人体姿态估计分类
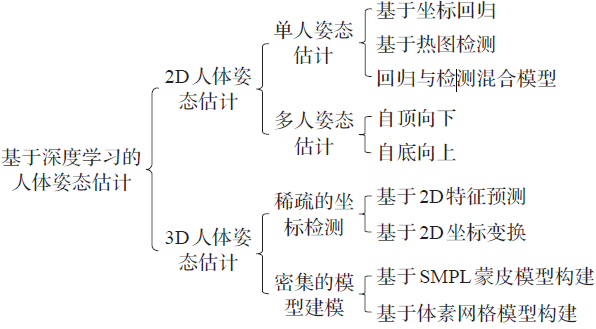
2D人体姿态估计
2D人体姿态被表示为人体骨骼关节点的二维坐标位置以及各关节点之间的连接关系。
其可以分为单人检测和多人检测,其中多人又可以分为两类(核心是单人人体姿态估计):
- 自顶向下:
- 首先进行人体检测,然后进行人体关键点检测;
自底向上:
- 首先进行关键点检测,然后进行关键点聚类;
单人人体姿态估计

基于坐标回归
基于坐标回归的模型将关节点的二维坐标(coordinate)作为Ground Truth,训练网络直接得到每个关节点的坐标。这种回归问题模型简称为Coordinate Net,基于深度学习的单人姿态估计算法在早期一般采用这种设计思路,直到基于热图(heatmap)检测的模型出现。
Coordinate Net 一般采用多阶段(multi-stage)回归的设计思路,根据迭代误差方式的不同,分为多阶段直
接回归模型和多阶段分步回归模型。
(1)多阶段直接回归
Deep Pose[5]作为第一个基于深度学习进行单人人体姿态估计的方法,采用多阶段回归的思路设计CNN,以coordinate 为优化目标,直接回归人体骨骼关节点的二维坐标。该方法在初始阶段得到关节点的大概位置,然后在后面多个阶段不断地优化关节点的坐标。为了得到更高的准确率,在进入下个阶段的回归之前,作者以当前得到的关节点坐标为中心,在其周围邻域切取小尺寸的子图像作为本阶段回归的输入,为网络提供更多的关节点图像细节以不断修正其坐标值。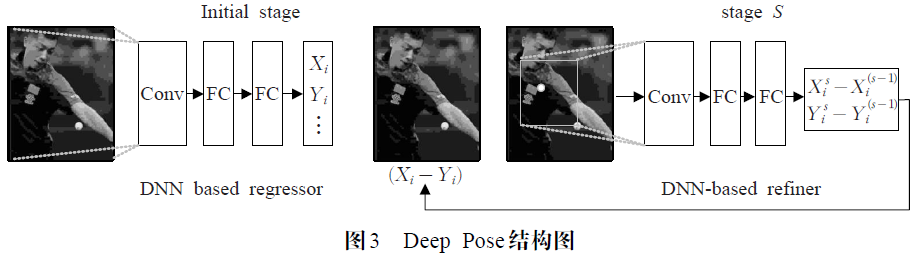
(2)多阶段分步回归
Carreira等人实现基于迭代误差反馈的人体姿态估计模型,简称IEF。该方法使用coordinate 作为迭代目标,虽然没有基于heatmap 构建Ground Truth,但是由于heatmap 可以表达概率分布特性,能在一定程度上反映各个关节点的空间信息,IEF 将heatmap 作为feature map 同包含纹理信息的原始图像级联起来输入网络(实际应用时,heatmap哪里来?),多阶段回归关节点位置。
IEF多阶段回归采取一种新策略,并不类似于Deep Pose等方法多阶段端到端地进行一个批次(epoch)训练,而是在训练时分为4 个阶段,每个阶段进行3 个完整的epoch 迭代。所以IEF 并不是每个阶段都对总的坐标误差进行梯度下降,而是取总误差的一部分作为本阶段的迭代目标,相当于进行分步回归,将部分误差的迭代结果反馈给网络。如果说直接回归的方法使模型学习逼近长程坐标的能力,那么分步回归可以训练网络更加精确地逼近短程坐标。测试时IEF 进行3 个阶段的分步回归即可接近实际值。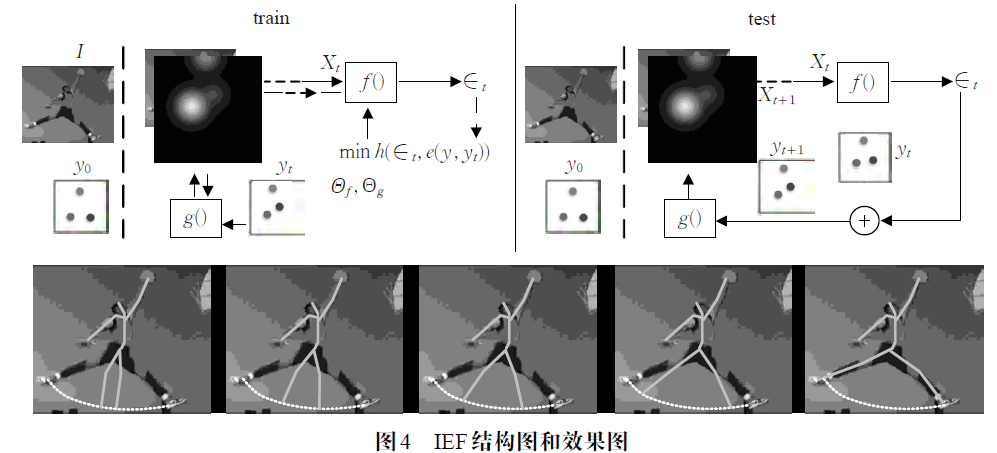
基于热力图
用概率图heatmap来表示关节点坐标,简称Heatmap Net。其估算图像中每一个像素对应的概率值,像素点位置越接近关节点,其对应的概率值越接近1,越远离关节点越接近0。因此可以使用多元高斯模型将coordinate 转换成heatmap 形式的Ground Truth,对特征图(feature map)每个像素的概率检测值进行监督训练,最后heatmap 形式的feature map 结果映射到原图像域得到关节的坐标,这种情况相当于检测问题。由于heatmap 不仅可以反映像素属于各个关节点的概率分布,还提供了关节点本身和关节点之间的图像特征,Heatmap Net 就可以为坐标检测过程提供先验(???),进一步提高多尺度多视角下关节点位置估计的精度。目前基于热图检测的模型取得的效果最好,应用也最为广泛。
相较于Coordinate Net 直接基于二维坐标Ground Truth 进行回归的算法,Heatmap Net 不仅构建了基于概率分布的Ground Truth,同时添加了一些人体部件之间的结构信息。根据网络模型学习获取关节点结构关系方式的不同,Heatmap Net 大致可以分为显式添加结构先验和隐式学习结构信息两种。
(1)显式添加结构先验
Heatmap Net在为各关节生成heatmap 后,可以基于概率图模型并参照人体各关节点的连通性,显式地搭建图结构或者树结构的先验网络连接关系,使网络模型在训练之前就具备了人体结构的先验信息,训练过程相当于人为地控制各个关节点信息在网络中的流向,并提升网络对这些特征信息流的敏感度,通过对特征信息流的整合学习,训练各个关节点或者关节点组件的部件检测器。
图结构模型。Tompson等人将CNN和图结构模型进行联合训练。该方法的CNN在提取图像特征时采用了多分辨率机制(常用的技巧,可以深入了解一下),这样在构建heatmap 时综合了关节点特征的局部细节和全局信息,保证了后续使用图结构处理heatmap 的像素分类准度和坐标定位精度。由于原始输出的heatmap 存在不正确的关节点概率信息,作者使用马尔科夫随机场(MRF)过滤那些异常节点。MRF 是一种基于马尔可夫性来描述相邻节点变量之间条件概率分布的无向图模型,作者首先将人体关节点抽象成变量节点,基于heatmap 得到每个节点变量的概率分布,然后使用MRF对所有相邻关节点组成的节点对(pair-wise)进行heatmap 建模,并构建相应的网络结构计算每个pair-wise 内的条件概率分布,使得一个pair-wise 内的节点可以互相修正相邻节点的heatmap,节点之间的这种影响被称之为亲和力。
模型最终会得到每个关节点的heatmap,以及与之有关的所有基于条件概率的heatmap,即亲和力图。将两种heatmap 级联便得到被亲和力图修正的heatmap,最终的heatmap 实际上表达了每个pair-wise的联合概率分布。因此每个pair-wise 关系需要构建4个(如图5所示)子网络模块作为部件检测器进行训练,2 个用于训练heatmap,2 个用于训练亲和力图。整体的MRF 进行训练时,不断删除联合概率较小的冗余pair-wise 关节点(最后综合了heatmap和pair-wise信息之后的联合概率),即可优化人体所有关节点的联合概率分布,生成一个相对准确的完整人体姿态关节点位置分布图。但是,如图5 所示,基于pair-wise 关系构建的MRF 模型需要大量部件检测器进行训练,这使得网络结构比较复杂。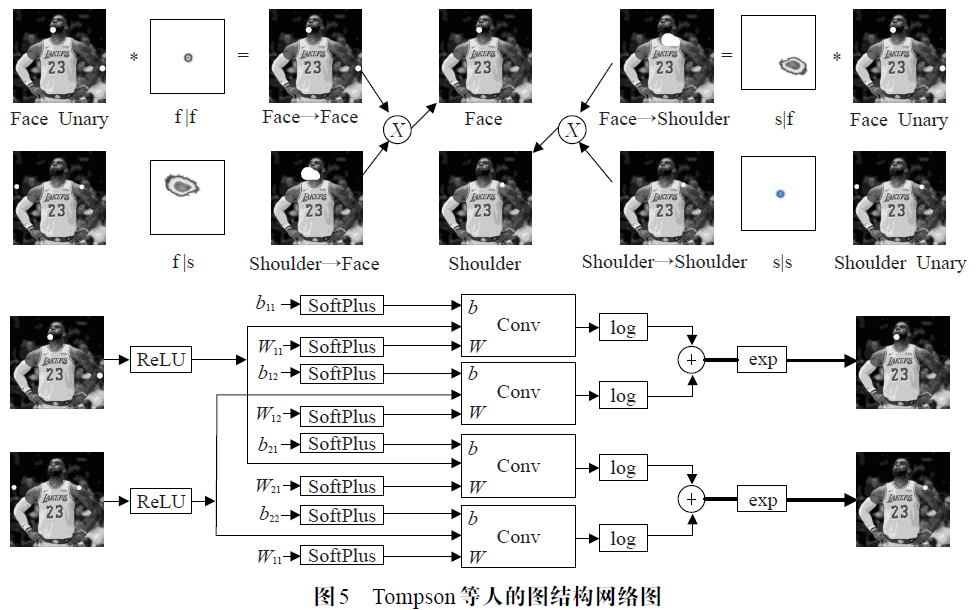
树结构模型。为了相对简化网络结构和训练规模,Yang 等人使用树状结构对整个人体所有关节点进行建模,得到一颗人体关节点关系树。本文同样采用联合训练的思路,将人体部件混合构建的树结构模型与深度卷积神经网络(DCNN)一起进行端到端的训练。该方法基于整个人体的关节联通关系构建了一组消息传递层,网络的连接关系以及消息传递路径类似于MRF,树结构相当于对图结构进行了网络压缩,合并了一些部件检测器,将所有的pair-wise 关系整合到一个单独的树形结构中,实际上消息传递层的输入层就是各个关节部件的heatmap,中间层结果类比于亲和力图,输出层也即softmax 分类层的输入是由前两者融合而成,整个消息传递层所传递的信息依然是树结构的联合概率分布。但是,如图6 所示,即便是采用整体的树结构,这种基于概率图模型的DCNN仍然包含大量网络参数,导致计算效率低下。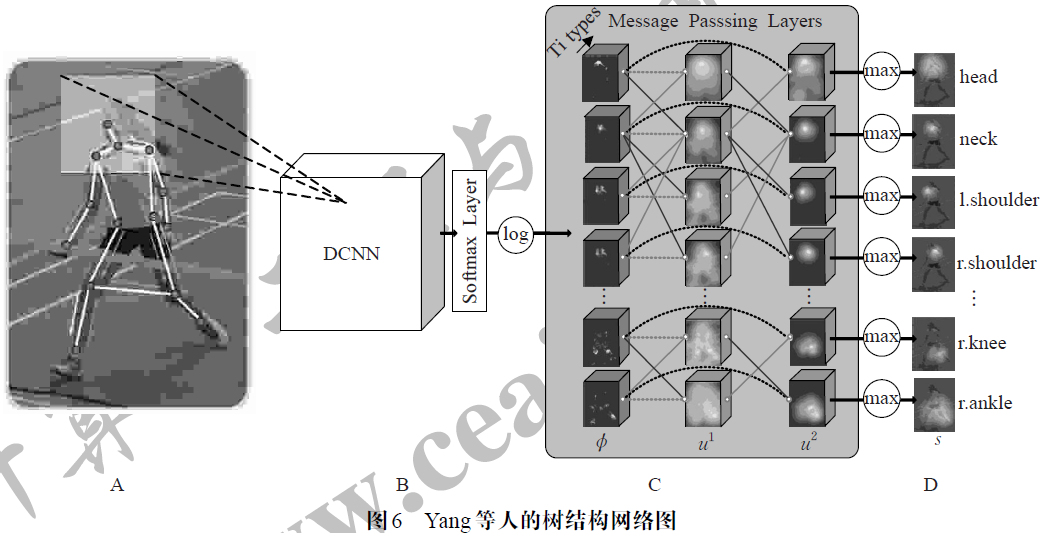
概率图模型结构除了网络结构复杂,还存在先验结构泛化能力弱的问题,虽然图结构或者树结构考虑到了各关节的先验分布情况,但是在构建网络时平等对待所有的连接关系和定位关系,并将基于同样先验分布建立的网络模型用于不同待处理图片进行人体姿态估计,并没有考虑到不同图片中的实际定位对先验分布服从程度的不同。为此,赵勇等人提出了一种基于条件先验的人体模型,在人体模型中添加自适应调节参数,参数值根据待处理图片中关节可能定位与外观模型相似度的大小来确定,从而达到根据待处理图片自适应调节先验分布在计算关节定位概率时所起作用大小的目的,增强了先验结构的泛化性能。
(2)隐式学习结构信息
固然Heatmap Net 可以基于概率图模型学习人体各关节的结构信息,但是显式地表达各个部件检测器之间的依赖关系使得网络连接错综复杂。目前大部分方法主要基于大感受野(Receptive Field)机制来隐式地学习人体结构信息。感受野的定义是CNN每一层输出的feature map 上每个像素点在原始图像上映射的区域大小。感受野的值越大表示网络能学习到的原始图像特征范围就越大,也意味着它可能蕴含更为全局,语义层次更高的特征;相反,值越小则表示其所包含的特征越趋向局部和细节。因此可以通过扩大heatmap 的感受野,使网络学习远距离的关节点连接特征,获得语义层次更高的关节点结构信息。实际上这种基于大感受野隐式学习结构信息的方法具有很强的泛化性、鲁棒性,很多方法都是基于此改进的。
增大感受野的方法大致有三种:扩大池化(pool)层、增大卷积核、累加卷积层。但是三种方法都存在各自的设计缺陷:过大的pool 操作会牺牲精度,如果通过反卷积还原精度则会添加大量的额外信息;增大卷积核相当于增加参数量,过于耗费计算资源;不断累加卷积层的代价是梯度消失。目前主流的网络结构在基于这三种方法构建的同时,立足于解决增大感受野所产生副作用。成熟的设计思路包括:基于顺序卷积结构和基于沙漏网络结构等。
顺序卷积结构经典的卷积姿态机(Convolutional Pose Machines,CPM)借鉴了Coordinate Net 中多阶段卷积的结构,构建多阶段级联(cascaded)的深度网络,采用11×11 大卷积核不断地累加卷积操作,使每个子网络按照从前至后的阶段顺序得到由小到大不同的感受野,最终达到利用图像上contextual 隐式学习人体各关节结构信息的目的。同时为了促进像素级别(pixel level)的融合和多尺度感受野的梯度传导,CPM使用了全卷积(FCN)的基础网络结构,具体结构如图7 所示。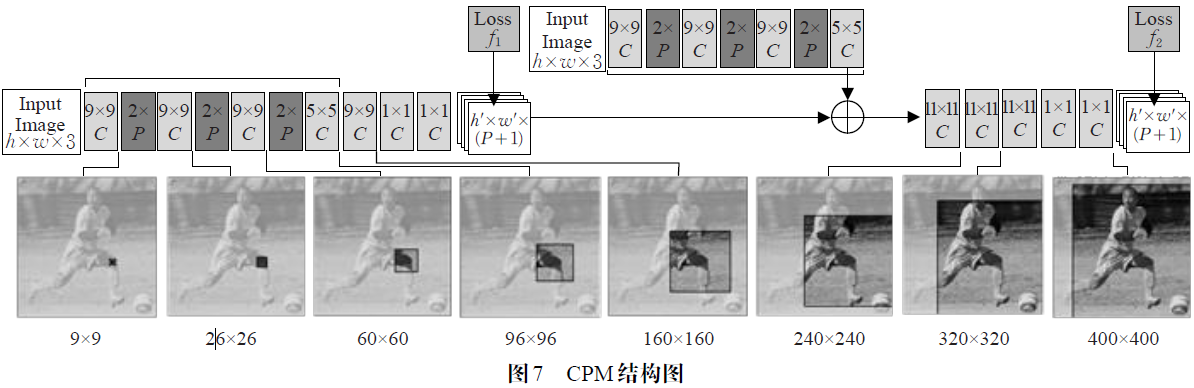
具体的CPM在初始阶段(stage 1)只对输入图片进行卷积,输出所有关节点的heatmap。在后面的每个阶段中,CPM首先设计了一个特征提取器(FeatureExtractor)将上一个阶段输出的heatmap 和原始图像的feature map级联起来,然后将这种预处理过的融合feature map 输入本阶段的FCN进行处理,最终得到新的关节点heatmap。但是通过不断增加卷积层来改变感受野会给网络产生较大的训练负担,造成梯度消失等问题。为避免加大感受野带来的副作用,CPM采用中继监督训练,将各个阶段产生的heatmap 与Ground Truth 产生的误差累加起来作为总误差进行迭代,同时将梯度从各个阶段网络的输出层反向传播,避免梯度消失,最后得到各个阶段修正后的响应feature map,即置信图(belief map)。CPM在测试时以最后一个阶段的响应图输出为准。
沙漏网络结构相较于CPM的顺序卷积结构,沙漏网络结构适当缩小了卷积核尺寸,并对特征提取器进行了改进,最终构建的模型也更加简洁高效。尤其是Newell 等人的堆叠式沙漏网络(SHN),综合借鉴了很多单人体态估计方法中的模型结构和训练技巧(trick)。SHN 总体的设计思路仍然是一方面利用多分辨率的heatmap 学习关节点的局部位置特征,一方面通过多尺度感受野机制学习获得关节点之间的结构特征。网络结构参照残差网络进行构建,基本卷积模块采用类似于文献中Inception 的残差模块(Res Module),如图8 所示。Res Module 结构中的shortcut 分支在深层梯度传导和防止深层网络过拟合方面起到关键作用,同时利用1×1 卷积核减少通道数来压缩参数数量。在继承了残差网络的优点之后,基于Res Module 构建了沙漏结构(hourglass),如图8 所示。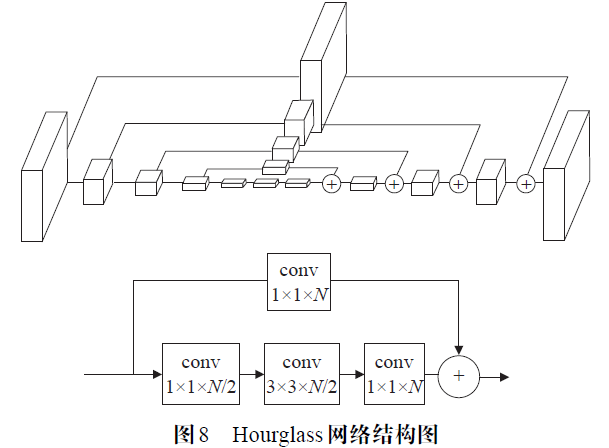
图中每个方框分别对应一个由3 个Res Module 结构组成的残差模块。首先在hourglass 的前半部,使用卷积和降采样(Max Pooling)操作得到不同分辨率的图像,并逐渐扩大感受野。hourglass 在其中心得到最低分辨率和最大感受野的feature map 后,同样基于分支结构(shortcut),向该模块的后半部传递所有分辨率的特征,然后结合shortcut 分支上的特征与主干网路上较低分辨率的特征进行最近邻上采样(nearest neighbor upsampling),逐步恢复特征的细节并在模块最后输出一个高分辨率的heatmap。整个hourglass 的前后两部分是对称的,每一个降采样层对应一个上采样操作。随后文章借鉴了多阶段网络结构的特点,将多个hourglass 级联在一起,一个hourglass 作为一个阶段,得到了最终的SHN(Stacked Hourglass Network),其结构如图9 所示。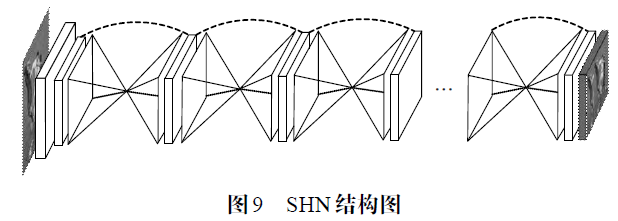
类似于CPM的多阶段学习过程,堆叠式沙漏结构同样采用了“配套的”中继训练。但是SHN对每一个阶段得到的关节点heatmap 立即根据Ground Truth 进行重绘(remap),并得到当前的belief map,而不是像CPM累加所有阶段的总误差再进行迭代反馈。这种策略利用前一个阶段估计的结果为后一个阶段的优化提供了参考依据,同时在后一个阶段的监督学习中隐式地评估了之前阶段学习的特征。如图10 所示,SHN 在训练下一个阶段时构建了类似于CPM的特征提取器,将三部分的特征融合输入到下个阶段,即本阶段remap 之后的heatmap 和本阶段最后输出的feature map,以及上一个阶段通过残差结构传递过来的低分辨率特征。作为比较,图的CPM特征提取器在后续阶段进行训练时,只级联两部分的特征,即本阶段feature map 和上阶段未经误差修正heatmap。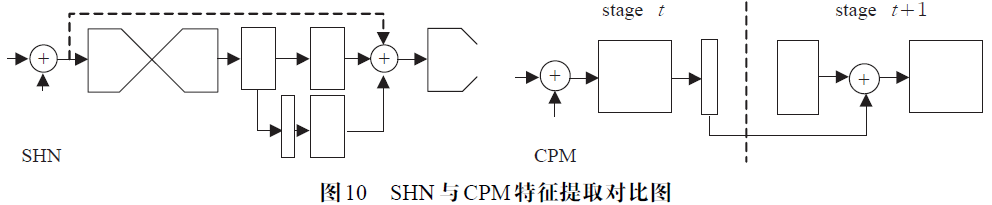
SHN通过级联的hourglass 和中继监督训练为网络提供了重复自下而上、自上而下推理的机制,允许重新评估整个图像的初始特征和检测结果,隐式地学习到了人体关节点的图像特征和它们之间的结构信息。并且相较于其他方法,这种基于hourglass 的网络模型拥有更加简明且易于扩展的结构,表现出了更加准确高效的性能。回归与检测混合模型
回归与检测混合模型结合了上述两者的特点,构建组合式的Ground Truth,同时进行检测和回归任务,网络模型包含Coordinate Net 和Heatmap Net 的子结构。
Heatmap+Coordinate 的复合式网络模型在构造上基本参照Coordinate Net 和Heatmap Net 的网络结构,通过串联或者并联结构将两者直接级联在一起。网络在训练时使用heatmap 和coordinate 构建的两种Ground Truth,希望在检测与回归两个过程的共同作用下保证姿态的估计精度。
(1)串联结构
Bulat 等人提出了通过对关节点heatmap 进行Coordinate 回归的串联结构。如图11 所示,网络整体分为部件检测器和回归网络两部分,通过对heatmap 的回归较好地解决了关节点的遮挡问题。作者考虑到被遮挡部位的heatmap 响应值比较低,经过回归模块之后这些低置信度的heatmap 对于后面坐标修正的影响较小,因此,在部件检测器之后串联回归网络模块可以学习到更多关节点互相依赖的语义信息,也即使用其他部位的结构信息来正确地预测被遮挡的关节点位置,在回归模块中同样设计了大小不同的卷积核并尝试了基于hourglass的回归方法。
(2)并连结构
Fan 等人提出的双源卷积网络(DS-CNN)构建了两个并行的网络模块,即关节点检测网络(joint detection)和关节点定位回归网络(joint localizition),具体结构如图12 所示。joint detection 用于检测图像补丁(Part Patch)包含的局部关节点类别信息;joint localiztion 模块通过结合整幅图像(Body Patch)和Part Patch 的二进制掩码回归关节点位置坐标。两个子网络进行交互式的辅助训练,例如joint detection 模块利用Body Patch的全局特征判断腕关节的左右属性;同时joint localiztion模块根据Part Patch 的局部信息归一化位置坐标。
Heatmap+Coordinate 的复合式网络模型综合了回归与检测模型的优点,但从特征提取的角度来看,复合式模型的改进本质上是源于局部关节特征对全局人体特征的监督性质。模型通常使用回归网络模块处理整幅图像的特征,但是大量背景特征会对人体姿态特征的处理产生干扰,这时该类方法的检测模块可以利用噪声较少的局部关节特征强调人体姿态特征,进而弱化背景特征产生的影响。基于这种特征处理思路,韩贵金等人针对不同图像区域特征被平等对待的缺陷,提出了一种基于加权支持向量数据描述算法(SVDD)的人体姿态估计方法,使CNN 中不同图像区域的卷积操作被赋以不同的权值系数,以充分体现不同特征的不同作用。同时SVDD算法对每一种特征都构造关节子外观模型,按不同权值对所有关节子外观模型进行线性组合建立人体结构信息。
目前的人体姿态估计方法基本上是基于深度学习来研究的,其中单人2D人体姿态估计的相关算法是其他姿态估计方法的基础和核心。在具体的网络模型构建上,检测人体关节点2D坐标的一个关键问题就是如何使网络学习到各部件的纹理特征信息和部件间的语义结构信息,并用端对端的方式进行训练。Coordinate Net 采用多分辨率提取行图像特征和多阶段回归关节点坐标等方法,学习到了关节点丰富的纹理信息,得到了一定精度的位置坐标,但是这种直接回归坐标的方式没有很好地学习到人体的结构信息。Heatmap Net 在借鉴了Coordinate Net 的同时,通过构建概率图模型或者利用多尺度感受野学习到了重要的关节点结构信息,并结合多阶段的网络级联和中继训练等trick 得到了较高的关节点检测精度。近期的大部分方法都是基于heat-map 的检测模型,为了得到更好的效果,有一些方法尝试了检测与回归的混合模型,例如将Heatmap Net 和Coordinate Net 的结构进行组合,进行交互式和端到端的训练,但是为了得到质量较高的heatmap,模型往往采用很大的卷积核以及很深的网络,导致效率难以提升,同时朴素的卷积操作会得到大量噪声特征,这些可能需要借助于机器学习的其他方法加以解决。另外在多人2D 人体姿态估计中提出了一些改进的单人姿态检测器,但是本质上还是基于上述单人姿态估计的相关方法。
多人人体姿态估计
主要分为两种:自顶向下 & 自底向上。自顶向下
分为两步
- 首先进行关键点检测,然后进行关键点聚类;
首先利用检测算法检测人体,得到检测框;
- 对检测框里面的人体进行单人人体姿态估计;
主要问题一部分来自于人体检测算法
- 冗余检测;
- 定位偏差;
- 漏检等;
因此两步法(Two-step Framework)的第一步,即构建人体检测器是决定第二步单人人体姿态检测器(Single Person Pose Estimator)姿态估计效果好坏的关键。
大部分算法致力于通过改进非极大抑制(NMS)策略来提升第一步中回归Human Proposals 的精度。多人姿态检测算法中优化提议框(Proposals)的相关策略包括NMS、Soft NMS、p-Pose NMS、OKP NMS等。事实上,单人姿态检测器对于Proposals 的偏差是非常脆弱的,由于在一副多人图像上存在人体的互相重叠,人体尺度相差悬殊等复杂情况,有时还需要构建专门用于处理Proposals 的网络。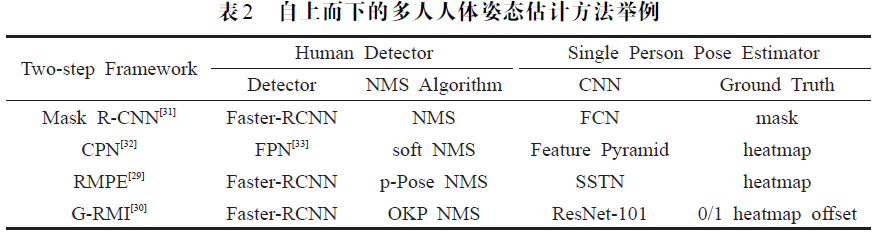
Mask R-CNN的构造如图13 所示,其在第一步使用Faster R-CNN 作为人体检测器(Human Detector),生成人体候选区域(ROI),并采用非极大抑制(NMS)策略过滤ROI中的冗余Proposals。然后在第二步利用FCN作为单人人体姿态检测器(Single Person Pose Estimator)的基本网络结构。Ground Truth 基于掩码(mask)构建,将每个关节点的位置建模为一个二进制单点mask(onehot binary mask),即mask 中只有一个关节点像素标记为前景值1,其他设置为背景值0,相当于heatmap 只保留概率值为1 的关节点像素。姿态检测器使用FCN对ROI 内的单人人体的feature map 进行卷积池化和反卷积操作,得到大感受野和高分辨率的特征输出,同时利用RoIAlign 算法中的双线性差值进行像素到像素的对齐(pixel-to-pixel alignment),级联边界框回归和关节点类别检测模块。对于一个实例的K 个关键点,网络采用softmax 输出K 个56×56 像素的mask feature map,K 个mask 之间相互独立地对每个像素的误差值进行交叉熵损失迭代,最终使关节点像素的输出为1,其余输出为0。测试时Proposals 回归和关节点检测没有像训练时并行处理,网络首先使用NMS 策略,过滤冗余的Proposals以避免姿态的重复检测,然后再进行mask 关节点检测,最后将56×56 的尺寸调整(resize)到ROI 的大小,并采用0.5 的阈值对所有像素的输出进行0/1二值化。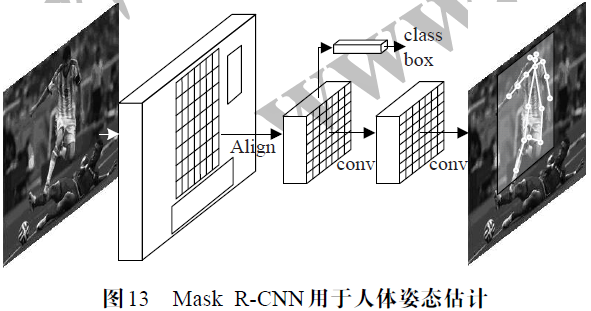
CPN在构建人体检测器时,使用soft NMS 取代Mask R-CNN 中的NMS。具体的,为了避免对人体的重复检测,需要提取分数最高的框并且抑制那些分数低的框,NMS 的做法是直接将交并比(IOU)大于一定阈值的框和得分较低的框去掉,因此这种策略在人体目标分布较为密集的图片中召回率较低,容易出现漏检的情况。针对上述问题,soft NMS 将IOU 较大的框中分数较小的那个框的置信度大幅衰减,而不是直接去除掉。但是,衰减后的分数仍然会比明显的假阳性结果要高,这样soft NMS 保证了CPN在多人重叠情况下有相对较高的召回率。另外CPN在构建单人人体姿态检测器时采用了多阶段的策略,如图14 所示,其级联(Cascaded)了两个子阶段网络模块GolbalNet 和RefineNet。但是CPN的多阶段任务划分思路与其他单人姿态估计算法不同,CPN不是在每个子网络进行近乎相同的任务,即对所有的人体关节点进行检测,而是将任务划分为由简到难两个阶段。第一阶段,GlobalNet 负责所有关节点的检测,重点是提高一些易于识别的人体关节点位置的检测效果,第二阶段,Refine Net 对GolbalNet 预测的结果进行修正(Refine),对一些存在遮挡或者背景复杂的关节点的预测进行Refine。其中GlobalNet 的构建参考了FPN[33]的特征金字塔结构(Feature Pyramid),这种结构可以简单的前向卷积传播,得到不同尺度不同感受野的feature map。GlobalNet基于heatmap的Ground Truth进行迭代,同时将金字塔在不同层级进行了特征融合,但是不同于SHN 简单的upsampling 融合,这里采用串联(concatenate)的策略,将不同尺度的feature map 进行融合输入到下个阶段的RefineNet。在第二阶段的训练中,RefineNet 继续对feature map 进行卷积以进一步获得更高层的语义信息,同时还结合了类似OHEM(Online Hard Keypoints Mining)的难例挖掘策略来解决较难检测的关节点位置估计问题。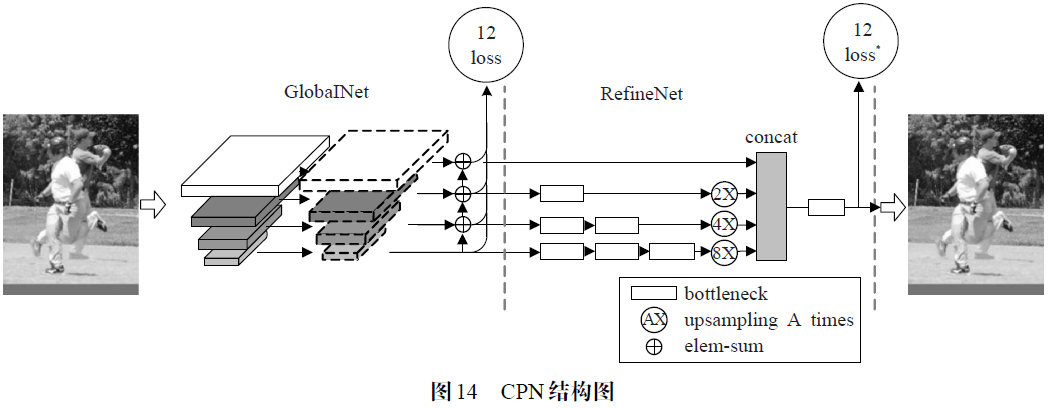
RMPE[29]不仅进一步改进了NMS 而提出参数姿态非极大抑制(p-Pose NMS),并且构建了专门用于处理Human Proposals 的空间变换网络(STN)(实际上,后来Github项目没有采用此单元),通过单独训练STN可以在不精准的框中提取到更高质量的Proposals。相当于先对原始框进行裁剪,然后使用p-Pose NMS 对这些优化过的框进行筛选。如图15 所示,首先通过目标检测算法,例如Faster-RCNN,得到Human Proposals,然后将该Proposals 和图像输入到对称空间变换网络(SSTN)中。SSTN由空间变换网络(STN)、单人姿态检测器(SPPE)以及空间解变换网络(SDTN)构成。首先使用STN 对输入的Proposals 进行变换,修剪多余图像使人体位于Proposals 的正中央,然后通过SPPE 进行单人人体姿态估计,最后在SDTN中采用与STN变换相反的操作将估计的人体姿态反映射回原图坐标中。训练时,对SSTN 进行端到端的训练,同时级联平行的单人姿态检测器(Parallel SPPE)对STN 模块进行专门的增强训练。在Parallel SPPE 的输出端制定一个中心定位姿态Ground Truth,并且冻结Parallel SPPE 的所有权重更新,将姿态定位后产生的误差全部反向传播到STN模块,通过这种方式可以帮助STN 聚焦在正确的中心位置并提取出以人体为中心的高质量Proposals。最后RMPE 通过p-Pose NMS 进一步消除冗余的检测结果,p-Pose NMS 设计了一种姿态距离(Pose Distance)度量机制,通过计算关节点置信度的软匹配函数和临近姿态间各个关节点的欧氏距离来衡量姿态之间的相似度,并消除那些距离较近的姿态。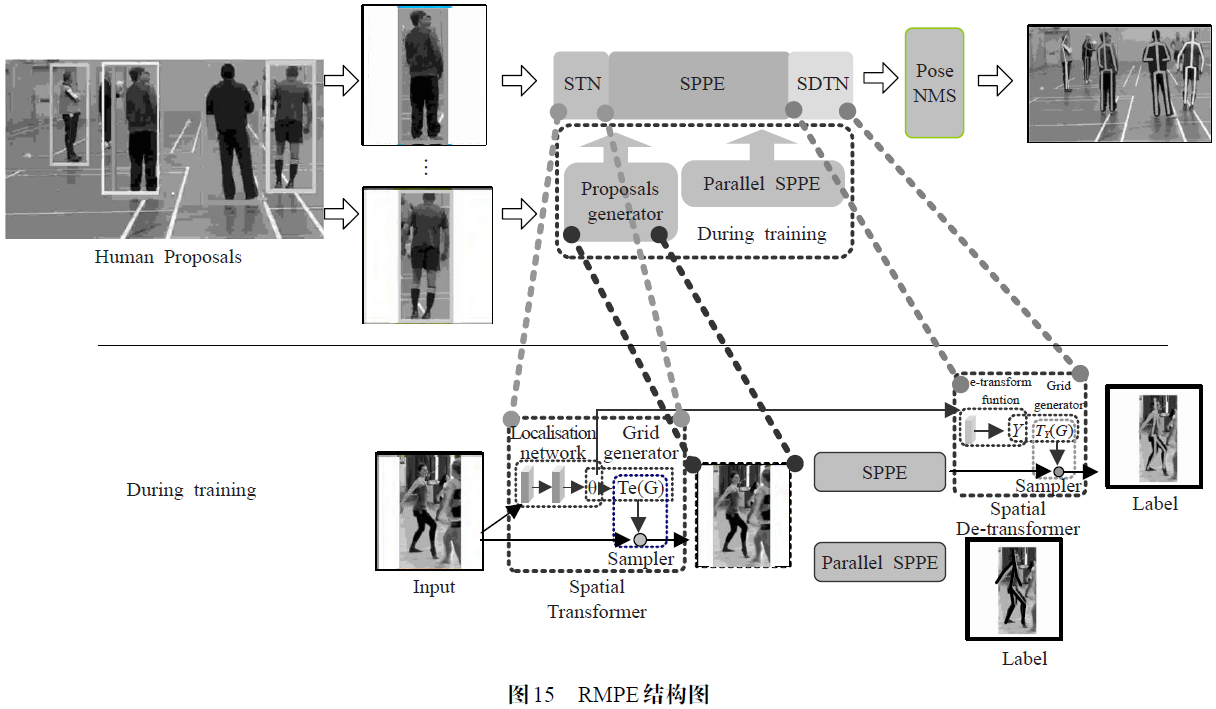
G-RMI是Google提出的多人体态估计方法,将 NMS与人体关节点评价指标(OKS)相结合,设计出了 OKP NMS。相较于p-Pose NMS采用欧氏距离来进行 姿态距离度量,OKP算法使用了人体的尺度信息对临近姿态关节点对间的欧氏距离进行修正,来计算两点之间的相似度。
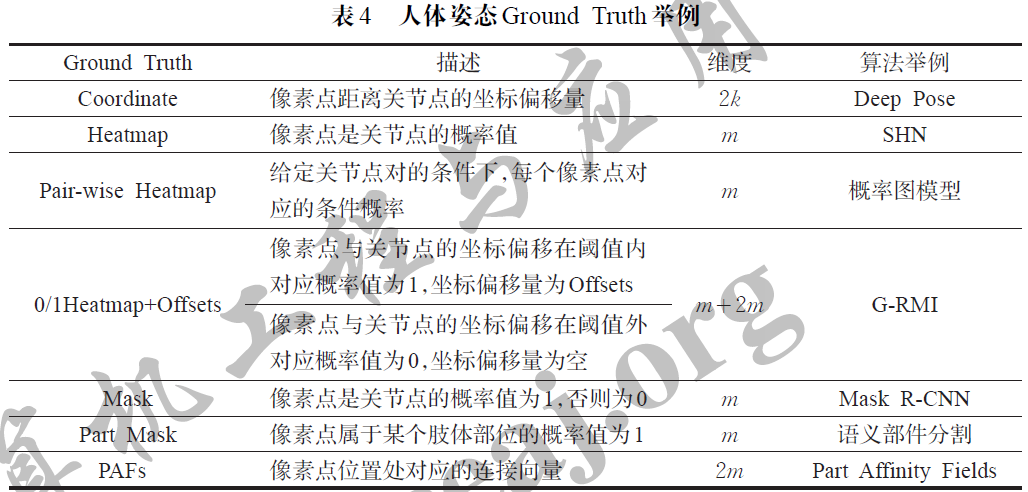
不同尺度下相同的欧氏距离所反映的偏差并不相同,可以使用边界框的面积进行归一化。除了提出OKP NMS过滤冗余姿态,提出了一种二值热图(0/1 heatmap)与坐标偏置(offsets)相结合的Ground Truth构建思路。 如图16所示,0/1 heatmap与单纯的heatmap不同,指的是在距离目标关节点一定范围内的所有点的概率值都为1,其余点为0。坐标偏置(offsets)则用来表示所有概率为1的点与目标关节点之间的指向关系。相较于高斯分布的heatmap,模型在检测0/1 heatmap时不需要得到每个像素点的置信概率值,只需得到一个包含关节点 大概的置信区域。进行坐标定位时,不必进行难度较大的coordinate全局坐标回归,由于置信区域相当于给出 了关节点位置的先验信息,可以直接在置信区域内进行offsets局部偏移回归。Heatmap+Offsets的策略同时降 低了回归任务和检测任务的难度,表现出了较好的效果和时间效率,例如PoseNet通过基于Heatmap+Offsets训 练单人姿态检测器,实现了在浏览器中实时估计人体姿态。
总体而言,自顶向下的方法在设计思路上比较直观、自然。由于单人姿态估计的方法比较成熟,在可靠的Human Proposals之内进行关节点检测可以得到非常高的精度,因此这类方法的一个研究重点就是设计合理的Proposals筛选和修正机制,保证在进行单人姿态估计时不会出现漏检、误检以及重复检测等情况。然而 Proposals的数量会随着图像中行人的增多而显著增加, 大量重叠的Proposals区域会导致重复多次的卷积操作,因此这类方法的计算效率普遍偏低。
自底向上
自底向上的人体姿态估计方法是基于部件的框架(Part-based Framework),其过程与自顶向下(Top-Down)的方法相反,算法主要包含两个部分:关节点部件检测和关节点部件聚类。其中第一个部分利用单人姿态估计的方法构建部件检测器将图片中所有的人体关节点全部检测出来,然后在第二个阶段对不同人体的关节点部件聚成一类并拼接在一起。因此Part-based Framework 的相关研究侧重于对关节点部件的聚类,相关的算法有语义部件分割(Semantic Part Segmentation)、部件亲和场(Part Affinity Fields)、DeeperCut等。
Semantic Part Segmentation的关节点部件检测器类似于Mask R-CNN 的FCN 结构,同时使用基于mask的实例分割算法帮助关节点进行连接和聚类。相较之下,Mask R-CNN在被用来做姿态估计时是基于Human Proposals 的自上而下策略,可以不使用人体mask进行实例分割,但是Semantic Part Segmentation 不仅应用实例分割算法,而且将人体mask细分为6 个肢体部件mask 作为Ground Truth,训练网络推测关节点属于特定肢体区域的能力,指导网络在对不同人体关键点进行聚类时进行正确的关节点连接。如图17 所示,该方法在使用FCN 构建部件检测器时,设计了类似于单人姿态估计中显式添加结构先验的概率图模型,使用专门的网络来学习类似于pair-wise 关系的相邻关节点(joint neighbor)预测图,并结合关节点的heatmap 构建人体图结构。在利用图结构得到的关节点位置的同时,该方法通过肢体部件mask 训练的网络得到语义部件分布图,最后为了进一步对关节点进行聚类和位置优化,关节点位置信息和肢体部件分割信息被融合到一个由全连接层构建的条件随机场(CRF),训练网络能够在肢体分布信息和关节坐标取值之间取得语义和空间一致性。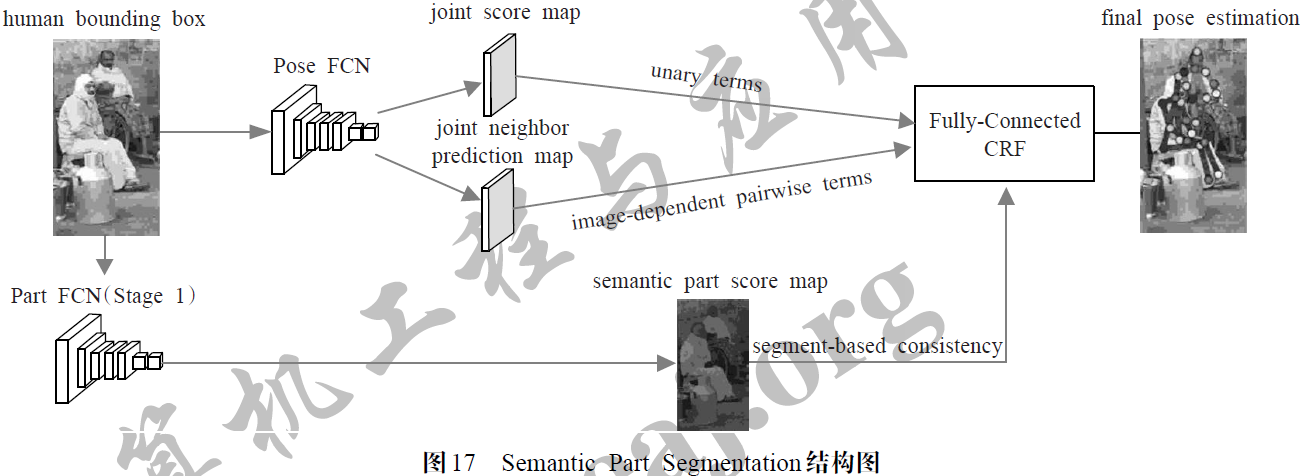
PAFs(Part Affinity Fields)设计了部位亲和场。如图18 所示,这是一种语义信息比肢体部件mask 更为丰富的Ground Truth,不仅表达了像素的类别,而且指明了肢体部件上每个像素点的指向,为关节点的聚类提供了更为直接的语义信息。由于部位亲和场描述的是关节点间的连接关系,并不像mask 用于实例分割,因此构建Ground Truth 时并没有描绘精确的肢体部位边界,而是采用长和宽指定每个肢体的部位亲和场范围,场中每个像素的指向由场两端的关节点连线方向的单位向量表示。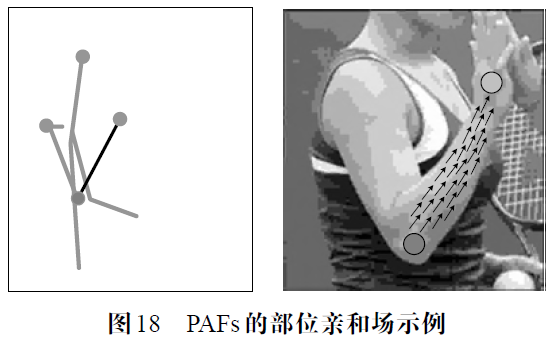
具体的,网络采用多阶段回归的思想,首先使用两个并行的子网络分别得到图像中所有关节点的置信heatmap 以及所有肢体的部位亲和场,然后分三步进行关节点聚类。如图19 所示,第一步,首先对关节点进行类别聚类,并按照人体各肢体部件的构成进一步将每两类关节点聚类成二部图(Bipartite Graph),然后使用部位亲和场的信息,提取两类关节点之间所有连线上的像素方向,并在每条连线上对所有所属像素的方向向量进行积分,积分结果代表了这条关节点连线的方向权重,权重值越大说明连线两端的关节点属于同一个肢体部位的概率越大。第二步,通过匈牙利算法(Hungarian Algorithm)对关节点二部图进行权重最大化连接,过滤掉冗余的边,得到所有的肢体部位。最后一步,基于两个相邻的肢体部位必定有共享关节点的原则,通过关节点检索可以把所有的躯干结合起来,得到每个人完整的身体姿态。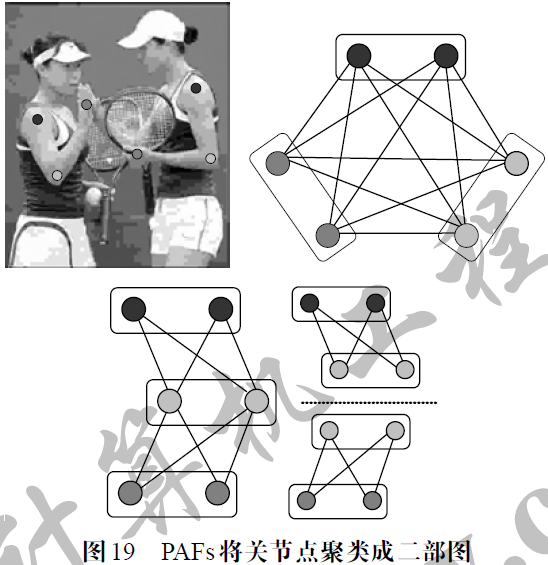
DeeperCut是DeepCut的改进版,两者原理大体相同,也采用了类似于图优化的聚类策略。Ground Truth 是三元的0/1 随机变量,表示了关节点在图中的三种关系:第一元变量表示关节点属于人体的哪一个部分;第二元变量表示关节点属于哪一个人体,图像上每一个人作为一个单独的类;第三元变量表示不同关节点是否同属一个人。其算法流程如图20 所示,首先使用CNN提取人体部件候选区域(body part candidates),每一个候选区域对应一个关节点的检测集合,所有候选关节点组成一幅密集图(dense graph),通过判断不同关节点是否同属于一个人来计算节点之间的关联性,并作为图中每条边的权重进行ILP(Integer Linear Program)图优化,使用NMS 过滤掉不同人体之间的边,最后结合人体的类别和部件的类别进一步过滤掉每个人体内部的冗余边,形成最终估计的姿态。相较于二部图机制,DeepCut 是对密集的图进行优化,这导致计算复杂度比较高。为解决这个问题,DeeperCut 使用了image-conditioned pairwise terms 算法来压缩候选区域内节点集合的数量,只保留检测质量较高的一部分点集。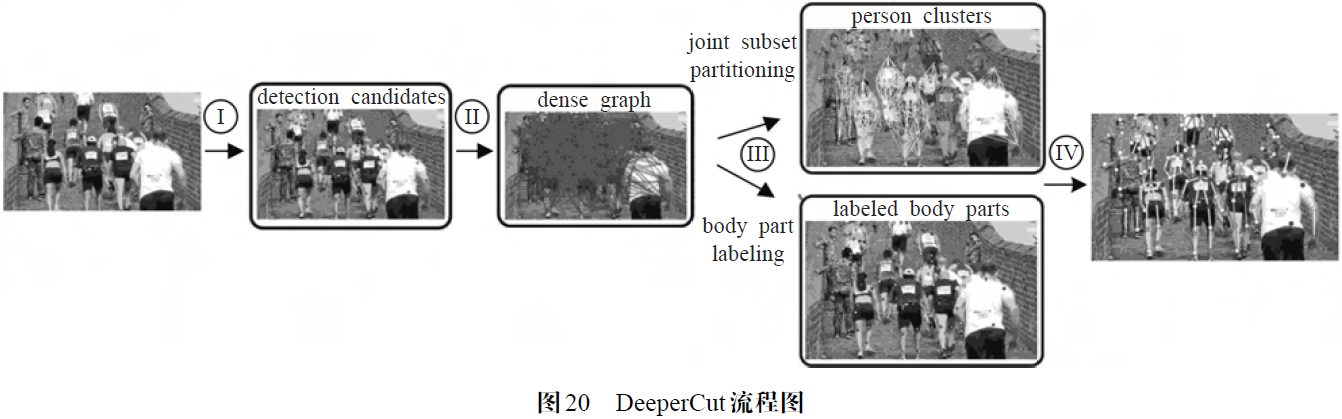
总体而言,自底向上的方法一次性检测图像中所有的人体部件,只需对整体图像特征提取一次,即使人体数目增加也不会导致重复的卷积操作,因此这类方法往往效率更高,模型更小。但是目前模型的准确度还比较低,这是由于人体关节本身存在较高的相似性,在不同光照、尺度、背景的干扰下,算法在将人体的部件聚类到不同的人体实例上时会出现匹配错误,因此如何设计合理的关节点聚类算法成为该方法的研究重点和难点。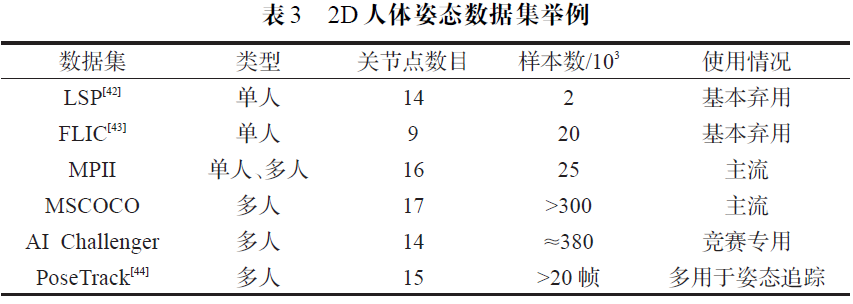
3D人体姿态估计
这些方法总体上可以用两种模型来表示:第一种是基于三维人体关节点坐标构建的稀疏模型;第二种是基于人体像素坐标映射的密集模型。其中,对整个人体表面的密集建模往往会以3D人体关节点坐标为基础进行更为细致的像素坐标映射。
稀疏坐标检测
3D 人体关节点坐标可以基于对应的2D 人体关节点坐标或者基于二维的人体姿态感知特征直接进行预测。其中,通过构建网络学习图像中二维姿态特征所包含的三维信息的方法,需要使用3D数据集来完成网络的训练过程;而另一种通过对2D坐标的变换得到3D坐标的方法相当于将二维数据升维到三维数据,具体算法侧重于设计一些先验约束和匹配规则。
基于二维特征的预测
该类型的方法侧重于利用最先进的2D姿态网络架构(例如CPM和SHN)提取2D姿态感知特征和先验知识,从2D输入图像直接恢复3D人体关节点坐标。但是由于3D数据集的匮乏,有些方法使用大量的2D姿态标注来促进网络对3D姿态和2D姿态估计任务中共享特征的学习。
例如,Wang 等人设计的自监督校正机制,可以利用大量的2D数据标注很好地辅助3D的姿态预测。所谓自监督就是利用同一个姿态的二维特征和三维特征具有的几何一致性,使得2D姿态和3D姿态可以互相监督对齐。如图21 所示,提出的3D人体姿态预测框架分为四部分:2D姿态子网、2D到3D姿态转换模块、3D到2D姿态投影模块以及自监督学习模块。其中自监督校正模块是整个架构的核心,自监督机制采用类似于对抗训练的模式,将其他几个模块产生的两种2D姿态进行对齐,对齐过程中两种姿态互为监督,并将对齐误差反馈回各自的模块进行参数训练,由于两种2D姿态的训练数据都来源于对原始图像特征的提取。
没有人工设置Ground Truth,因此整个网络框架在进行对抗训练时是一种自监督过程。两种人体2D姿态训练数据来源于自监督校正模块两个输入端各自连接的子网络。其中一个子网络由2D姿态子网组成,直接通过图片产生预测的2D 姿态;另一个子网络由2D 到3D 姿态转换模块和3D 到2D 姿态投影模块组成,前一个模块通过对2D姿态感知特征的提取并利用LSTM学习姿态变化的时序相关性直接从图像预测一个粗略的3D 姿态,下一个模块通过投影操作得到变换的2D 姿态。将预测的2D姿态和投影的2D姿态进行对齐,双向细化2D到2D和3D到2D两个过程,就可以使每个模块学习到2D姿态和3D姿态存在的几何一致性,并将二维的对齐误差反投影给3D关节点坐标做进一步校正,最终得到一个准确的3D关节点坐标。在整个网络框架执行自监督校正之前,一方面利用现有的2D和3D数据集,对各个子模块进行预训练,初始化网络参数;另一方面使用数量较多且易于标注的2D 数据集,对2D 与3D姿态相互转换的两个模块进行端到端的训练,使子网络在不借助与3D数据集的情况下学习2D姿态感知特征到3D姿态坐标之间的变换关系,减少了3D人体姿态数据匮乏对训练精度产生的不利影响。
基于2D坐标的变换
这种类型的方法专注于学习2D 到3D 姿态的映射函数。首先从2D输入图像提取2D关节点坐标,并且进一步基于这些2D坐标预测执行3D关节点的重建或者回归。具体的转换过程可以利用一些人体结构的约束信息,或者基于2D到3D的姿态匹配。
Zhou 等人提出了一种在野外环境下进行3D人体姿态估计的弱监督方法,采用弱监督的方法依然是为了解决
3D人体姿态数据不足的问题。由于3D人体姿态数据基本上采集于室内环境,为研究在野外条件下的3D人体姿态估计,该方法同样利用了大量野外环境下采集的2D人体姿态图像,来构建混合的2D和3D体态Ground Truth。该方法在将野外图像上的2D姿态映射到室内采集的3D关节点坐标时,利用了人体结构中各肢体长度之间的比例相对固定的约束信息。如图22 所示,网络主干部分的构建是基于堆叠沙漏结构的,并在此基础上设计了两个子网络分别用来回归2D的关节点heatmap 以及3D的关节点坐标。与之前的分阶段或者和分模块进行单独训练的方法不同,该网络充分利用2D姿态估计和3D姿态深度回归子任务之间的相关性,进行端到端的训练。训练原理同样类似于对抗训练,将基于约束得到的3D映射姿态与深度回归得到的3D预测姿态进行对齐,通过2D姿态子网络反向传播对齐误差到网络主干,训练并增强沙漏结构提取二维姿态感知特征的能力。同时在没有3D姿态Ground Truth 的情况下,利用人体结构的几何约束对齐3D关节点坐标,可以有效地防止3D姿态预测回归的过拟合,该过程相当于对3D姿态深度预测的有效正则化。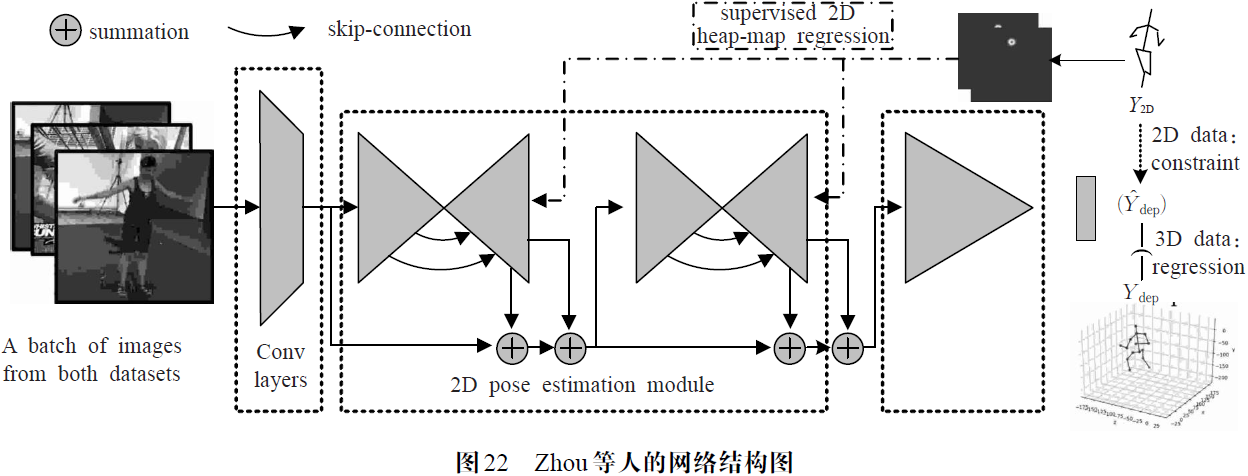
Chen 等人[47]的方法基于另一种逆向思维。如图23所示,该算法没有依赖复杂的人体结构约束条件,而是基于2D姿态估计与姿态匹配的策略通过姿态检索得到最终的3D关节点坐标。该方法利用现有的3D姿态数据集,对人体的每一种3D姿态制作其在不同虚拟相机视角下的2D投影姿态集,相当于构建了一个目录为2D姿态的3D姿态字典。进行姿态估计时,首先利用基于深度学习的2D 人体姿态方法从图片中检测出一个准确的2D 姿态,然后查找姿态字典得到其对应的3D 姿态,并通过该视角下的相机参数将2D 坐标变换到3D 坐标。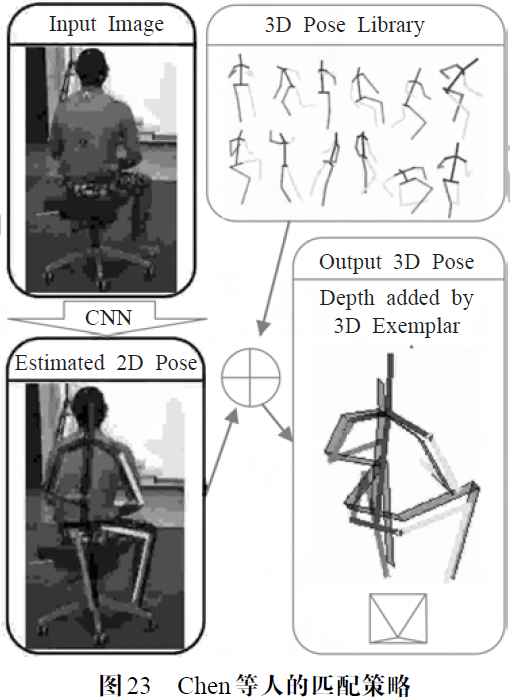

若有收获,就点个赞吧
0 人点赞
