Author: Shaoqing Ren, Kaiming He 原文链接:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 代码实现:https://github.com/longcw/faster_rcnn_pytorch/tree/master/faster_rcnn 博客学习:https://zhuanlan.zhihu.com/p/30720870
前面的 Fast R-CNN 存在一个非常明显的不足,那就是 region proposals 的产生需要采用传统的算法 selective search。本文作者提出了采用 CNN 进行 region proposals 提取的方式:RPN(Region Proposals Network)。
RPN(Region Proposals Net)
Faster R-CNN 网络的架构如下图所示:输入图像首先利用卷积层进行特征的提取;提取的特征通过一个全卷积网络进行 region proposals 的预测;预测的 region proposals 将作用于前面的 feature map 进行后续的分类(前面 RPN 貌似已经进行了初步的类别预测)以及坐标精调值的预测。RPN 的最主要的目标是:进行 Region Proposals 的预测的同时,需要充分共享计算的特征。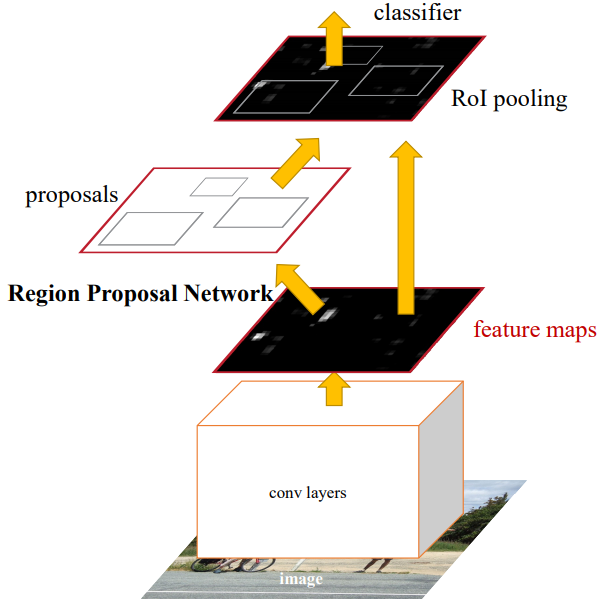
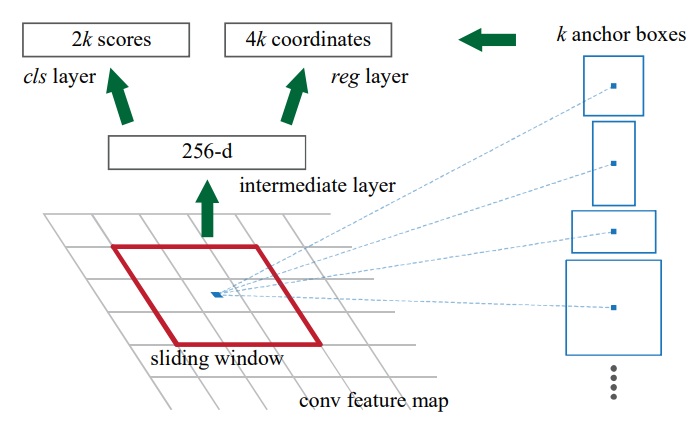
如何产生 Region Proposals?
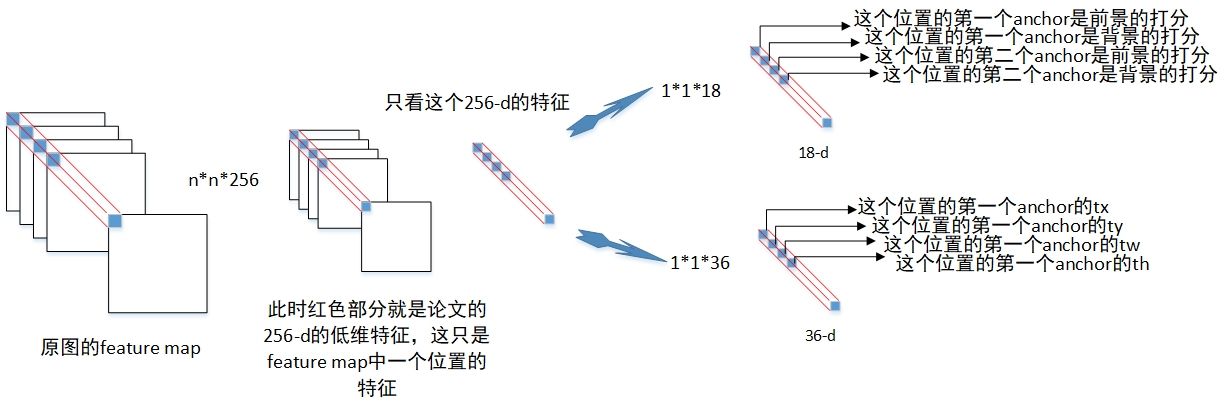
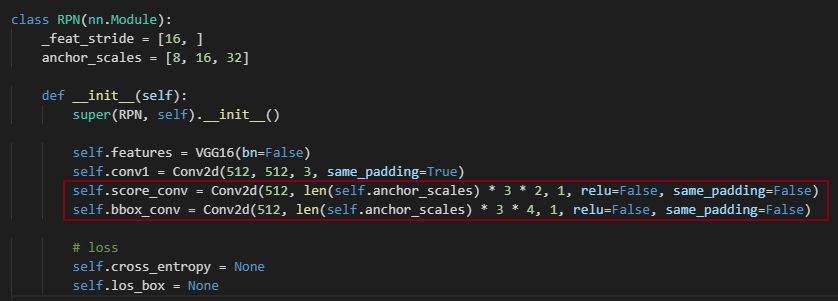
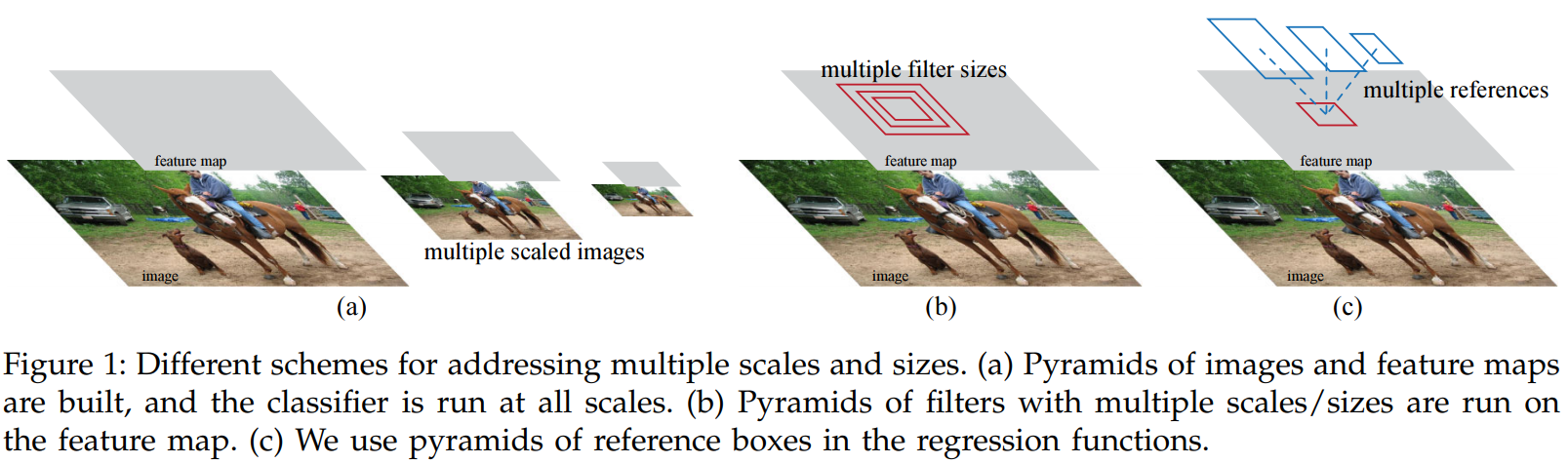
事实上这和 YOLO 是非常类似的,尤其是之后引入了 Anchor Boxes 的 YOLO 算法。网络就是一个函数,它的强大之处在于理论上可以拟合任意的函数。我们可以借助它强大的拟合能力去实现我们的目标。比如我们想要通过图片来预测图片中人的位置,那么就可以设计网络,使得网络能够产生关于人的检测框的输出。如何保证预测输出的准确性?1、损失函数通过对比 GT 和网络输出来评判输出的准确性;2、函数参数优化,找到最小化损失的参数(如果是凸问题,那么通过梯度下降一定能够得到最优的参数值);上面实现的代码,事实上就是将 feature maps 映射到检测框和类别分类的输出。
作者论文中的描述:采用在前面特征提取的最后一层卷积输出特征上进行小网络的滑动操作。小网络输入  (
( ,即
,即  卷积) 大小的空间特征窗(网络说空间窗时都是默认将 channel 考虑入其中的),然后产生低维的特征(见上面的代码以及实现图解,事实上就是进行了一次卷积操作)。得到的低维特征通过两个 fc 层(代码中采用的
卷积) 大小的空间特征窗(网络说空间窗时都是默认将 channel 考虑入其中的),然后产生低维的特征(见上面的代码以及实现图解,事实上就是进行了一次卷积操作)。得到的低维特征通过两个 fc 层(代码中采用的  卷积的方式)将维度映射到与类别预测和检测框预测对应的维度上(分别为
卷积的方式)将维度映射到与类别预测和检测框预测对应的维度上(分别为  以及
以及  )
)
Note that because the mini-network operates in a sliding-window fashion, the fully-connected layers are shared across all spatial locations. This architecture is naturally implemented with an n×n convolutional layer followed by two sibling 1 × 1 convolutional layers (for reg and cls, respectively).
Anchors
每一个检测窗的中心预测 9 个 anchors,它们要么有不同的大小,要么有不同的长宽比。For a convolutional feature map of a size  (typically
(typically  2,400), there are
2,400), there are  anchors in total.
anchors in total.
- 貌似前面的 RPN 以及预测了目标的位置以及类别,后面的坐标回归和类别预测又是起到什么作用呢?
- 答:对于类别分类,分别是每个 anchor 中内容是前景的概率和是背景的概率;对于检测框的预测,类似于 R-CNN 中的
,即关于中心点的平移量以及长宽的伸缩量(当然这是对于 region proposals 做的预测,后面的回归网络是对 region proposals 的进一步精修)。
- 这里同一个滑动窗里面的不同 anchor 对于的类别预测可以是不同的(与之前的最初的 YOLO 同一个方格中 anchors 共享类别预测概率不同,当然由于 YOLO 是一阶段的,最后可以直接利用该输出获取检测结果。不过后面 YOLO 算法也引入了 anchors)。这种做法对于这里需要预测的问题是更为合理的,因为不同大小的 anchor 和 GT 的 IOU 不同,从而是否为 positive 或者 negetive 可能不同。
Loss Function
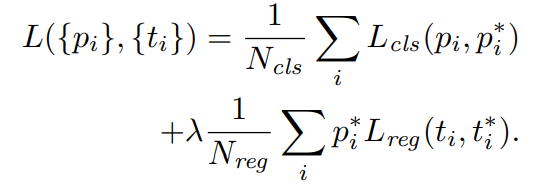
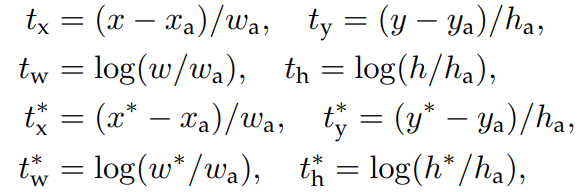
其中:对于目标位置的预测,可以用四元组表示  ,分别表示检测框的中心坐标
,分别表示检测框的中心坐标  以及宽高
以及宽高  。上述公式中
。上述公式中  分别表示:预测的检测框中心横坐标、anchor 对应的中心横坐标以及 GT 的检测框中心。
分别表示:预测的检测框中心横坐标、anchor 对应的中心横坐标以及 GT 的检测框中心。 ,在回归项,对于不是 object 的 anchor 不计算 Loss。
,在回归项,对于不是 object 的 anchor 不计算 Loss。 论文中为 mini-batch size,
论文中为 mini-batch size, 是 anchor locations 的数量,大概为 2400。
是 anchor locations 的数量,大概为 2400。
Training RPNs
RPN 中的 anchors 是相对于原图像而言的。RPN 关于 feature map 的每一个滑动窗口中心进行 k 个bounding boxes 的预测。这些中心可以映射到原图中的一系列网格(类似于 YOLO 的解释),所以 anchors 是相当于以这些网格为参考进行目标检测的(对于 GT 的构造有指导性意义)。
如何产生 RPN 的 GT 呢?大概步骤如下:
- feature map 进行滑动卷积之后,产生一个更小的 feature map,小 feature map 的每个点预测 9 个 anchor boxes;
- 每个点与通过感受野可以对应到原图,所以也即是说,原图的一个该区域以区域中心为基准预测 9 个 anchor boxes(anchor boxes 可能大于该点对应的感受野);
- 一个区域可能存在多个目标;通过该区域预测的 anchors 分别于目标标注的 boxes 进行 IOU 计算,按照事先定义的 IOU 阈值,判断 anchor 是否为 positive;
为了平衡正负样本,需要随机进行筛选操作;(为何需要删选呢?1、是为了样本平衡。对于 Fast R-CNN 的输入需要进行 proposals 平衡是很好理解的。但是这里感觉不是很好理解?RPN 对应到原图,肯定大部分是 negetive 的样本,如果直接进行训练,那么模型就会倾向于输出对所有 anchor 预测为 negetive,所以需要平衡一下。比如可以在计算损失函数的时候进行调控即可;2、一张图中太多的目标不利于网络的训练?给模型降低约束)
- 所以 label 不仅仅是 0, 1,还可能是 -1(dont care, hard to predict or for balancing)
- 训练 RPN 的启示:A. 样本平衡问题;B. 模型约束问题(是直接强制得到 gt 呢,还是降低要求,每次只考虑预测结果的一部分)
对于 positive 的样本,通过计算它和对应的标注 boxes 之间的差异得到 RPN 中需要预测的
- 这种从 feature map 对应到原图并没有显式表达出来;anchor 的标签(positive 与否)是需要对应到原图中进行判断的。
- 可以从最简单的情况来理解这个问题,即单张给定大小图中的单个目标的定位检测。
- feature map 编码里原图中的信息,当然可以包括图中目标的大小以及位置信息(当目标在图中的位置不同或者大小不同,那么产生的 feature map 也会存在差异),我们要做的就是利用编码的信息来提取其中的目标的大小以及位置信息。
- 为了简化问题,可以将目标用一个更简单的矩形来表示,我们只需要提取对目标大致的矩形描述即可;
- 如何让网络来实现我们的这个目标呢?(个人理解,可能大谬 -_-!)
- 下面内容,没有考虑检测框大于感受野的情况,事实上在检测是需要包括这种情况;
- 我们可以采用直接回归的方式,正如 YOLOV1所采取的方法,那是一种完全回归的方法(这种方法貌似可以这样来描述:有人给你了很多图片以及标签,当然图片是不同的,这包括背景以及其中的物体;那些标签是数据提供者根据严格的定义以及计算得到的,比如它在标准时:当物体整体面积超过 1/2 的部分在图像中时,它应该是一个正样本;显然你是很难确定其数据提供者对正负样本的准确定义的;但是通过分析图片中物体所在的位置以及对应的标签你可以轻易发现:物体如果有很大一部分出现在图像中,那么这样的图片应该是正样本;并且你还可以轻易得到,给出的四元组向量与物体在图中的位置相关);
- 当然,也可以采用本文的方式。首先定义一系列以图像为中心的 anchors,图像中的物体(标注的检测框)与 anchor 的 IOU 大于一个阈值时,就认为该 anchor 成功检测到了物体,我们认为该 anchor 是一个正样本(相对于 Faster R-CNN 后面的网络而言,anchor 检测的结果是输入的样本;但是相对于 RPN 而言,anchors 检测的是结果),并且我们根据二者差异来计算需要回归的位置偏移量和尺度伸缩比例,由此我们得到了该图像在 RPN 层的预期输出。我们给网络的是啥?=> 一张原始图片以及 RPN 层预期的输出,像 anchors 之类的信息网络是很难知道的,那么网络是如何学习的呢?网络是很难学得精确的值的(精确值往往是针对我们而言的;由于positive 的 anchor 本身就与目标有很大的 IOU,我们只需要对其进行精修,所以通过定义 anchor 来提高精确度的思想看起来是比较的合理的,它相当于对物体先进行一个粗定位,然后再进行精修),但是想要去估计一个大概值还是绰绰有余的。同样可以用一个例子来进行表述:这一次,你再一次被分配一个任务。给你一些图片,然后一些长度分别为
 和
和  的标签。你能发现数据提供者定义的 anchor boxes 吗?显然这是非常困难的。但是由于 anchor boxes 的大小和形状不同,那么数据提供者计算的 IOU 显然是和物体在图中的位置和大小相关的。所以如果你从这两个角度去思考的话,那么是可以得到一个对应的近似关系的。比如物体在图像中的偏右方,那么具有大概率是那些水平方向较长的 anchor boxes (和 长度的向量指定下标对应,比如说
的标签。你能发现数据提供者定义的 anchor boxes 吗?显然这是非常困难的。但是由于 anchor boxes 的大小和形状不同,那么数据提供者计算的 IOU 显然是和物体在图中的位置和大小相关的。所以如果你从这两个角度去思考的话,那么是可以得到一个对应的近似关系的。比如物体在图像中的偏右方,那么具有大概率是那些水平方向较长的 anchor boxes (和 长度的向量指定下标对应,比如说  )对应的 label 为 positive,同理对于其他位置;对物体的尺寸分析同样如此。这样我们就可以通过分析大概得到图像和 长的标签的对应关系(对物体进行了初次定位),后面通过物体的位置以及图像中心大概估计一个用于更精确确定目标位置的 长的向量。
)对应的 label 为 positive,同理对于其他位置;对物体的尺寸分析同样如此。这样我们就可以通过分析大概得到图像和 长的标签的对应关系(对物体进行了初次定位),后面通过物体的位置以及图像中心大概估计一个用于更精确确定目标位置的 长的向量。
有了 GT 之后,根据定义的损失函数训练网络即可!RPN 预测可能产生很多重叠的 region proposals:根据每个区域的 cls socres 进行 NMS.
检测部分
检测部分基本上和 Fast R-CNN 一样了,通过 region proposals 预测的结果,从中选择正负样本进行训练。RPN 中关于类别只进行了前景和背景的判断,所以 Faster R-CNN 中的后续部分,需要对分类进行预测。在 RPN 中事实上已经根据 GT 的值对物体的位置进行了预测,Faster R-CNN 中的后续部分回归部分,可以看做是对该结果进一步进行精化。(注意:region proposals 中产生的 positive 结果可能在后续并不会被分为 positive;代码中在 RPN 预测 proposals 之后,根据 IOU 值又进行了一次正负样本分类,以及正负样本的平均,然后才进行类别的细分)
Both RPN and Fast R-CNN, trained independently, will modify their convolutional layers in different ways. We therefore need to develop a technique that allows for sharing convolutional layers between the two networks, rather than learning two separate networks. We discuss three ways for training networks with features shared:
- Alternating training:交替训练 RPN 和 Fast R-CNN;(交替训练的话,可以对 RPN 产生的 region proposals 进行进一步的分类;那么 RPN 就仅仅充当了 region proposals 的操作)
- Approximate joint training:直接把整个网络当成一个整体进行训练;训练时 RPN Loss 和 Fast R-CNN Loss 都进行反向传播;会忽略 RPN 产生 proposals 处的导数(?)。(Fast R-CNN 的 GT 貌似是依赖于 RPN 的 GT 的;那就是要在前向传播到 RPN 之后,及时计算 Fast R-CNN 的 GT?)
- Non-approximate joint training(?)

若有收获,就点个赞吧
0 人点赞
