参考论文:Going Deeper with Convolutions 作者信息:Christian Szegedy, Wei Liu, Yangqing Jia, Andrew Rabinovich 博客参考:GoogLeNet系列解读
当前趋势及网络优势
- 提高了网络内部计算资源的利用率;
- 性能提高原因:不单是硬件的强大,数据集的扩大,模型的加深;最主要的原因:一系列新想法、算法以及结构;除此之外结合深度网络结构以及经典计算机视觉同样可以提升性能(比如R-CNN;R-CNN的两个子问题:1、目标的可能定位;2、定位处类别识别)
- GoogleNet的重要组成部分:Inception layers;
参考了Network in Network里面的模式(利用更少的参数,实现更好的效果),用了很多
 卷积;最主要的作用:用作降维模块,消除计算瓶颈—-能够使得网络更深;
卷积;最主要的作用:用作降维模块,消除计算瓶颈—-能够使得网络更深;利用更深或者更宽网络的缺点:
- 容易发生过拟合;
- 利用更多的计算资源(尤其是权重矩阵中存在很多接近于0的参数时,很多资源都被浪费了);
- 解决办法:从全连接转向稀疏连接,甚至对于卷积层也是(比如利用小的卷积核替代一个大的卷积核)
- 但是论文中貌似指出当前转向稀疏的条件不是很好(有些没懂),比如当前硬件更支持稠密矩阵的计算;
- 中间办法:将稀疏矩阵聚集成稠密矩阵,然后利用当前硬件;
一个概念—神经网络的bottleneck层:表示的是输入和输出维度差距较大,就像瓶颈一样的。
Inception结构
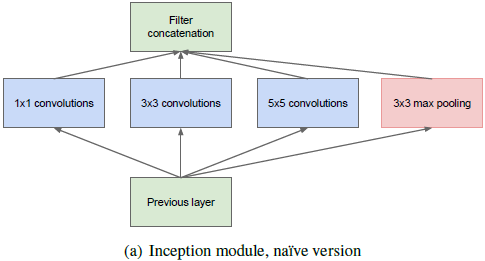
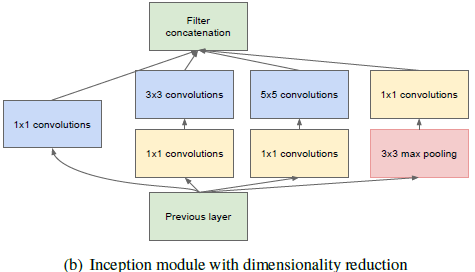
Inception的主要想法:弄清楚在一个卷积视觉网络中,一个最优的局部稀疏结构可以如何被逼近并且如何被可轻易获得的稠密组成成分所覆盖。(???)
假设平移不变性—论文中指出网络将由卷积块构成;首先找到最优的局部结构,然后再在空间上重复它,从而构成最终的网络。
对于(a)和(b)两种构造:
(a)中Inception由于过滤器数量很多,对于
卷积会造成很大的计算量,最终引起计算爆炸,所以引出了(b),利用
对于Inception Module的应用,仅仅在高层利用,底层保持传统结构时更有益。
Inception结构的优点
- 在每阶显著增加单元数量,但是不会带来爆炸的计算复杂度;(在大卷积之前进行了降维)
- 使得视觉信息从不同的尺度进行处理,这样下一阶段可以同时从不同尺度进行特征提取;
网络太深时,反向传递计算梯度将会成为一个问题!解决方式:
- 由于浅层网络的良好表现,所以对于网络中间层产生的特征也是非常有判别性的(吴师兄的那个文本检测就有用到这种方式),所以在中间层添加辅助的分类器,这样就能够利用浅层的特征,从而在提供正则化的同时解决梯度消失问题。训练的时候,辅助分类器的loss通过0.3的权重增加到total loss上,但是在实际推理(分类)的时候,辅助分类器将被丢弃。
- 本质上就是首先保证浅层效果的良好;

若有收获,就点个赞吧
0 人点赞
