单词
cascade: 级联telepresence:“网真”occlusions: 遮挡anatomical: 解剖amenable: 有义务的skeletal: 骨骼的kinematic: 运动egocentric: 以自我为中心monocular: 单眼的robust: 健壮的Methodology: 方法vertices: 顶点ablation: 消融Metrics: 指标
小小科普
参考: 图卷积神经网络
图卷积神经网络:
简单的来说就是其研究的对象是图数据(Graph),研究的模型是卷积神经网络;
Euclidean data:
Euclidean data最显著的特征就是有规则的空间结构,比如图片是规则的正方形栅格,比如语音是规则的一维序列。而这些数据结构能够用一维、二维的矩阵表示,卷积神经网络处理起来很高效;
Non Euclidean data:
推荐系统、电子交易、计算几何、脑信号、分子结构等抽象出的图谱;
作者的一些思考
难点
手或者目标对象的遮挡问题;
-
如何实现估计
对手和物体进行整体把握,不宜分别估计;
- 手和物体在交互过程中是有相互制约的;
- 对手姿态的估计,同样可以为物体的属性提供线索;
- 物体的姿态同样限制握住它的手的姿态;
- 在估计过程时,将手以及物体表征为一个单独的图;
- 产生3D姿态估计是,结合第一人称和第三人称视频数据(???);
- 首先估计2D关键点和物体边界;
- 然后在二维姿态估计的基础上,分层次联合恢复深度信息(3D);
- 基于检测的模型在检测2D关键点方面效果非常好,但是由于三维检测时的高度非线性以及巨大的输出空间,使得基于回归的模型在三维检测方面更流行;
模型分两步走:
采用ResNet10提取特征,并估计初始的2D关键点;
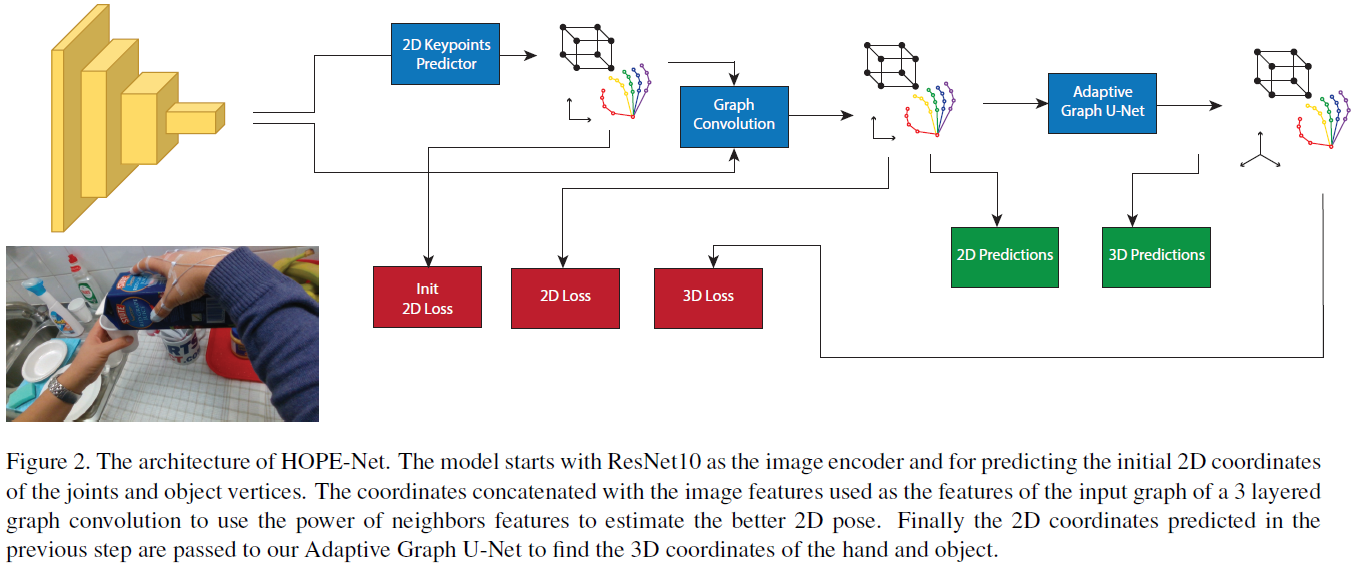
2D关键点提纯
- 将坐标与图像特征连接起来作为3层图卷积的输入图的特征,利用邻域特征的力量来估计更好的二维位姿;
2D转3D
-
图像编码与图卷积
采用轻量级ResNet(ResNet10)作为图像编码器,其为每张图片输出2048D的特征向量,然后采用一个全连接层产生初始的2D关键点数据;(回归出2D关键点)
- 将2048D的Image feature和每个关键点坐标进行连接产生多个2050D的特征,这些特征将被用于产生节点;
- 利用3层结构的自适应图卷积网络,结合临近信息对2D关键点进行修改;
最后将修改后的关键点输入到自适应U-Net中实现维度的转换;
Adaptive Graph U-Net
原版的U-Net尚未了解…
将问题转为图问题的原因:能够利用临近信息;
- 更能够发现手和物体的关系;
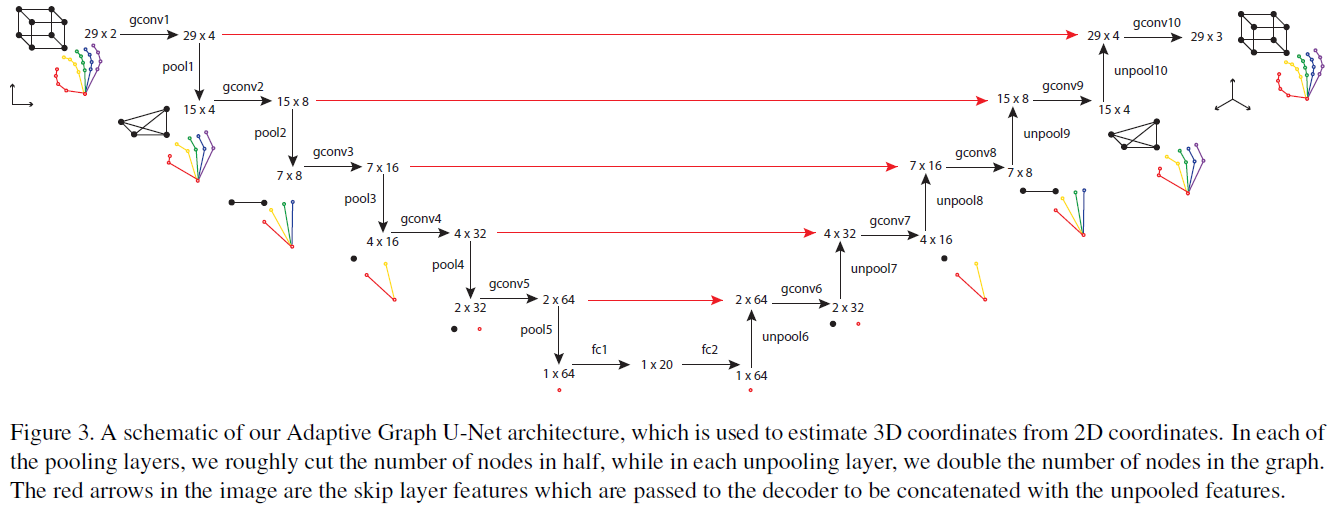
图卷积
之前了解过Graph U-Net,但是其中的gPool和gUnpool在此处不再实用,因为此处的graph为稀疏图,采用该论文中的gPool,基本上会导致节点的孤立。
图卷积操作
此映射的作用是:将临接节点的信息不断汇总到本节点。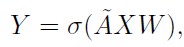
其中: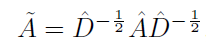 ,
,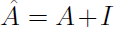 ,
,
此公式和卷积运算的关系可以参考GCN论文!(卷积运算可以最终近似推出此公式)
其中一个任务就是确定临接矩阵,当然可以选择普通的,按照关键点实际连接情况进行临接矩阵的确定。但是,通过实验发现,让网络自行学习临接矩阵更优(此类操作严格来说使得该矩阵不再是临接矩阵)。所以Adaptive graph convolution需要更新
运算实现代码
实现
# A_hat is trainableA_hat = Parameter(torch.eye(29).float().cuda(), requires_grad=True)# ......# A_hat: batch * 29 * 29batch, N = A_hat.shape[:2]# D_hat: batch * 29D_hat = (torch.sum(A_hat, 1) + 1e-5) ** (-0.5)L = D_hat.view(batch, N, 1) * A_hat * D_hat.view(batch, 1, N)# 此处的矩阵运算与数学意义上的不同,但是显然和上式公式是等价的。但是相对于矩阵乘法来说降低了运算量
 卷积运算实现
卷积运算实现
def forward(self, X, A):batch = X.size(0)#A = self.laplacian(A)# A_hat: batch * 29 * 29A_hat = A.unsqueeze(0).repeat(batch, 1, 1)X = self.fc(torch.bmm(self.laplacian_batch(A_hat), X))if self.activation is not None:X = self.activation(X)return X
注:nn.Linear函数好像和之前印象中的存在偏差!(不需要进行“拉直”操作)
(之前理解的Linear不对)
gPool和gUnpool实现
class GraphPool(nn.Module):def __init__(self, in_nodes, out_nodes):super(GraphPool, self).__init__()self.fc = nn.Linear(in_features=in_nodes, out_features=out_nodes)def forward(self, X):# 是对节点数进行pool,所以需要transposeX = X.transpose(1, 2)X = self.fc(X)X = X.transpose(1, 2)return X
Graph U-Net实现
- 就是先不断地利用conv和pool不断降低节点数和feature大小;
- 然后利用conv和unpool不断增加节点数和feature的大小;
显然由于这是矩阵运算,所以对于feature输出size的控制相对于图片卷积来说方便很多;
class GraphUNet(nn.Module):def __init__(self, in_features=2, out_features=3):super(GraphUNet, self).__init__()self.A_0 = Parameter(torch.eye(29).float().to(device), requires_grad=True)self.A_1 = Parameter(torch.eye(15).float().to(device), requires_grad=True)self.A_2 = Parameter(torch.eye(7).float().to(device), requires_grad=True)self.A_3 = Parameter(torch.eye(4).float().to(device), requires_grad=True)self.A_4 = Parameter(torch.eye(2).float().to(device), requires_grad=True)self.A_5 = Parameter(torch.eye(1).float().to(device), requires_grad=True)self.gconv1 = GraphConv(in_features, 4) # 29 = 21 H + 8 Oself.pool1 = GraphPool(29, 15)self.gconv2 = GraphConv(4, 8) # 15 = 11 H + 4 Oself.pool2 = GraphPool(15, 7)self.gconv3 = GraphConv(8, 16) # 7 = 5 H + 2 Oself.pool3 = GraphPool(7, 4)self.gconv4 = GraphConv(16, 32) # 4 = 3 H + 1 Oself.pool4 = GraphPool(4, 2)self.gconv5 = GraphConv(32, 64) # 2 = 1 H + 1 Oself.pool5 = GraphPool(2, 1)self.fc1 = nn.Linear(64, 20)self.fc2 = nn.Linear(20, 64)self.unpool6 = GraphUnpool(1, 2)self.gconv6 = GraphConv(128, 32)self.unpool7 = GraphUnpool(2, 4)self.gconv7 = GraphConv(64, 16)self.unpool8 = GraphUnpool(4, 7)self.gconv8 = GraphConv(32, 8)self.unpool9 = GraphUnpool(7, 15)self.gconv9 = GraphConv(16, 4)self.unpool10 = GraphUnpool(15, 29)self.gconv10 = GraphConv(8, out_features, activation=None)self.ReLU = nn.ReLU()def _get_decoder_input(self, X_e, X_d):return torch.cat((X_e, X_d), 2)def forward(self, X):# X: batch * 29 * 2X_0 = self.gconv1(X, self.A_0)X_1 = self.pool1(X_0)X_1 = self.gconv2(X_1, self.A_1)X_2 = self.pool2(X_1)X_2 = self.gconv3(X_2, self.A_2)X_3 = self.pool3(X_2)X_3 = self.gconv4(X_3, self.A_3)X_4 = self.pool4(X_3)X_4 = self.gconv5(X_4, self.A_4)# X_5: batch * 1 * 64X_5 = self.pool5(X_4)global_features = self.ReLU(self.fc1(X_5))global_features = self.ReLU(self.fc2(global_features))X_6 = self.unpool6(global_features)X_6 = self.gconv6(self._get_decoder_input(X_4, X_6), self.A_4)X_7 = self.unpool7(X_6)X_7 = self.gconv7(self._get_decoder_input(X_3, X_7), self.A_3)X_8 = self.unpool8(X_7)X_8 = self.gconv8(self._get_decoder_input(X_2, X_8), self.A_2)X_9 = self.unpool9(X_8)X_9 = self.gconv9(self._get_decoder_input(X_1, X_9), self.A_1)X_10 = self.unpool10(X_9)X_10 = self.gconv10(self._get_decoder_input(X_0, X_10), self.A_0)return X_10
Graph Pooling
采用全连接层,并将其作用于feature matrix的transpose;
特点:全连接层kernel综合所有特征;
-
Graph Unpooling
同样采用全连接层,于Pooling操作类似,同样作用于feature matrix的transpose产生预期数量的节点数,最好再将其transpose回来。
Loss Function
loss由三部分组成:
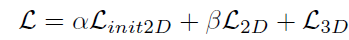
分别是:初始的2D loss,提纯的2D loss以及3D loss。
loss计算时采用Mean Squared Erroroutputs2d_init, outputs2d, outputs3d = model(inputs)loss2d_init = criterion(outputs2d_init, labels2d)loss2d = criterion(outputs2d, labels2d)loss3d = criterion(outputs3d, labels3d)loss = (lambda_1)*loss2d_init + (lambda_1)*loss2d + (lambda_2)*loss3d
实现细节
模型训练
针对不同步骤的模型进行分开训练;
- 数据增强的方式提高模型的健壮性;

若有收获,就点个赞吧
0 人点赞
