原文链接 Something-Else: Compositional Action Recognition with Spatial-Temporal Interaction Networks
单词
Compositional: 组成demonstrations: 展示explicitly: 显示地constituent: 组成heretofore: 迄今为止discernible: 明显的aggregate: 聚集utilizes: 利用
本文特点
本文目的
进行动作识别。跟传统方法相比,比如C3D,LSTM,本文方法通过主体和客体之间的位置变化信息来完成动作的识别,不关注主体和客体的外观等信息。(文中指出,采用I3D-based等主流方法进行动作识别的一个缺点:无法对未知类别进行泛化;无法完全捕获动作和对象的组合)
综述
- RNN和3D ConvNet从全局进行特征提取,并不关注于单独的实体。这使得他们擅长处理和空间外形相关的任务,而不是和时间变化或者几何关系相关的任务;
- 研究表明,此类方面聚焦于外观,并没有聚焦于时序推理;
- 时间倒序和正序输入会产生几乎相同的结果;
时空图表征采用图神经网络,他对每帧图片中的对象proposals建立图节点,然后学习他们之间的关系。遗憾的是再目前为止,此类方法并不比3D ConvNet效果更优。可能原因:没有针对特定对象进行重点关注,对每帧图片中的大量对象,进行了分析。如果采用稀疏语义图结构对特定对象进行建模可能效果更好;
方法特点
作者思考
将每个动作分解成一个动词、一个主语和一个或多个宾语的组合;
- 综合动作的识别以及对象的分类;
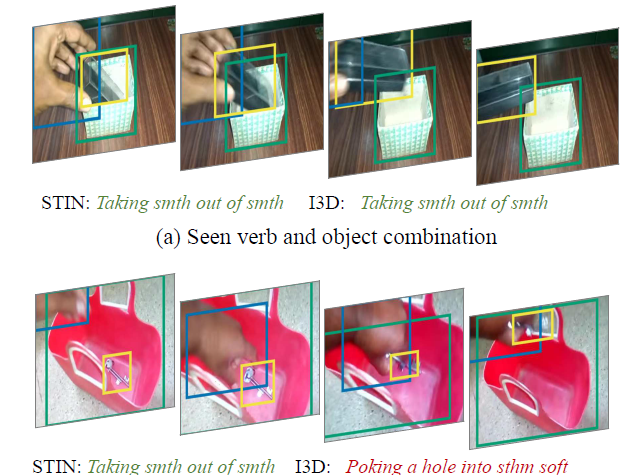
- 训练和测试包含相同的动作,但是动作的客体不同,甚至测试集包含了训练集中完全没有出现过得客体;
- 非常符合自己的想法:动作识别重点不在于关注全局信息,而是关注实体之间的交互;
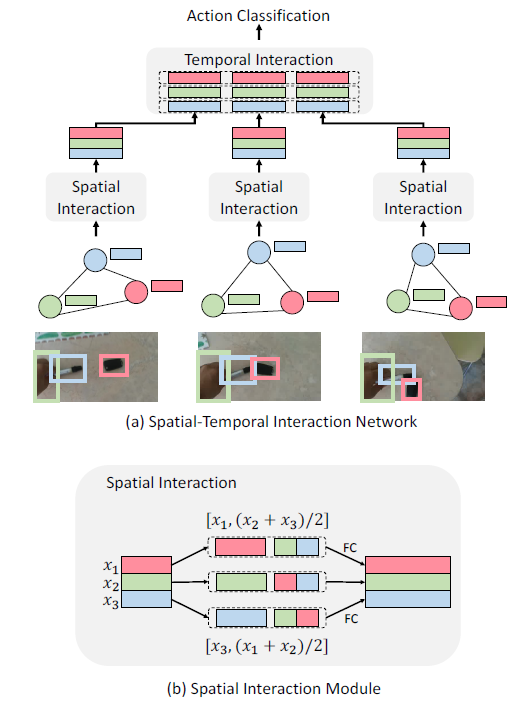
实现方式
- 模型训练采用示例动作中精确的对象框,模型学习主体和客体之间明确的关系;
- 采用最先进的目标检测器进行目标检测;
- 对检测对象进行多目标跟踪,并为属于同一实例的boxes形成多个tracklets;(tracklets,表示的是目标的轨迹)
- 网络名称:Spatial-Temporal Interaction Network (STIN);STIN对从检测以及跟踪结果中产生的候选的稀疏图进行处理;
- 模型的输入:每帧图片中主体和客体的坐标以及形状;
- 模型首先通过传播主客体之间的信息对主体和客体之间的空间交互进行推理,然后对沿着同一轨迹的boxes进行时域交互推理,最终综合人和对象的轨迹进行动作识别;—— 说白了就是既需要对单帧图片中的对象位置关系进行学习,又需要学习多帧之间的变化(大多数时序信息处理的方式);
模型另一个优点:对于有显著交互的动作采用上述方式,对于没有显著交互的动作采用基线时空场景表示(采用之前的较为优秀的时空模型);
数据特点
数据集采用Something-Something进行扩展,完成Something-Else任务;
- 训练和测试集的动作类别相同,但是对象类别有差异;
- 研究了两种设置下完成动作识别任务:标准设置(测试集和验证集具有相同的类别)、小样本设置(新的类别只有几个samples)
- 为了支持这两个任务,收集并将在每个视频帧的对象边框上发布注释;
-
Something-Something数据集
为了解决之前的网络聚焦于对象形状,而不聚焦于时间顺序的问题;
- 值得一提的是,复旦大学的Gait Set就是将步态序列当作集合进行处理;
- 该数据集是为了实现对象外形无关的动作识别;
目标识别的方法:
模型采用一个通用的检测器和跟踪器构建object-graph表征;
- 显示包含手并构成对象节点;(???)
对bounding boxes进行时空推理,从而确定主客体关系随时间的变化情况;
Object-centric Representation
对于给定的T帧图片,首先进行目标检测检测手以及其它对象;
- 然后进行多目标跟踪,从而获取不同帧图片中目标框的联系;
再这过程中,对于每个box提取了两种特征表示:bounding box的坐标、目标身份特征;
Bounding box coordinates
三类embeddings初始化采用独立的多元正态分布;
在后续将会将identity embedding和坐标特征连接之后作为模型的输入;
我觉得应该是以下意思:
- 目测是固定的三个embedding,从而可以做到与具体目标特征无关;
- 网络最主要的目的还是实现动作的识别;目标类别相关的检测通过检测器实现;
-
Spatial-temporal interaction reasoning
一个是视频T帧,每帧中有N个对象,则对象特征集合表示为:

其中 表示第i个对象在第j帧中的特征。
表示第i个对象在第j帧中的特征。 首先,针对每帧图片中的对象进行空间关系推理;
-
Spatial interaction module
针对每个对象特征
,首先,将其同其它N-1个对象特征的平均值进行组合;
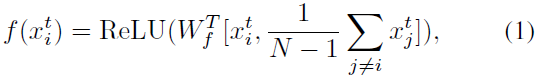
其中 表示在channel维度,进行特征连接;
表示在channel维度,进行特征连接; 表示可学习的参数,其通过全连接层实现;
表示可学习的参数,其通过全连接层实现;
Temporal interaction module
第i个目标的轨迹特征表示为:
- 首先连接多帧中的目标特征;
- 然后将其输入到MLP网络中提取d维特征;
对于时间关系特征,将他们进行组合之后进行动作识别: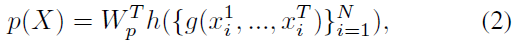
其中:h是组合不同轨迹信息的函数。
本文采用两种不同的方法进行轨迹的组合:
- h是一个平均值运算函数;
- h采用non-local block;
- 非局部块对每两个轨迹特征之间的成对关系进行编码,然后对其进行平均。本文采用了三个继卷积之后的非局部块;
-
Combining video appearance representation
这是为了解决部分动作不包含显式交换的问题。
对于外形特征,采用3D ConVNet进行提取,然后采用平均值池化将其转变为d维的特征;
然后将appearance特征和目标表征
 进行连接,最后输入到分类器;
进行连接,最后输入到分类器;
The Something-Else Task
主要目的是实现object的泛化,对于训练集中没有的object同样能够进行正确识别。
Compositional Action Recognition
不是随机将视频分为训练集和测试集,在训练集中出现的动名词组合不会在测试集中出现。
将出现超过100次的的目标类别作为一个子集;
- 将该子集分为不相交的两组
 ;
; - 与之对应的动作类别也被分为1,2两组;
- 随机将动作类别分到两组中;
- 保证属于同一super-class的动作类别被分在同一组;eg:Moving sth up和Moving sth down属于同一super-class;
- 组1和
 ,组2和
,组2和 一起产生训练集:
一起产生训练集:
-
Few-shot Compositional Action Recognition
Few-shot任务,比较直观的一种解释就是训练样本较少,但是测试样本较多的情况。
将Something-Something V2里面的数据集按动作类别分为base和novel两类,其中base中包括88类,novel里面包括86类;
- 将base中的10%拿出来作为验证集,其余作为训练集;
- 然后从novel集中对每个动作类选取k个样本,作为训练集的数据,novel集中的其它数据作为验证集;
- 保证novel选做训练集的样本中的object类,在测试集中不出现;
 是最终的分类器以及cross-entropy loss;
是最终的分类器以及cross-entropy loss;

值得注意的是,本文的模型在分析过程中引入了appearance特征,但是本文需要将apperance特征对动作分类结果的影响弱化。
实验细节
检测器
- 采用以FPN和ResNet-101为骨干网络的Fast R-CNN;
- 其主演检两类目标:手已经和手互动的目标;
-
跟踪器
采用Kalman滤波器以及Kuhn-Munkres(KM)算法进行目标的跟踪;
MLP
测试
在测试过程中,本文将本文的模型和其它模型进行综合,显示有很大的改善。但是模型结合方式未知?
总结
其实本篇文章灵感产生自,我们在动作识别过程中重点关注主客体的空间位置变化关系,利用空间位置变化来进行动作识别。后续再考虑引入appearance特征等。
所以本文最主要的是动作特征的产生: 最主要的是空间位置特征;
- 其次是时序信息,即目标的位置变化特征;
- 最后才是appearance特征以及identity embedding特征(主客体表征);

若有收获,就点个赞吧
0 人点赞
