参考论文:Very Deep Convolutional Networks for Large-Scale Image Recognition 作者信息:Karen Simonyan, Andrew Zisserman
要点
 :接收窗;
:接收窗; :感受野;
:感受野;
研究了网络深度和识别精度之间的关系;
利用 的卷积核,使得网络深度达到了16-19层;(小卷积核)GoogleNet也是如此
的卷积核,使得网络深度达到了16-19层;(小卷积核)GoogleNet也是如此
目的是想让网络做得够深
特点
- 数据预处理:每张RGB图都减去了训练集上的均值;
 卷积核的作用:可实现channel的变换、跨通道信息交互、增加非线性性(后接Relu等—网络可以更深)、可以充当全连接;
卷积核的作用:可实现channel的变换、跨通道信息交互、增加非线性性(后接Relu等—网络可以更深)、可以充当全连接;- 卷积核采用
 小卷积核,和之前的有区别;
小卷积核,和之前的有区别; - 采用maxpooling,pooling核为
 ,步长为2;(未重叠)
,步长为2;(未重叠) - 此文中指出LRN并不能提升准确率,只会徒增内存消耗和计算时间;
- 每次为了保证图像的精度不变,每次卷积padding为1;
- 为了保证每次maxpooling之后信息不丢失,每次pooling之后,channel数翻倍;(网络设计的一种范式了,但是
 卷积可以设计瓶颈)
卷积可以设计瓶颈)
网络结构
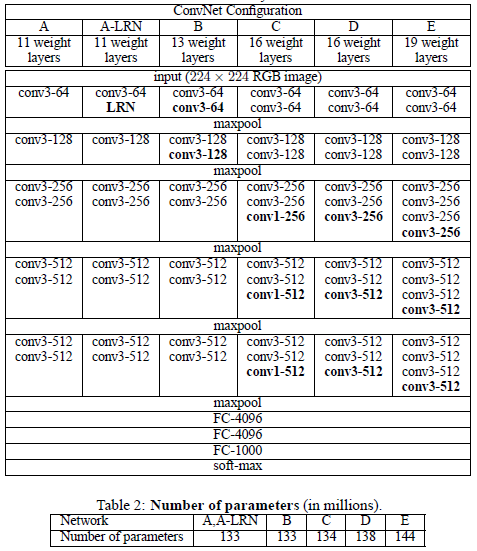
小卷积核的特点
- 大卷积核可以由多个小卷积核串联实现;
- 小卷积核之间可以有更多的Relu等非线性层;
减少了参数量:比如3个
串联相当于一个 ,假设输入和输出channel都是
,假设输入和输出channel都是 ,那么需要的参数量:
,那么需要的参数量: ;对于需要参数量:
;对于需要参数量: ;(论文中指出相当于对
;(论文中指出相当于对 卷积进行了正则化操作—使得模型变得稀疏,使得模型压缩)
卷积的特点
卷积进行了正则化操作—使得模型变得稀疏,使得模型压缩)
卷积的特点实现channel数的改变;
- 在channel数不变的情况下,可以引入Relu增加非线性性,使得网络更深;
- 跨通道信息交互;
- 充当全连接层;(貌似只能是最后每个channel只有一个元素后,可以作为普通的fc —> 这就是全卷积网络的实现方式)
学习率的改变一般是通过validation结果进行调整的。(比如此文中:当validation里面的正确率不再改变时,则lr除以10,此时学习率是一个超参数)
训练
- 采用了mini-batch gradient descent(MBGD,之前用到的SGD是随机梯度下降):权值更新的loss是一整个batch的总loss,也就是说一个batch才更新一次参数。mini-batch是相对于BGD来说的,BGD(batch gradient descent,优点是全局最优)是将整个训练集进行计算之后再算梯度,而mini-batch就是在batch基础上算梯度。
- batch size为256,momentum为0.9,weight decay
 ;
; - 收敛速度加快:小conv、深度更深、特定层的预初始化;
特定层的预处理方式:先训练浅层模型,之后利用浅层模型的参数赋值给深层网络;(浅层没有的就随机正态分布赋值)
总结
LRN不能提升效果;
- 多余的非线性能够提升效果(利用卷积实现),但是相对于普通的卷积,如果是相同深度,1*1卷积的效果还是要差一些;
- 小卷积核(小池化核)的效果相对更好;(保证感受野一样的条件下:两个替代一个
 )
) - 引入scale jittering(用在增强数据时),比固定图像大小效果更好;(multi-scale image)
- 就是图像rescale时,不是rescale到固定值,而是一个范围,这样增强数据效果更好(增加了多样性);
- 训练集和测试集的差异不能太大(这是在数据增强时需要注意的),太大显然会降低效果
 这其实就是说很多论文中提到的,训练集和测试集的分布问题;
这其实就是说很多论文中提到的,训练集和测试集的分布问题; - ConvNet Fusion可以提升效果(综合多个模型的结果)
- 论文中提到三种evalution:single evalution、multi-scale evalution、multi-crop evalution、dense evalution;
- single evalution:rescale图像最小变为固定值;(对应于train时)
- multi-scale evalution:rescale图像最小值为一个范围之间的随机采样值;(对应于train时)
- multi-crop evalution:对于一张一键被rescale的图片,从中进行多样本随机裁剪,最后将这些所有图片输入网络进行预测,最后对所有的预测取平均;
- dense evalution:利用卷积取代全连接层,最后通常为卷积层,产生的channel和类别对应,最后不同大小的图片输入产生不同的分辨率,这时最后的每个channel可以看作一张score map(可以看作是multi-crop evalution中不同剪切输入产生的score组成的一个map),最后利用sum – pool将其映射为最终得分(取综合平均结果)。
(两者边界处理方式不同,效果往往不同)
本文最为重要的包括:
- 小卷积(池化)核的使用;
- 全卷积网络实现对输入数据size的自适应;
- 数据增强的scale jittering(也即是多尺度训练);

若有收获,就点个赞吧
0 人点赞
