信息,本文学习的四种输入形式:单独的RGB图、堆叠的RGB差分、堆叠光流场、堆叠变形光流场。
相关工作
任务表示
假设 表示一个视频,本文将其平均分为
表示一个视频,本文将其平均分为 段
段 ,在这之后TSN将对一系列片段进行建模:
,在这之后TSN将对一系列片段进行建模:
其中 是一系列片段。每一个片段
是一系列片段。每一个片段 从对应的
从对应的 中随机采样。
中随机采样。 表示带有参数
表示带有参数 的卷积网络,其输入为。
的卷积网络,其输入为。 函数表示的是片段共识函数,它从不同片段的结果得到对于分类的共识。基于这个公式预测函数
函数表示的是片段共识函数,它从不同片段的结果得到对于分类的共识。基于这个公式预测函数 预测整段视频属于哪个类别的概率,本文选取Softmax函数作为。损失函数选取交叉熵,最终的损失函数将片段共识
预测整段视频属于哪个类别的概率,本文选取Softmax函数作为。损失函数选取交叉熵,最终的损失函数将片段共识 认为是:
认为是:
其中 是类别的个数,
是类别的个数, 是类别
是类别 的groundtruth标签。实验中片段的数量 设置为3。本工作中共识函数 采用最简单的形式,即
的groundtruth标签。实验中片段的数量 设置为3。本工作中共识函数 采用最简单的形式,即  ,采用用聚合函数
,采用用聚合函数  (aggregation function)从所有片段中相同类别的得分中推断出某个类别分数
(aggregation function)从所有片段中相同类别的得分中推断出某个类别分数  。聚合函数 采用均匀平均法来表示最终识别精度。(本文的 还尝试了最大值,加权平均;但是最终选取的函数平均操作。)
。聚合函数 采用均匀平均法来表示最终识别精度。(本文的 还尝试了最大值,加权平均;但是最终选取的函数平均操作。)
TSN是可微的,或者至少有次梯度(这是由 函数的选择决定)。这使我们可以用标准反向传播算法,利用多个片段来联合优化模型参数 。在反向传播过程中,模型参数 关于损失值  的梯度为:
的梯度为:
矩阵运算是没有链式法则的,这里只是一种表示方法!
网络结构

注意看这个图:空间网络还是以单帧为输入,所以多帧仍旧按照双流法论文中的平均值作为输出;然后对于空间和时间网络,对于不同段的输入,它们是在分别经过共识函数之后才进行融合!(值得仔细思考的是,它的反向传播是如何实现的。其实相对于基础模块,也就是多了一个共识函数,我们只需要编写其求导即可。如果共识函数是平均等操作,直接利用基本模块也可以实现。) 事实上,代码中,不同段的图片是一起被输入网络的:那就是五个维度啦!最麻烦的还是要搞懂数据的操作情况!
本文卷积网络基于BN-Inception模块,作者将原始的BN-Inception架构适应于two-stream架构。和原始two-stream卷积网络相同,空间流卷积网络操作单一RGB图像,时间流卷积网络将堆叠的连续的光流场作为输入。
网络输入
对于网络输入,除了像双流法论文中的空间网络操作单一RGB图像,时间网络操作堆叠光流场。本文还引入了二外的输入形式:RGB差分(RGB difference)和扭曲的光流场(warped optical flow fields)。
两个连续帧的RGB差分表示动作的改变,对应于运动显著区域。故试验将堆叠的RGB差分作为另一个输入模式。
普通的光流场容易引入背景运动(摄像机的运动导致),扭曲光流场抑制了背景运动,使得专注于视频中的人物运动。
网络训练
交叉输入模式预训练:
空间网络以RGB图像作为输入:故采用在ImageNet上预训练的模型做初始化。对于其他输入模式(比如:RGB差分和光流场),它们捕捉视频数据的不同方面,并且它们的分布不同于RGB图像的分布。作者提出了交叉模式预训练技术:利用RGB模型初始化时间网络。
- 首先,通过线性变换将光流场离散到从0到255的区间,这使得光流场的范围和RGB图像相同。
- 然后,修改RGB模型第一个卷积层的权重来处理光流场的输入。具体来说,就是对RGB通道上的权重进行平均,并根据时间网络输入的通道数量复制这个平均值。这一策略对时间网络中降低过拟合非常有效。
正则化技术
在学习过程中,Batch Normalization将估计每个batch内的激活均值和方差,并使用它们将这些激活值转换为标准高斯分布。这一操作虽可以加快训练的收敛速度,但由于要从有限数量的训练样本中对激活分布的偏移量进行估计,也会导致过拟合问题。因此,在用预训练模型初始化后,冻结所有Batch Normalization层的均值和方差参数,但第一个标准化层除外。由于光流的分布和RGB图像的分布不同,第一个卷积层的激活值将有不同的分布,于是,我们需要重新估计的均值和方差,称这种策略为部分BN。与此同时,在BN-Inception的全局pooling层后添加一个额外的dropout层,来进一步降低过拟合的影响。dropout比例设置:空间流卷积网络设置为0.8,时间流卷积网络设置为0.7。数据增强
数据增强能产生不同的训练样本并且可以防止严重的过拟合。在传统的two-stream中,采用随机裁剪和水平翻转方法增加训练样本。作者采用两个新方法:角裁剪(corner cropping)和尺度抖动(scale-jittering)。
角裁剪(corner cropping):仅从图片的边角或中心提取区域,来避免默认关注图片的中心。
尺度抖动(scale jittering):将输入图像或者光流场的大小固定为 ,裁剪区域的宽和高随机从
,裁剪区域的宽和高随机从  中选择。最终,这些裁剪区域将会被resize到
中选择。最终,这些裁剪区域将会被resize到 用于网络训练。事实上,这种方法不光包括了尺度抖动,还包括了宽高比抖动。
用于网络训练。事实上,这种方法不光包括了尺度抖动,还包括了宽高比抖动。
结果展示
不同的训练策略: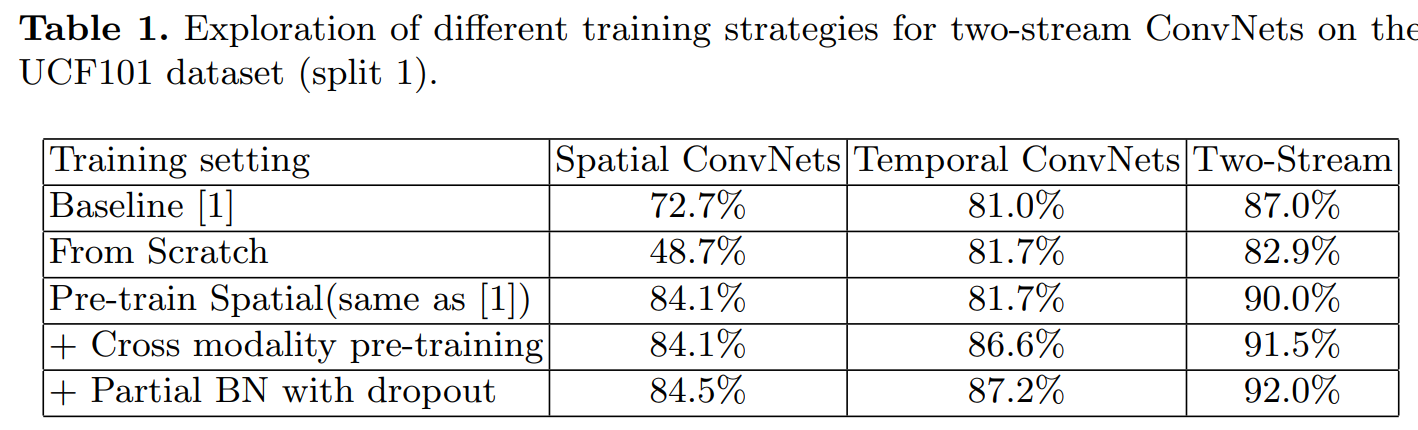
预训练模型是能够提升模型的泛化能力的!(就是在相似的其它数据集上面进行训练之后,再在自己的数据集上面进行训练)
不同模式输入表现: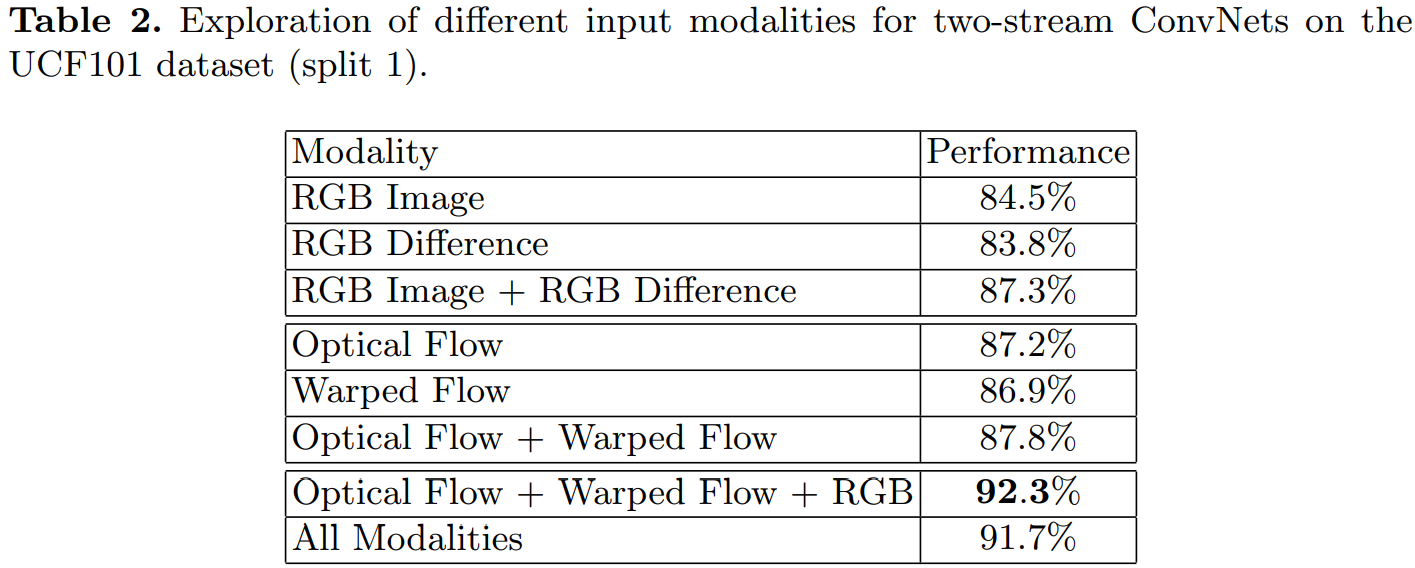
不同的共识函数: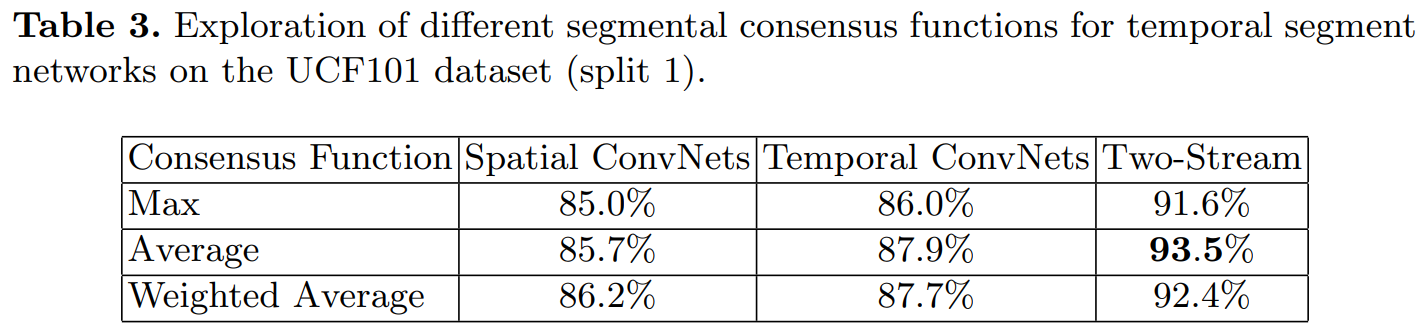
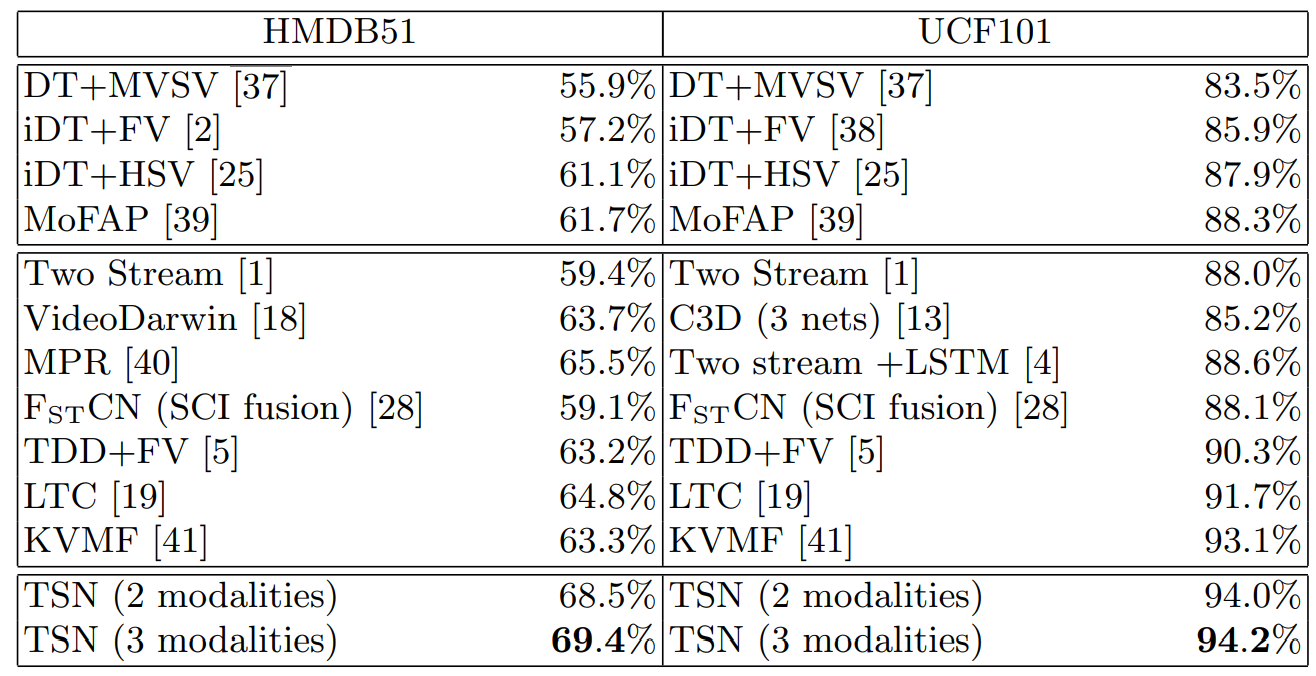
模型拆解分析:
看起来效果非常棒的,但是值得注意的是,传统方法的基准分数也很高

若有收获,就点个赞吧
0 人点赞
