论文原文地址 Large-scale Video Classification with Convolutional Neural Networks-2014CVPR
单词列表

本文的目标
从实用性的角度来看,本文构建了Sport-1M数据集,它包含了100万个YouTube视频,属于487个运动类别。
从模型的角度来说,想要探究:在CNN中怎么样的时序连接模式能够最好地利用视频中的局部运动信息?额外的运动信息是如何影响CNN的预测的,它能在多大程度上提高整体性能?
从计算的角度来说,视频CNN需要大量的计算。本文通过修改网络结构产生两个独立处理的流:contex流,从低分辨率进行学习;高分辨率的fovea流,它作用于帧的中间部分(此处可能翻译有问题……)。这种结构能够减少参数量,在保证精度的前提下,提速2-4倍。
最后,本文还做了迁移学习,发现通过再次利用在Sports-1M数据集上已经学习到的低层特征,比单独在UCF-101上面训练网络效果好很多。
相关工作
CNN时域信息融合
标准视频分类的方法:
- 首先,通过密集地或者是在一组稀疏的兴趣点上提取描述视频一个区域的局部视觉特征;
- 然后,将这些特征组合成固定大小的视频级别的描述。一个比较流行的方法是通过学习的k-means字典来量化所有的特征,并在视频的持续时间内,将视觉words累积到包含变化的时空位置和范围的直方图中;
- 最后,会在”bag of words”表示结果上训练一个分类器(例如,SVM),来区分感兴趣的视觉类别;
上面所说的方法就是传统的方法,其需要人为设计和任务目标有关的特征。(特征工程)
卷积神经网络则不同,它不需要显式地设计特征,只需要合理设计网络架构以及超参数即可。在数据预处理方面,图像数据可以通过剪切、拉伸等方式实现数据增强,那么视频呢?视频按照图像数据增强的方式,也能仿照对应的方法,但是其更为复杂。
本文将视频看做,一系列小片段组成的,每个小片段又由连续几帧图像组成。(貌似没有采样)然后通过扩展网络在时间维度上的连接性来学习时空特征。本文主要研究三种连接模式:Early Fusion, Late Fusion and Slow Fusion。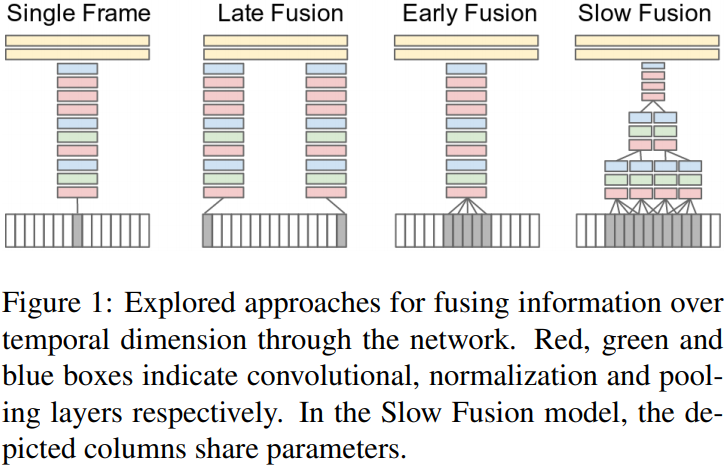
Single Frame
用单帧架构baseline来理解静态图像对于分类精确度的贡献。整个网络简记为:
其中: 表示的是一个包括
表示的是一个包括 个
个 大小步长为
大小步长为 的滤波器的卷积层;
的滤波器的卷积层; 表示包括
表示包括 个节点的全连接层;所有的池化层
个节点的全连接层;所有的池化层 都是
都是 的非overlapping的池化;
的非overlapping的池化; 表示normalization层(其参数:
表示normalization层(其参数: )。最后一层与具有稠密连接的softmax分类器连接。
)。最后一层与具有稠密连接的softmax分类器连接。
Early Fusion
早融合扩展结合了整个时间窗口上像素级别的信息。这是通过修改单帧模型的第一卷积层的滤波器来实现的,通过将它们扩展为 的像素点,其中
的像素点,其中 是时间范围(我们使用
是时间范围(我们使用 ,或者一秒的三分之一)。像素数据早期直接的连通性可以使得网络精确地检测局部动作方向和速度。
,或者一秒的三分之一)。像素数据早期直接的连通性可以使得网络精确地检测局部动作方向和速度。
第一个卷积层和C3D有点类似。
Late Fusion
Late Fusion模型由两个单独的单帧网络(如上描述)组成,两个单帧模型共享参数直到最后的卷积层 。两个单帧模型的输入为相距15帧的两帧,两个模型的输出利用两个全连接层进行融合。单独的单帧模型不能检测任何动作,但是通过第一个卷积层能够得到全局运动特征。
。两个单帧模型的输入为相距15帧的两帧,两个模型的输出利用两个全连接层进行融合。单独的单帧模型不能检测任何动作,但是通过第一个卷积层能够得到全局运动特征。
Slow Fusion
Slow Fusion是两种方法的中和,其贯穿整个网络缓慢地融合时间信息,使得高层可以获得逐步增多的关于时间和空间维度的全局信息。这是通过在时域上扩展卷积操作实现的。本文采用的模型中,第一个扩展卷积层,每个滤波器的时间范围 ,作用在输入的10帧片段上,通过步长为2的有效卷积操作,产生4个时域上的响应。第二第三层也重复迭代这个过程,其时间范围
,作用在输入的10帧片段上,通过步长为2的有效卷积操作,产生4个时域上的响应。第二第三层也重复迭代这个过程,其时间范围 ,步长为2。因此第三个卷积层可以获得全部10帧输入的信息。
,步长为2。因此第三个卷积层可以获得全部10帧输入的信息。
Slow Fusion和C3D基本差不多了。 但是对比这几种策略,貌似并没有按照相同的标准来!这样的网络性能对比是否可靠?
多分辨率CNN
多分辨率是为了加速CNN的训练。本文在保证网络大小的前提下,希望通过降低图片分辨率的方式实现网络的提速。当然,降低图像分辨率,也就意味着图像中的一些高频细节信息会丢失,然而高频细节被证明对提高准确率是至关重要的。
Fovea and context streams
为了在准确率和计算量之间进行权衡,本文采用了高分辨率和低分辨率两个通道流的网络结构进行处理。图像原大小为 ,contex流接收下采样的输入图像(
,contex流接收下采样的输入图像( ),fovea流接收原图像正中间的大小同样为的切割部分。这样,整个网络的输入图像大小被减半。
),fovea流接收原图像正中间的大小同样为的切割部分。这样,整个网络的输入图像大小被减半。
上述处理基于一个假设:在一张图片中,我们关注的东西往往在图像正中央。
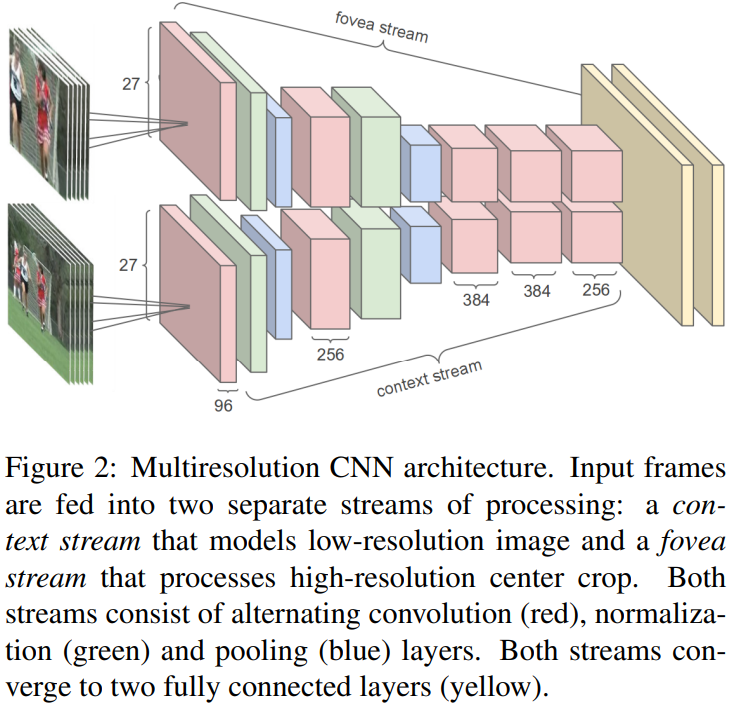
所有的输入变为原来的一半 ,为了保持最后在
,为了保持最后在 结束,最后一个池化层被移除。两个通道的特征将被连接,然后再输入到全连接层。
结束,最后一个池化层被移除。两个通道的特征将被连接,然后再输入到全连接层。
数据增强
数据增强和图像的数据增强很原理相同,但是考虑到视频是一个整体,每次做改变时需要将所有帧都一起处理。
数据增强的方式:裁剪中心区域,将其resize到 ,然后随机采样
,然后随机采样 的大小,并有50%的概率使图像做水平翻转。处理完之后,将所有原始像素值减去117(117为所有图像的像素大概均值)
的大小,并有50%的概率使图像做水平翻转。处理完之后,将所有原始像素值减去117(117为所有图像的像素大概均值)
这个数据集的均值,倒是挺难算的,不知道有没有简单方法。随机抽取
结果
数据集
进一步地,本文输入网络的视频帧是从每个视频中随机抽取的100个半秒的片段。
本文的视频平均长度为5-36分钟。输入网络是截取视频小段的方式,但是不同小段之间的结果是如何综合的呢?
视频级别的预测
为了对整个视频进行预测,本文随机取样20个片段,并且每个片段单独地放入网络中。每个片段都在网络上传播4次(不同的裁剪和翻转),最终的结果采用所有预测的平均值从而使得网络类别估计对每个类的概率产生一个相对更稳健的估计。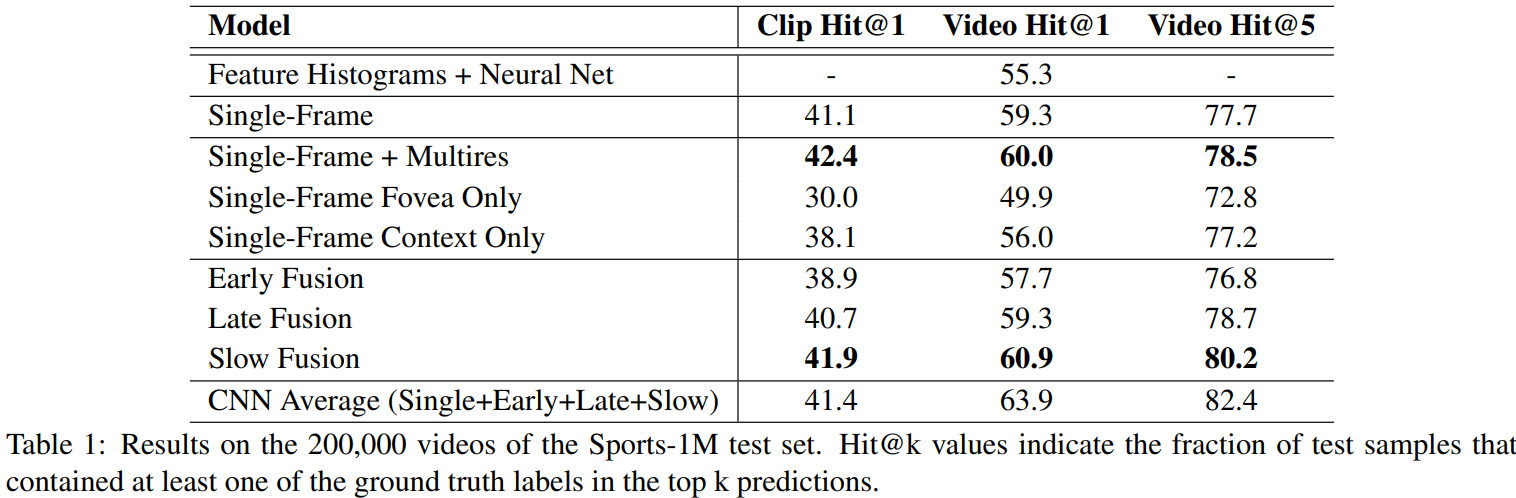
上表显示的结果是:Slow Fusion的效果最好。
迁移学习
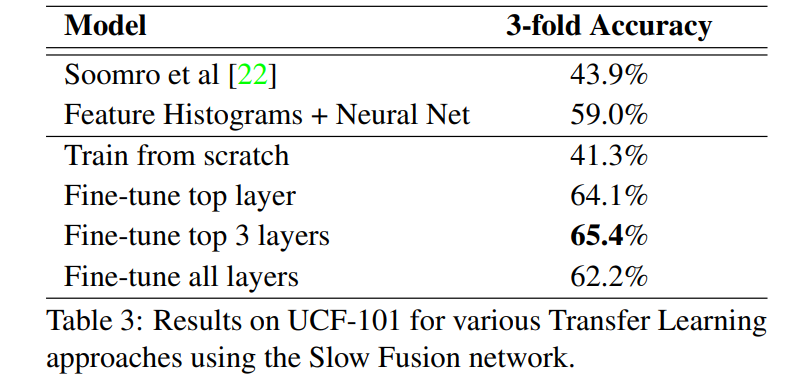
本文测试了多种迁移的方法,如上表所示。
Fine-tune top layerL:将CNN作为一个固定的特征提取器,在有4096维度的最后一层上,使用dropout正则化,训练分类器。本文发现只有10%的几率保证每个神经元都是有效时的效果最佳;
Fine-tune top 3 layers:不仅仅是再训练最后一层的分类器,所有的全连接层都被重新训练。在所有训练过的层之前使用dropout,只有10%的几率保证每个神经元都是有效的;
Fine-tune all layers:整个模型参数都被进一步训练;
Train from scratch:完全从零开始训练模型;
结果发现,中庸之道取得的效果最好,即Fine-tune top 3 layers;
总结
本文的结果表明,性能对于网络架构在时间上连通性的细节并不是特别的敏感的时候,Slow Fusion模型比Early Fusion、Late Fusion性能更好。特别的,本文发现,单帧模型总是有很强壮的性能,这表明,局部动作因素可能并不是很重要,即使是对于诸如运动相关的动态数据集。另一个可选的理论是,我们可能需要对摄像机的运动做小心的处理(例如,从一个跟踪点的局部坐标系中提取特征),但是这要求对CNN架构有明显的变化,这个在本文中尚未涉及。
- 看本文的数据集,其实很多分类在静态的图上就能够完成分类,无需提取时序相关的信息。(本文的单帧模型正是暗示了这个问题!这还提供了一个想法:是否在以后的研究中,可以结合单帧图像,例如关键帧提取等,来完成动作分类?然后类比于全卷积网络,是否可以设计对时域长度同样不敏感的模型?
从而可以保证模型模型在时域上的灵活度,这样最极端的情况就是单帧图片模型)
- 对于人来说也是如此,很多动作,尤其是运动,看单张图,结合上下文信息就能够判断处动作的类别。
- 另外值得一提的是,本文的结论(上面深色标注部分)是否正确?

若有收获,就点个赞吧
0 人点赞
