date:2020/05/24version:1.0原文:"Regional Multi-person Pose Estimation"
词汇表
A. state-of-art:最先进的
B. novel:新的
C. corresponding:相应的
D. pictorial:形象的
E. leverage:利用
F. metric:度量
G. convergence:收敛
问题:论文中指出人体人体检测定位的微小差异就会导致单人人体姿态估计(SPPE)的失败。这是为何?
可能答案:人体检测失败意味着在box里面不包含整个人体。但是利用IOU > 0.5等标准来评判,此时已经进行了正确的人体检测,但是由于此时不包含整个人体,所以SPPE不对。
AlphaPose框架要点
- Symmetric Spatial Transformer Network(SSTN);
- SSTN由STN和SDTN组成;
- 其中STN接收human proposals(位于SPPE前面),SDTN产生pose proposals(位于SPPE后面);
- 解决人体姿态估计不准确的情况;
- Parametric Pose Non-Maximum-Suppression(NMS):解决对同一个对象产生多检测框的问题;
- Pose-Guided Proposals Generator(PGPG):PGPG用于数据增强;
目前多人人体姿态估计框架:two-step框架、part-base框架;
two-step框架:
a.检测人体框;b.人体框里面的人体姿态估计;
缺点:精度取决于人体检测框的精度
part-based框架:
a.检测关键点;b.进行组合
缺点:对于两个比较近的人,关键点分配模棱两可;不能从全局上认识关键点;
AlphaPose采用的是two-step框架:人体检测利用VGG-based SSD-512,关键点识别利用SPPE Stacked Hourglass,STN用的ResNet-18
Regional Multi-person Pose Estimation
Symmetric STN and Parallel SPPE
SPPE都是单人图像进行训练的,所以在图像检测框中必须包括整个人体,否则SPPE将不能进行;
STN
STN本质上是进行一个坐标变换:
 ,
, 和
和 是变化前的坐标。
是变化前的坐标。
STN的目的是为了辅助目标检测算法进行学习,将其学得更准确。
STN就是将检测到的人体移到人体区域的中央。
SDTN
SDTN本质上是STN中的一个反变换;求反的过程不是普通方阵的求逆。
Parallel SPPE
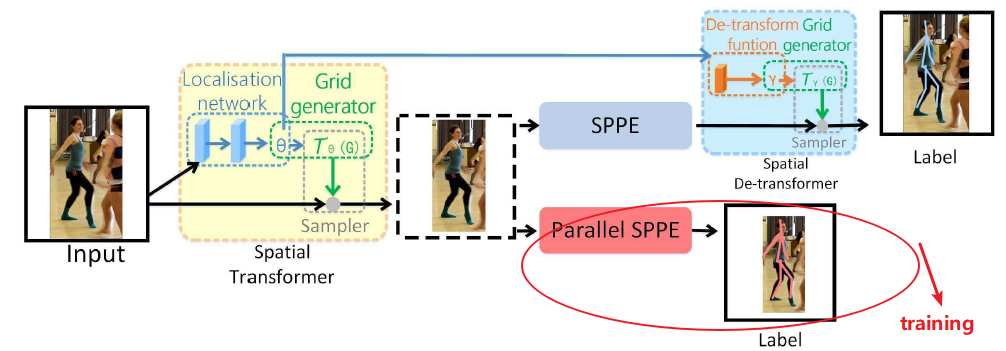
貌似加这个就是为了误差好算,而且由于参数固定,每次无需对他们进行求导,导数固定。
到目前为止,貌似和我之前的理解有些偏差:STN貌似只是做了一个将检测的人体居中的变化。还有就是SPPE对训练数据集进行了剪切缩放等操作,按理来说不会产生论文中所说的检测框出现误差导致SPPE失败的情况,因为检测框中是有人的。哪里理解错了?
(空白太多并且人偏离中心太远也可能会导致SPPE的失败?当然对于人体没有框全的确会产生失败—由于是热点图,所有人体不全的话,如果不加阈值的话应该还是能够检测出人的所有关键点,但是检测的是错的,加了阈值之后就完全不行了。)(还是说,居中的话能够提升正确被估计的可能性?)
值得注意的是,在文章后面有提到,对于human proposals会进行长宽30%的延伸  解决第一种检测框问题。
解决第一种检测框问题。
Parametric Pose NMS
解决冗余检测框的问题 抑制非最大值。
在实际过程中,有多次删选的过程:1、产生的人体目标框会进行NMS;2、产生的关键点会进行NMS;3、除了NMS的其它删选方法。
Elimination Criterion
定义一种相似度度量准则,并且确定了阈值对两者是否属于同一个人进行判断。
Poseguided Proposals Generator
目的:实现数据增强
神奇的数据增强方式。总的思想是学到一个偏差分布,增强数据是引入偏差,从而使得模型能够适应不完美的bound boxes(???)
代码
代码主要有两个部分组成:人体目标检测,姿态估计;
每个部分都有对应的NMS,比如目标检测,利用NMS去除冗余框,姿态估计利用NMS合并关键点。
人体目标检测
利用的yolo-spp,返回人体目标的位置,进行切割之后送入姿态估计网络;
姿态估计
姿态估计采用的ResNet101,提取其第四层的featuremap,进行多次上采样之后产生关键点热力图(相对于原图缩小了4倍),由关键点热力图获取关键点的坐标。
注:文本中的上采样采用PixelShuffle方法实现。
NMS的思想
选取confidence最大的结果保留,其它结果与之对比,如果其它结果的IOU与之足够大,则有充分理由认为他们来自同一个对象,从而对其它结果进行抑制删除。也就是说同一个对象可能被多次预测,那么多次预测的结果,我们选取概率最高的进行保留(有时也可以对同一对象的多次预测进行综合)。
坐标变换STN
代码中不再包括,大概是没有什么效果吧。
总的来看,AlphaPose也没有什么新的东西罗,也就是一个框架。

若有收获,就点个赞吧
0 人点赞
