论文原文:> Deep Residual Learning for Image Recognition 作者信息:何凯明 深层的网络很难训练,一般认为网络越深效果越好。一个较深的网络经过训练之后至少能够达到一个浅网络的性能。但是,事实却是,深网络的性能可能还不如一个较浅的网络。所以resnet就提出了一种short cut的方式,使得深层的网络通过short cut之后可以在特定条件下等价于一个浅的网络,使得其训练之后至少能够达到一个浅层网络的效果。
深层网络的几个问题
一、网络收敛:
阻碍网络越深时收敛的原因:梯度爆炸和梯度消失;
一些解决方法:参数归一化的初始化、中间加入归一化层;
二、准确率饱和
饱和之后就会迎来下降;此下降不是由于过拟合;
深层网络虽然在理论上要优于浅层网络,但是实验中发现其并不那么容易优化。
论文提出的解决方法:
- 引入残差映射:
 ;(残差:
;(残差: )
) - 残差学习相对简单。在最极限的情况下:残差块是一个恒等映射(Identity mapping)
 至少能够达到浅层网络的效果吧!
至少能够达到浅层网络的效果吧! - 虽然引入了残差映射,网络深度还是有极限;
残差特点
与残差网络很相似的:highway networks。
灵感来源:退化问题可能表明恒等映射难以用多层非线性层渐进逼近(不易学到),那么就利用一种方式使得恒等映射易于学到(short cut)。(利用恒等映射作为一种预处理)
(多层非线性层被认为可以逼近任意函数)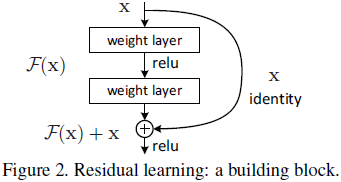
其实在神经网络内部运算就相当于是矩阵乘法等运算, 相当于
相当于 ,也就是对x乘上矩阵。
,也就是对x乘上矩阵。
网络结构
Plain Network的构建原则:
(1)输入,输出如果feature map大小相同,那么用的filter和之前的channel数相同;
(2)输出size减半,那么filter数double;
利用这种原则保证信息的不丢失。
Residual Network:
引入了short cut;
(1)short cut可以用于输入和输出feature map size相同的层之间;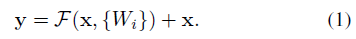
(2) 如果在输入输出feature map大小不同的地方用short cut,那么可以将short cut处的数据进行一个线性映射,映射成和残差输出feature map大小相同;(映射本质上就是矩阵运算)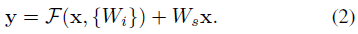
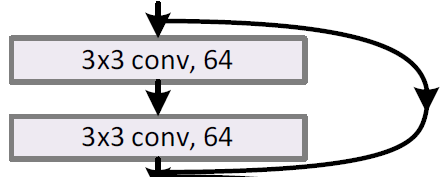
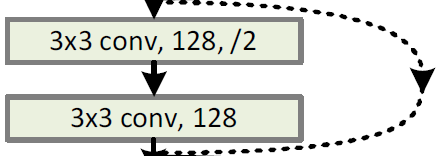
值得注意的是:
- channel保持一致,则需要保证feature map的大小相同(卷积操作会减小size,需要通过padding);
- 对于右边的图像,当channel增倍时,size同样会half;而对于输入和输出的size和channel不同的两种解决方法(针对short cut)(都是等价为一个线性映射
 )
)- short cut的输入通过补零进行维度增加,然后进行stride为2的类似sample的操作,是的size减半(相当于先stride为2进行采样,然后由于不同channel只给残差部分输出的前一半个维度加有效值,后面的维度不加);
- 直接利用stride为2的
 卷积,用于改变channel数,同时由于stride为2,szie也会减半,从而和残差输出对应;
卷积,用于改变channel数,同时由于stride为2,szie也会减半,从而和残差输出对应; - 上面两种操作都是有downsample操作的。
数据增强
- 数据增强的方式和VGG的很像,scale的大小是一个范围。然后进行图像的随机裁剪或者水平翻转。除此之外还用了color的增强。
- 并且在每个conv之后,激活函数之前,都加入BN层。(BN还可以确保前向传播过程中含有非零变量)
- 利用带mini-batch 256的SGD进行训练。
- lr从0.1开始,每次到达plateaus之后变为十分之一。
- weight decay为0.0001,momentum为0.9
残差网络
论文中有三种处理不同维度的输入输出之间short cut的方式:
A. 利用补0,将增加的其它维度补为0;
B. 补零和映射都用;
C. 只有映射;
最后效果最好的是C,但是C由于引入了映射操作,增加了model的size。通常还是选择A方式,减小模型和计算量。
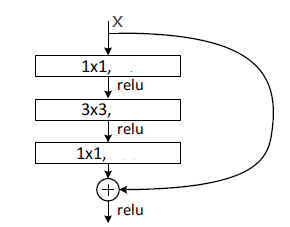
值得注意的是,VGG模型虽然深度不如ResNet,但是其模型的参数以及计算量都大于ResNet。(不要盲目认为层数越多,模型就越大,和设计有关)BottleNeck
降低运算量,使得 卷积时有相对小的channel。
卷积时有相对小的channel。
其结构如下图所示:
整体网络结构如下图:
实现时,可以将其看做4个大的层,每个大层里面又具有一定的规律性。

若有收获,就点个赞吧
0 人点赞
