Disentangling and Unifying Graph Convolutions for Skeleton-Based Action Recognition open source code: https://hub.fastgit.org/kenziyuliu/ms-g3d
Abstract
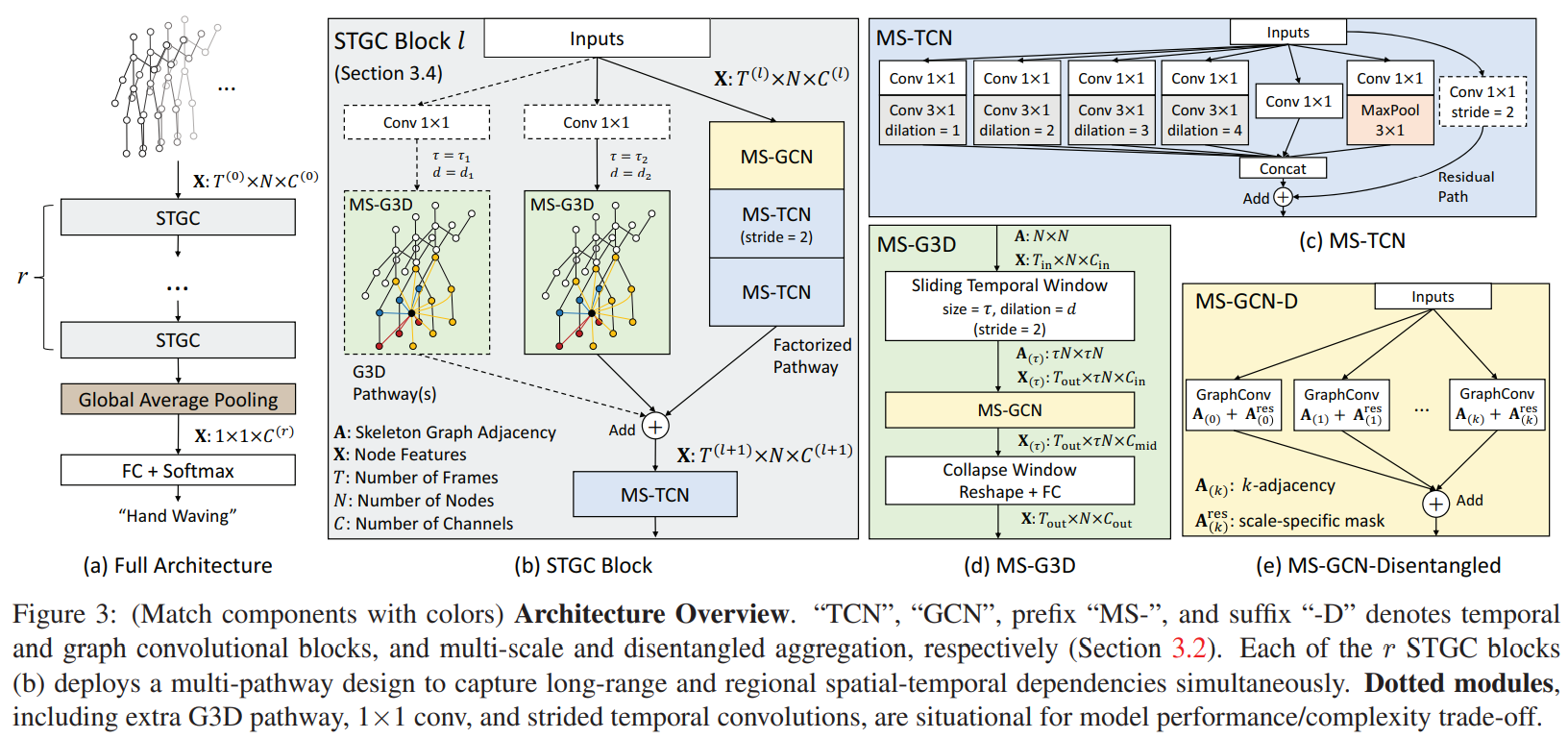
Existing methods have limitations in achieving (1) unbiased long-range joint relationship modeling under multiscale operators and (2) unobstructed cross-spacetime information flow for capturing complex spatial temporal dependencies. In this work, we present (1) a simple method to disentangle multi-scale graph convolutions and (2) a unified spatial-temporal graph convolutional operator named G3D. The proposed multi-scale aggregation scheme disentangles the importance of nodes in different neighborhoods for effective long-range modeling. The proposed G3D module leverages dense cross-spacetime edges as skip connections for direct information propagation across the spatial-temporal graph. By coupling these proposals, we develop a powerful feature extractor named MS-G3D based on which our model1 outperforms previous state-of-the-art methods on three large-scale datasets: NTU RGB+D 60, NTU RGB+D 120, and Kinetics Skeleton 400.
Method

若有收获,就点个赞吧
0 人点赞
