原文:
You Only Look Once:Unified, Real-Time Object Detection
目标检测基础知识
IOU交并比:
预测box和真实box的交集比上并集;
AP(平均正确率):
P-R(precision-recall)曲线的面积;计算结果小于1,通常利用百分数表示;
锚点
目标检测中的锚点
Anchor就是利用采用固定大小的检测框;
但是在yolo-v1中没有采用anchor
有趣单词
repurpose:重新
spatial:空间
state of the art:最前沿的
conscious:意识的
reasons:推理
过去物体检测的方法
通俗来说:不同位置利用不同大小的box去检测,并对box内进行分类(比如滑动窗口)<br /> RCNN:先进行可能的box估计,然后进行后续处理;<br />(对于部分复杂模型可能还需要分模块进行训练)
YOLO特点
- 将检测问题转为检测框的回归问题;
- 检测和分类整合到单个网络;
- 相比于前言的技术,位置检测误差稍微大一点,但是泛化能力强;
- YOLO能够全局把握一张图片;
- 结构简单,只包括单个卷积网络;
- YOLO输出:
 以及socore;
以及socore; - 结构设计时采用了
 卷积进行channel的变换;
卷积进行channel的变换;
结构设计
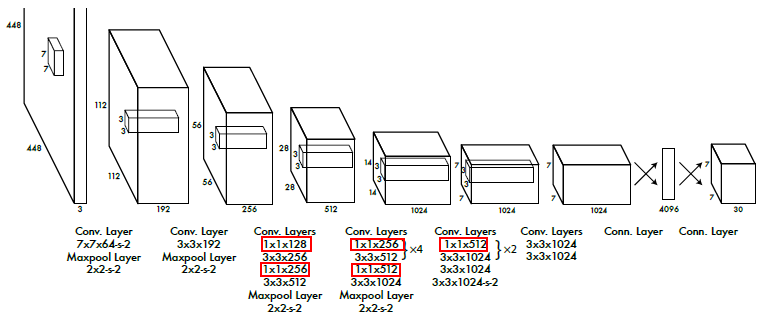
采用了 卷积进行channel的变换;
卷积进行channel的变换;
相关细节
- 将图片分为S*S的方格;
- 图片输入为
 ;
;- 这意味着,图像需要进行对应的操作
 检测框也需要对应做一定的修改;(padding操作)
检测框也需要对应做一定的修改;(padding操作) - 比如,将非正方形的图像转为正方形;(此操作可以反映归一化的作用)
- 这意味着,图像需要进行对应的操作
- 每个方格预测B个box以及其score = Pr(object)*IOU(socre)综合反映IOU以及box内有无物体;
- 包含真实对象中心的单元格负责对该对象进行预测;
- 一个问题训练时Pr和IOU如何给出?(end to end看来并不需要对IOU进行计算)
- 训练集的socre在对应处被设置为1,也就是说理想情况两者完全重合(IOU=1);(换句话说score既不是Pr,也不是IOU,同时和后面的类别概率能够产生关联 — 这就是为什么如此定义的原因;但是如此定义的理由何在?网络学到的真的是这个概率吗?)
- 当然测试的时候不会如此理想,可以选择最大socre格子作为检测框中心格子;
 (这只是理想效果)
(这只是理想效果)
- 每个方格预测B个box没有明白?是否表示一个格子最多可以预测两类物体?(貌似不是如此,两个box预测的同一个对象)
- 每个方格能够产生B个box(和全连接的输出对应),但是在这B个box中,选取IOU最高的作为实际预测的box;
- 对于如此多的检测框,最后会通过特定方式去掉:NMS,类别概率(socre和类概率的乘积)
- NMS就是先获得confidence最大的,然后其它的boxes与之计算iou,当iou大于阈值则认为他们检测的是同一个对象,否则认为是不同对象。
- 每个box将会产生5个输出:x,y,w,h and confidence;
- 其中只要confidence大于阈值,则可以认为该格产生的检测框有效,则保留;
- 对于不同格产生的检测框(可能是属于同一个对象)进行NMS;
- x,y,w,h不是绝对坐标和长宽;
- (x,y)表示框的中心相对于单元格边界(左上角)的位置(0-1)
- 当然前提是此处包含对象的中心,如果不包含对象的中心,则该cell被期望不需要进行预测;训练时label在该cell值理想值全为0;换句话说产生训练的labels时是只有有对象中心的cell才会被对应赋值,否则为0;
- 所以,先确定中心在那个grid cell;
- 然后再计算出其相对于此grid cell的偏移(相对量0-1)
- (w,h)是框相对于padding之后图长宽大小(0-1)
- 每个格子还会预测其所属类别的概率;Pr(classi|object);
- 训练集的labels只在有对象中心格子的对应类别上赋值为概率1(理想值);
- 也就是说自己如果要实现yolov1标签生成,至少需要如下几步:
- 图片进行padding操作变为正方形(对应的box也要进行修改)
- 产生的是SS(B5 + C)的三维数组;
- 如果某个格子包括某个对象的中心,则在该格子(格子坐标和输出的三维数组对应)赋值对应的(x,y,w,h)(B个预测框对应的值赋值相同,一个格子产生多个框为了后续跟据IOU进行选择;),然后confidence将会被赋值为1,其所属类别同样被赋值为1,其它将会默认为0;(对于v1来说每个格子只能预测一个对象)
- (x,y)是中心位置相对于该格子的位置偏差,需要归一化处理;
- (w,h)同样相对于原始图像的长宽进行归一化;
- 同一个格子的类别概率预测和B box无关,B box共享概率;
- 所以最终输出:SS(B5+C)
- 其中S=7,B=2,C=20
- 以上如何在网络结构中体现?
- 还是从最终的输出;
- 为什么说原图切成SS:最终输出SS个中的每一个格子的感受野对应于原图的S*S中的对应格;
- 最终输出每格为30-d,和坐标长宽以及类别相对应;
- 最终的输出是和训练数据集的表征对应的,也就是说训练时标签的意义决定了其拟合的意义;
- 以上如何在网络结构中体现?
- 图片输入为
- 网络最终输出bouding boxes以及对应的类别概率;
- 对于图像中的bounding boxes的坐标以及长宽进行归一化操作;
- 归一化的原因?
- 先将图像补为正方形,然后对检测框信息进行归一化(保存的是比率信息)之后,后续resize图像后无需修改检测框信息;
- 激活函数采用leaky-relu;
- 原网络采用了fc层将最终的三维数组等价为了一维;
- sum-squared error为目标函数来优化;


一篇对yolo的解读blog:
yolo核心思想理解
从头实现yolo
目标函数
- 由此可以看出,网络简单但是目标函数相对普通目标函数来说更为复杂;
- 目标函数的选取很重要;
- loss原始版本:输出和label两个数组对应元素求其偏差的平方和;
- 缺点:
- 中心坐标的偏差和检测框尺寸偏差完全等价;
- 图片中其实很多位置都没有对象,没有对象出的confidence理想为0,模型在训练时需要将它们push到0,所以其产生的梯度可能会掩盖其它部分产生的梯度值(梯度过大);
- 同样的偏移,在大检测框和小检测框上等价;
- 修正:
- 提高坐标误差占比,降低confidence误差占比;利用两个超参数
 ;
; - 对于每个格子选取具有最高IOU的检测器的检测结果参与loss的计算;(也就是说在该格,具有最高IOU的box负责对象的预测;之前每个格子有B个box,也就是说有B个检测器)
- 当当前格子没有对象的中心坐标时(confidence小于阈值),则考虑confidence的偏差;
- 提高坐标误差占比,降低confidence误差占比;利用两个超参数
- 缺点:
目标函数的公式见上图;
其基本思想:
- 将目标函数分为两部分:当检测到有物体时,当检测框中无物体时;
- 对两种情况,产生loss意义不同;
其中公式中:
 表示第
表示第 个格子中的第
个格子中的第 个box如果有object则为1,否则为0;
个box如果有object则为1,否则为0;

若有收获,就点个赞吧
0 人点赞
