论文原文:Convolutional Pose Machines 作者信息:Shih-En Wei, Varun Ramakrishna, Takeo Kanade, Yaser Sheikh 代码参考:https://github.com/namedBen/Convolutional-Pose-Machines-Pytorch 博客参考:https://blog.csdn.net/JerryZhang__/article/details/97562875
文章的主要贡献是对结构化预测任务(如人体姿态估计)中的变量之间的长期依赖的隐式建模。具体来说,文章设计了一种由卷积神经网络构成的序列架构,整个预测流程分为多个stage,后面的stage使用前一个stage输出的belief map作为输入的一部分,与当前stage的卷积结果进行合并;这样随着stage的增加,得到更好的关节点位置的预测结果。另一方面,文章提出的方法通过目标函数强制生成中间监督,从而对梯度进行增益并调整学习过程,解决了梯度消失的问题。
仍旧是级联架构。如何建立长期依赖:We find, through experiments, that large receptive fields on the belief maps are crucial for learning long range spatial relationships and result in improved accuracy
方法
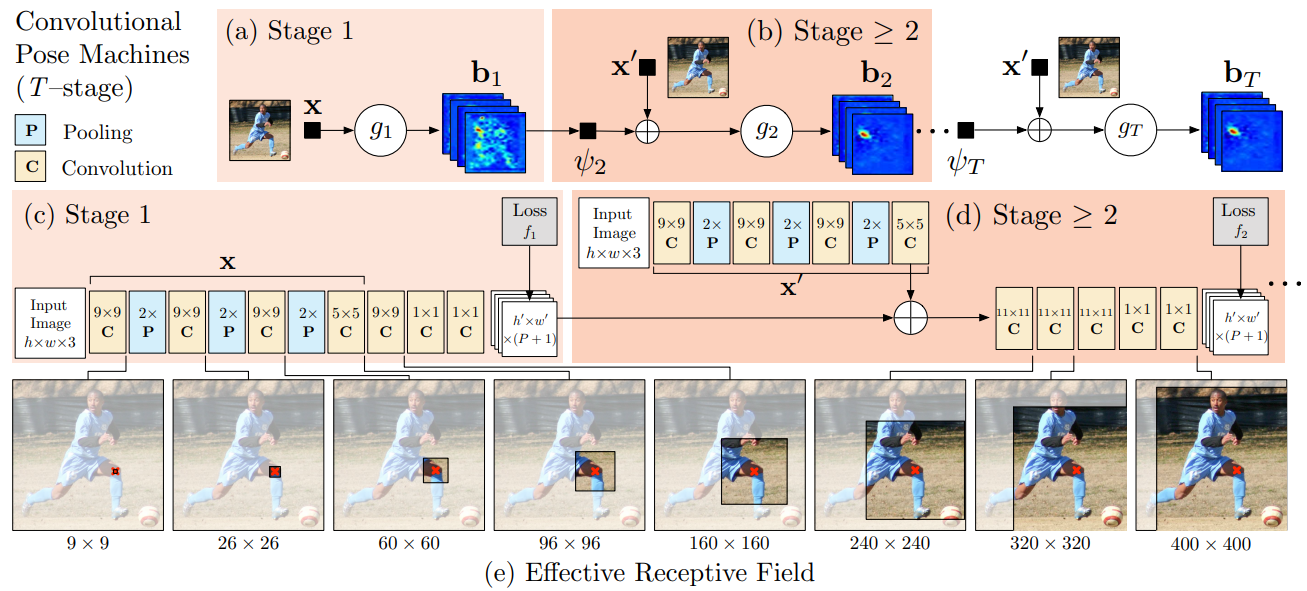
如上图所示,其中:
 表示提取的特征图,在每一级都会进行提取:见(c)和(d)所示,他们后半部分是为了映射为 belif maps 用于中继监督
表示提取的特征图,在每一级都会进行提取:见(c)和(d)所示,他们后半部分是为了映射为 belif maps 用于中继监督 是一个预测器(文中称其为“分类器”),它的目标是产生
是一个预测器(文中称其为“分类器”),它的目标是产生  (关节点总数+背景)张 heatmap(每个像素点是对应关节点的概率),从图中可以看出来,就是几个卷积层
(关节点总数+背景)张 heatmap(每个像素点是对应关节点的概率),从图中可以看出来,就是几个卷积层
 是一个映射函数,将 belief maps 映射为上下文特征,实际上没有显式函数,就是 belief maps 内部包括的感受野信息
是一个映射函数,将 belief maps 映射为上下文特征,实际上没有显式函数,就是 belief maps 内部包括的感受野信息 即是 belief maps,编码了关节点的坐标信息以及感受野信息
即是 belief maps,编码了关节点的坐标信息以及感受野信息
中间层都是:上一级的 belief maps 和当前级提取的 feature map 共同作为输入,这样其中的 belief maps 就可以随着层级的深入而不断获取更大的感受野,并且由于每一级又会重新提取 feature map 就能够弥补不断深入 pooling 造成的信息损失。
中继监督
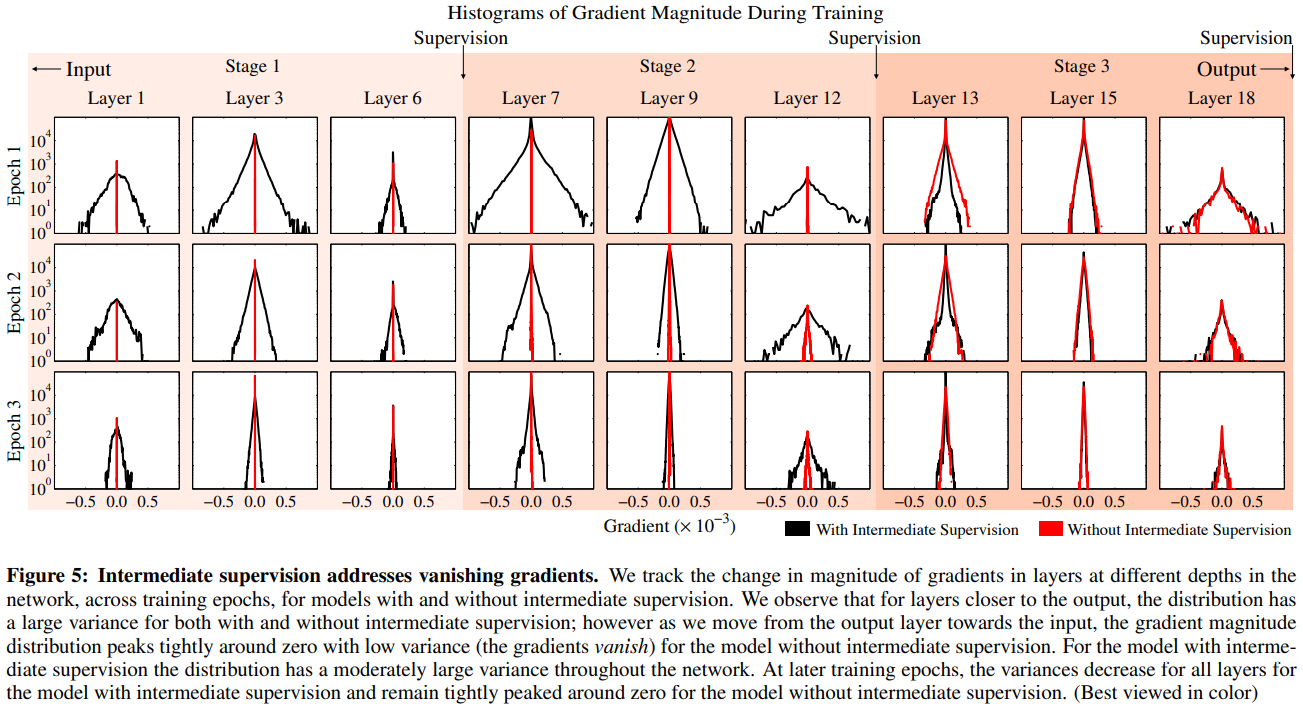
训练
损失函数
每一级的损失函数: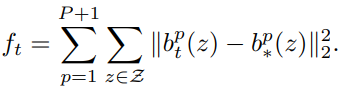
最终总的损失函数: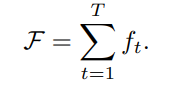
网络在
级时,网络的参数共享(意思就是说后面几级无需再计算
,直接采用
级的结果
更少的参数,模型更小)
梯度分析?Joint trainning(end-to-end training)?中继监督?级联结构?如何效果?
论文结果
1.MPII数据集上,PCKh@0.5为87.95%,在比较难预测的ankle关节上,PCKh@0.5为78.28%;
2.LSP数据集上,PCKh@0.5为84.32%;
3.FLIC数据集上,PCK@0.2在elbow关节和wrist关节上分别为97.59%和95.03%。

若有收获,就点个赞吧
0 人点赞
