单词
intros: 介绍contemplate: 考虑prior: 之前invert: 使颠倒sematic: 语义的
网络特点
有效尝试
值得注意的是,目标检测的网络通过适当修改可以完成分类任务,反之亦然。
the deal
检测框预测
- 检测框预测和yolo9000类似;
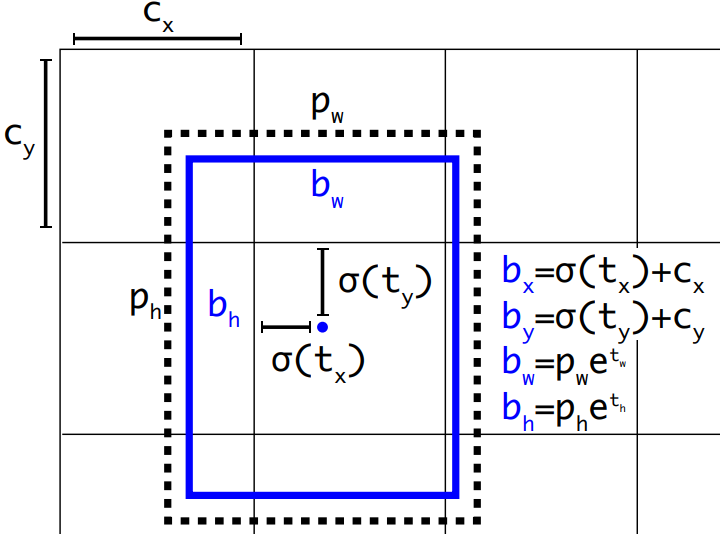
预测socre式采用logistic regression而不是softmax;
采用多标签分类;
yolov3预测时,从三个不同的尺度进行;
- 采用类似feature pyramid networks的结果实现跨尺度预测;
- 最终预测每个尺度上输出3维张量(和yolo类似);
- 每个尺度上预测三个boxes,每个box有包括检测框的4个属性,一个socre以及类别信息(80类);
- 最终每个尺度上的输出:

其它尺度预测实现;
特征提取过程中,不断采用
 卷积,类似resnet;
卷积,类似resnet;-
训练
多尺度训练;
- 大量的数据增强;
-
无效尝试
采用线性激活函数预测坐标偏移作为box的宽高倍数;(?)
- 线性预测x,y偏差取代逻辑激活预测;
- Focal loss;
- 双IOU阈值和真值分配;

若有收获,就点个赞吧
0 人点赞
