原文链接:https://arxiv.org/pdf/1409.7963.pdf 作者信息:Arjun Jain, Jonathan Tompson, Yann LeCun and Christoph Bregler
与前几篇文章不同,这篇文章借助了人体的运动信息来辅助对人体关节点的估计。
理论支撑:Alternatively, psychophysical experiments [3] have shown that motion is a powerful visual cue that alone can be used to extract high-level information, including articulated pose.
为了实现本文的目标,作者构建了FLIC-motion dataset
Motion features
这里介绍四种 motion features:基于RGB图像的以及基于光流的各两种
- RGB图像对:

- RGB图像和RGB差分图像:

- 光流向量:

- 光流强度:

RGB图像对,最简单,但是其中的运动信息不够明显。对运动场近似得最好的是光流的方式,但是它们运算量又比较大(看具体的侧重点)。表达式中的 和是否包含相机抖动,作者通过实验进行了验证。
和是否包含相机抖动,作者通过实验进行了验证。
去除相机运动:We use a simple 2D projective motion model between
and
, and warp

光流结果的可视化:将方向和大小信息编码到颜色中,从而产生一张彩色图像。但是上图中的标准是啥,不太清楚?
网络结构
卷积网络
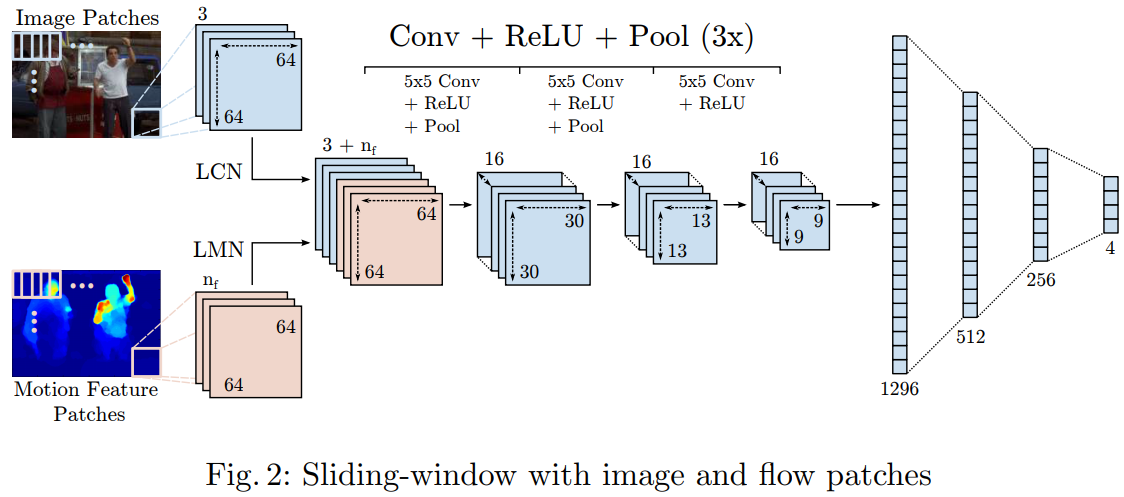
采用滑动窗口的策略,滑动窗口的Step为4 pixels,每滑动一次进行一次特征提取,然后产生一系列和关节点相关的heatmap(这种方式已经被抛弃了,因为有特征冗余,计算量大)。所以作者采用了下面的方式,对整张图进行卷积运算。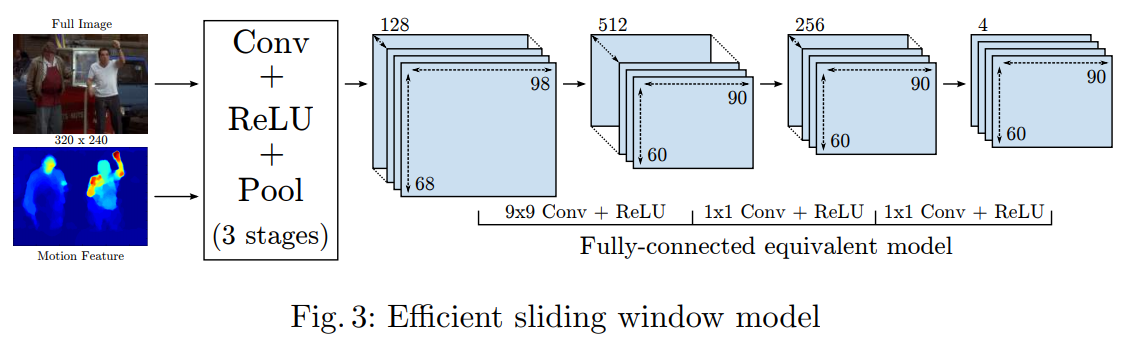
同样一如既往的多分辨率融合(实际采用3层金字塔):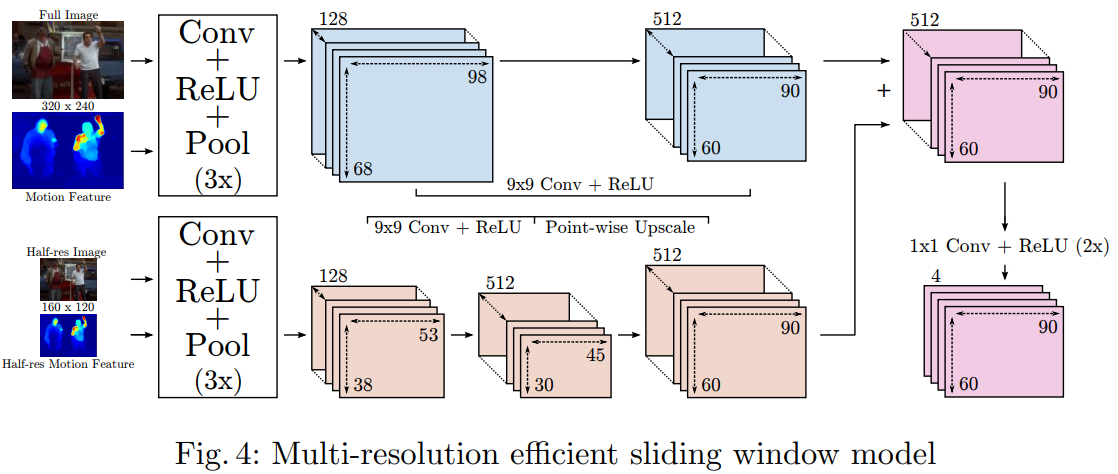
Simple Spatial Model
测试数据集可能存在多人的情况,为了解决这个问题采用了一个Simple但是efficient的Spatial Model。
The core of our Spatial-Model is an empirically calculated joint-mask, shown in Fig 5(b).
其中 joint-mask 在已知人体中心位置的前提下,描述了关节点可能的位置。事实上就是一个数据统计的过程,作者统计的数据来自于训练集(当然,这种方式是极有可能出错的;统计的只是一个经验数据,并且在人拥挤的情况下基本上是无效的)。统计的信息: ,其中A表示任意一个关节点(每个关节点需要单独计算处理),
,其中A表示任意一个关节点(每个关节点需要单独计算处理), 表示人体中心位置(图中红叉),最终统计的结果将得到一个直方图,表示了每个节点偏离中心点特定距离的概率(原文中是先转为Boolean mask,然后利用高斯低通滤波进行融合)。
表示人体中心位置(图中红叉),最终统计的结果将得到一个直方图,表示了每个节点偏离中心点特定距离的概率(原文中是先转为Boolean mask,然后利用高斯低通滤波进行融合)。
结果

为什么能够取得更好的效果呢?此处做分析如下:单纯利用RGB图像的话,图像中可能存在一些类似的纹理信息,这些纹理使得网络产生错误的预测结果。在motion image中,是去除掉了这种纹理信息的,取而代之的是运动信息。所以结合两者的话,就可以去除掉一些因为相似纹理而产生的误预测(如上图所示)。
启示:每一种类型的数据有它自身的特点,对于利用单一类型数据进行训练的模型,它是极有可能学到该类数据中一些与我们要求的任务无关的特征的,这些特征及可能导致最终预测结果出错。融合多种类型的特征进行预测,是可以对这类错误进行一定的规避的。
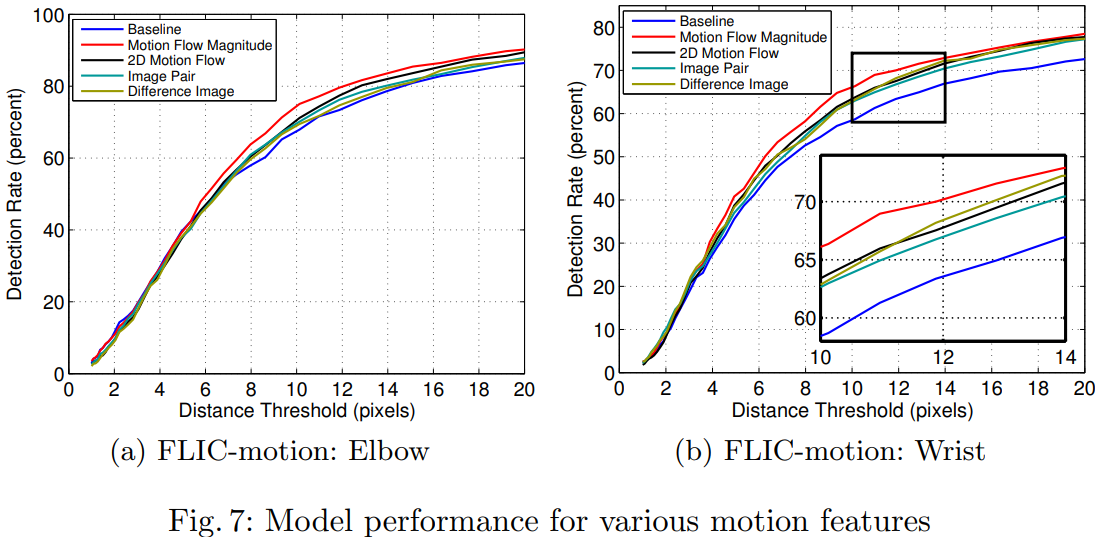
有意思的是,Motion Flow按理来说相对于Motion Flow Magnitude包括更丰富的信息(运动方向信息),但是Motion Flow Magnitude的效果确实最好的。可能原因:丰富的信息引入了更多的复杂性,复杂度越高模型学习难度更大。作者解释:We hypothesize that when using 2D flow vectors the network must learn invariance to the direction of joint movement;On the other hand, when the L2 magnitude of the flow vector is used, the network sees the high velocity motion cue but cannot over-train to the direction of the movement.
对于帧差的选择,以及是否进行摄像机运动补偿: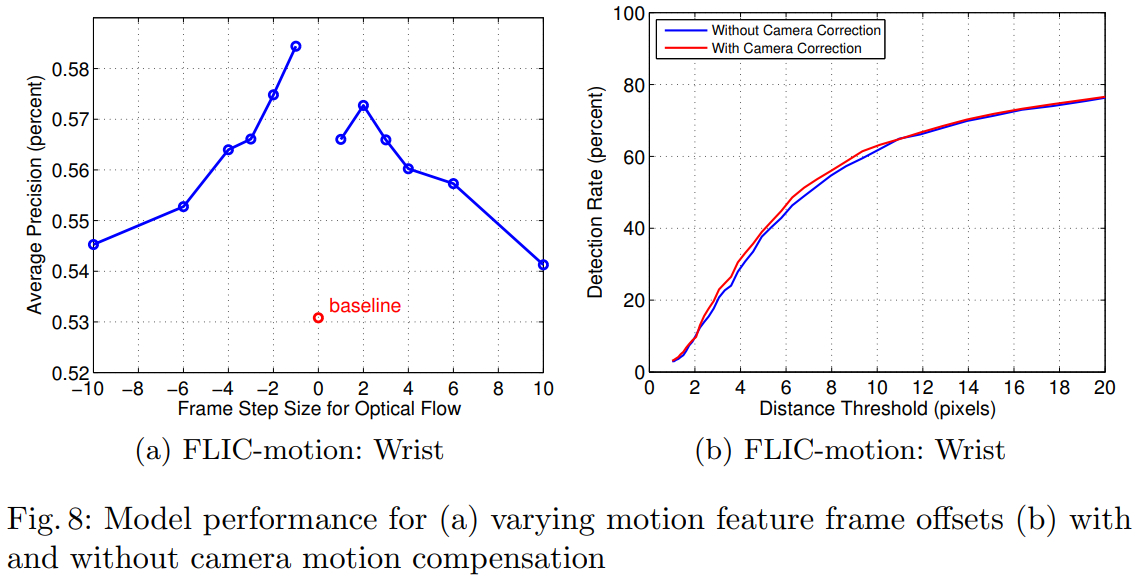
帧差不能太下:太小的话,提供的运动信息不明显;不能太大:太大将会增加轨迹的非线性(或者说增大离散性) 相机运动补偿帮助不大:可能是网络内容自动剔除了这种背景运动信息

若有收获,就点个赞吧
0 人点赞
