论文原文:Actional-Structural Graph Convolutional Networks for Skeleton-based Action Recognition 代码链接:https://github.com/limaosen0/AS-GCN 论文作者:Li, Maosen
Abstract
Previous studies are mostly based on fixed skeleton graphs, only capturing local physical dependencies among joints, which may miss implicit joint correlations. To capture richer dependencies, we introduce an encoder-decoder structure, called A-link inference module, to capture action-specific latent dependencies, i.e. actional links, directly from actions. We also extend the existing skeleton graphs to represent higher-order dependencies, i.e. structural links. Combing the two types of links into a generalized skeleton graph, we further propose the actional-structural graph convolution network (AS-GCN), which stacks actional-structural graph convolution and temporal convolution as a basic building block, to learn both spatial and temporal features for action recognition. A future pose prediction head is added in parallel to the recognition head to help capture more detailed action patterns through self-supervision.
格外精准,之前都是采用固定的图,并且GCN通过类比CNN得到,保持了类比过程中的局域性。(本文想要打破这个限制) A-link inference module: 为了重新定义邻居操作方式而设计的模块。
Introduction
The spatio-temporal GCN (ST-GCN) is further developed to simultaneously learn spatial and temporal features [29]. ST-GCN though extracts the features of joints directly connected via bones, structurally distant joints, which may cover key patterns of actions, are largely ignored. For example, while walking, hands and feet are strongly correlated. While ST-GCN tries to aggregate wider-range features with hierarchical GCNs, node features might be weaken during long diffusion [19].
We here attempt to capture richer dependencies among joints by constructing generalized skeleton graphs. In particular, we data-driven infer the actional links (A-links) to capture the latent dependencies between any joints. Similar to [16], an A-link inference module (AIM) with an encoder-decoder structure is proposed. We also extend the skeleton graphs to represent higher order relationships as the structural links (S-links). Based on the generalized graphs with the A-links and S-links, we propose an actional-structural graph convolution to capture spatial features. We further propose the actional-structural graph convolution network (AS-GCN), which stacks multiple of actional-structural graph convolutions and temporal convolutions. As a backbone network, AS-GCN adapts various tasks. Here we consider action recognition as the main task and future pose prediction as the side one.(pose prediction???啥任务,预测将来的结果,例如知道前几帧的数据,预测后一帧的数据)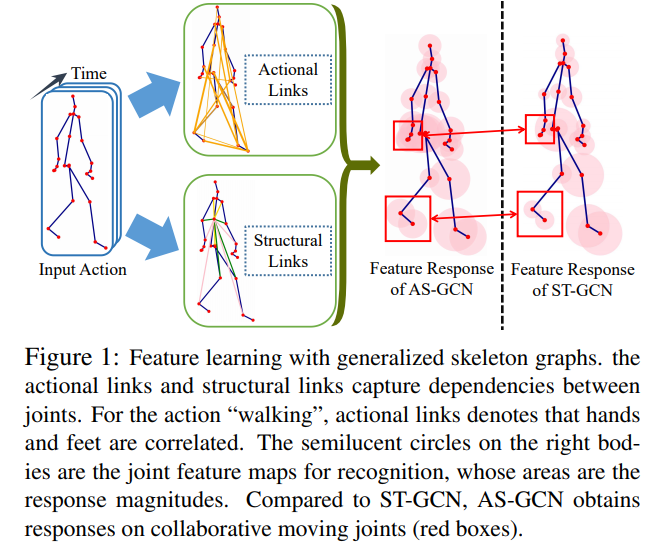
本文贡献:
- We propose the A-link inference module (AIM) to infer actional links which capture action-specific latent dependencies. The actional links are combined with structural links as generalized skeleton graphs; see Figure 1;
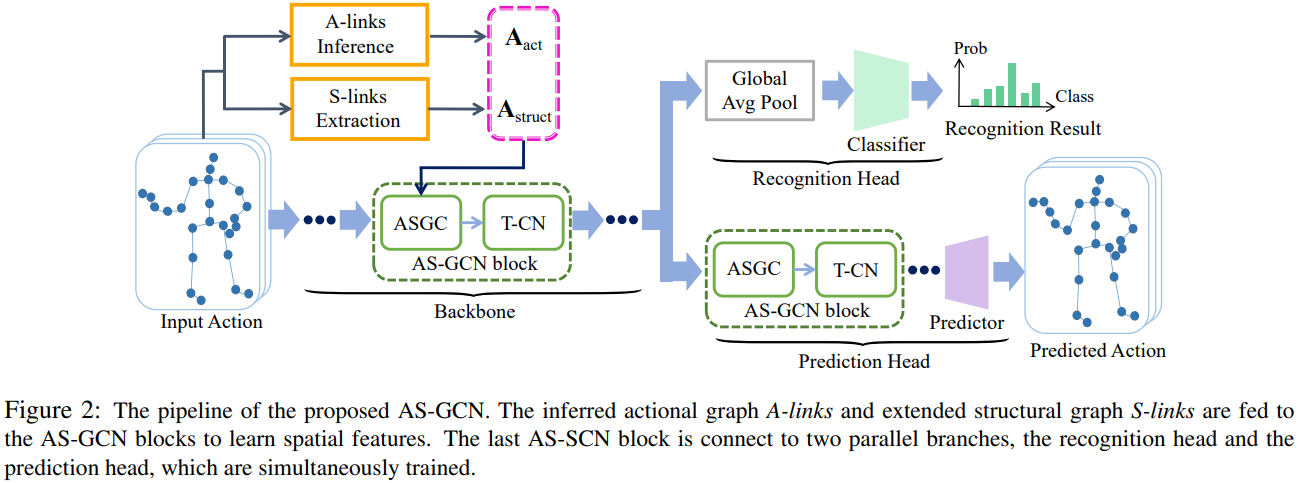
- We propose the actional-structural graph convolution network (AS-GCN) to extract useful spatial and temporal information based on the multiple graphs; see Figure 2;
- We introduce an additional future pose prediction head to predict future poses, which also improves the recognition performance by capturing more detailed action patterns;
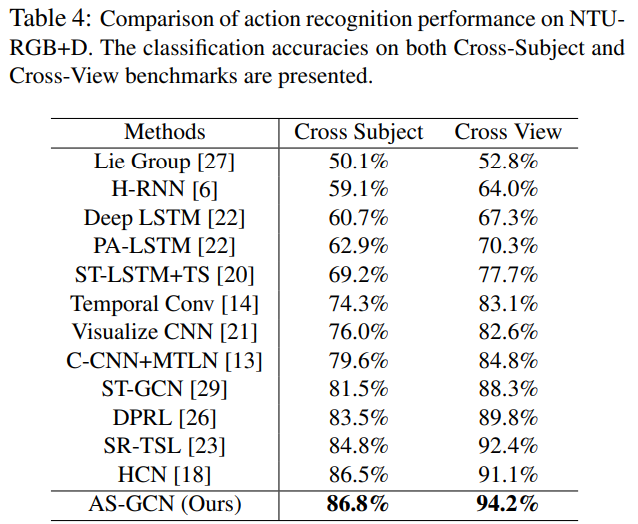
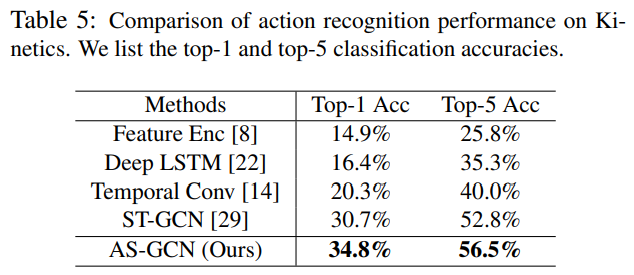
- The AS-GCN outperforms several state-of-the-art methods on two large-scale data sets; As a side product, ASGCN is also able to precisely predict the future poses.
Related Works
Background
Actional-Structural GCN
图最大的特点是扩展了连接即:

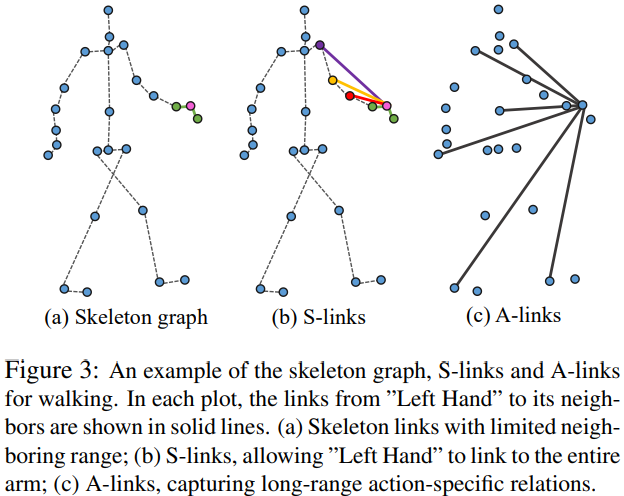
There are two types of links in  : structural links (S-links), explicitly derived from the body structure, and actional links (A-links), directly inferred from skeleton data. See the illustration of both types in Figure 3.
: structural links (S-links), explicitly derived from the body structure, and actional links (A-links), directly inferred from skeleton data. See the illustration of both types in Figure 3.
.1 Actional Links (A-links)
Many human actions need far-apart joints to move collaboratively(协同地), leading to non-physical dependencies among joints. To capture corresponding dependencies for various actions, we introduce actional links (A-links), which are activated by actions and might exist between arbitrary pair of joints. To automatically infer the A-links from actions, we develop a trainable A-link inference module (AIM), which consists of an encoder and a decoder. The encoder produces A-links by propagating information between joints and links iteratively to learn link features; and the decoder predict future joint positions based on the inferred A-links; see Figure 4. We use AIM to warm-up the A-links, which are further adjusted during the training process.
Encoder. The functionality of an encoder is to estimate the states of the **A-links** given the 3D joint positions across time; that is,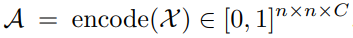
代表着关节点信息;
- 单独这样的话,就可能出现同一组节点为不同 type 连接的情况;
- A-links的思想来源:运动过程中,即使不是相邻的关节点仍旧可能存在很大的关联性,比如说走路过程中的手和脚,我们希望通过扩展邻居节点连接的方式来建模这种关联性。而如何提取这种关联性呢?通过网络自己学习产生!我们希望构建一个编码器来提取关节点的特征,根据特征来产生关节点的连接情况的表征。同时我们也希望构造一个解码器,利用它来实现关节点位置预测。(编码器和解码器的作用是很不同的,编码器提取特征,解码器实现预测);
- 基于上述思考,我们就会问,编码器怎么构造?解码器又怎么构造?
where  is the number of A-link types. Each element
is the number of A-link types. Each element  denotes the probability that the
denotes the probability that the  joints are connected with the
joints are connected with the  type. The basic idea to design the mapping encode(·) is to first exact link features from 3D joint positions and then convert the link features to the linking probabilities. To exact link features, we propagate information between joints and links alternatingly. Let
type. The basic idea to design the mapping encode(·) is to first exact link features from 3D joint positions and then convert the link features to the linking probabilities. To exact link features, we propagate information between joints and links alternatingly. Let  be the vector representation of the
be the vector representation of the  joint’s feature across all the
joint’s feature across all the  frames. We initialize the joint feature
frames. We initialize the joint feature  . In the
. In the  iteration, we propagate information back and forth between joints and links,
iteration, we propagate information back and forth between joints and links,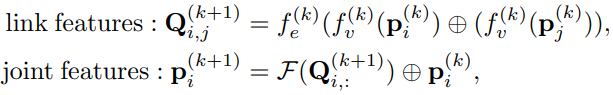
操作不会综合所有连接的信息(见代码,同样也可以通过公式看出来),但是对于同一节点的不同可能连接的信息会进行综合
where  and
and  are both multi-layer perceptrons, ⊕ is vector concatenation, and
are both multi-layer perceptrons, ⊕ is vector concatenation, and  is an operation to aggregate(聚合) link features and obtain the joint feature; such as averaging and elementwise maximization. After propagating for K times, the encoder outputs the linking probabilities as
is an operation to aggregate(聚合) link features and obtain the joint feature; such as averaging and elementwise maximization. After propagating for K times, the encoder outputs the linking probabilities as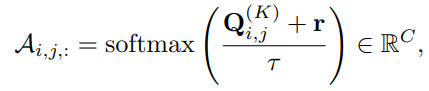
在迭代的基础上,最后通过一次其它操作将,连接类型映射为
类。在softmax中用到了比较特殊的方法:gumbel_softmax_sample
where  is a random vector, whose elements are i.i.d. sampled from Gumbel(0, 1) distribution and
is a random vector, whose elements are i.i.d. sampled from Gumbel(0, 1) distribution and  controls the discretization of
controls the discretization of  . Here we set
. Here we set  . We obtain the linking probabilities
. We obtain the linking probabilities  in the approximately categorical form by Gumbel softmax [11].
in the approximately categorical form by Gumbel softmax [11].
获取连接特征采用迭代的方式?那么
岂不是越来越大? 有人说mlp是为了数据的降维;先略过这里,到时候看代码来理解其具体过程。 这里有关采样的方式需要后续进行仔细研究。
Decoder. The functionality of the decoder to predict the future 3D joint positions conditioned on the A-links inferred by the encoder and previous poses; that is,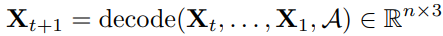
where  is the 3D joint positions at the
is the 3D joint positions at the  frame. The basic idea is to first extract joint features based on the A-links and then convert joint features to future joint positions. Let
frame. The basic idea is to first extract joint features based on the A-links and then convert joint features to future joint positions. Let  be the features of the
be the features of the  joint at the
joint at the  frame. The mapping decode(·) works as
frame. The mapping decode(·) works as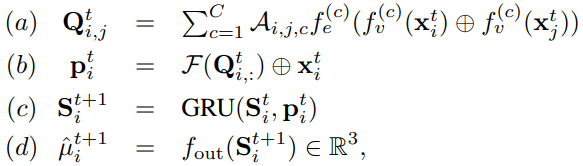
where  ,
,  and
and  are MLPs. Step (a) generates link features by weighted averaging on the linking probabilities
are MLPs. Step (a) generates link features by weighted averaging on the linking probabilities  ; Step (b) aggregates the link features to obtain the corresponding joint features; Step (c) uses a gated recurrent unit (GRU) to update the joint features [5]; and Step (d) predicts the mean of future joint positions. We finally sample the future joint positions
; Step (b) aggregates the link features to obtain the corresponding joint features; Step (c) uses a gated recurrent unit (GRU) to update the joint features [5]; and Step (d) predicts the mean of future joint positions. We finally sample the future joint positions  from a Gaussian distribution, i.e.
from a Gaussian distribution, i.e.  , where
, where  denotes the variance and
denotes the variance and  is an identity matrix.
is an identity matrix.
此处的GRU后续也需要仔细探究一下。
We pretrain AIM for a few epoches to warm-up A-links. Mathematically, the cost function of AIM is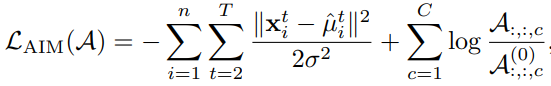
where  is the prior of
is the prior of  . In experiments, we find the performance boosts when
. In experiments, we find the performance boosts when  promotes the sparsity. The intuition behind is that too many links would capture useless dependencies to confuse action pattern learning; however, in (3), we ensure that
promotes the sparsity. The intuition behind is that too many links would capture useless dependencies to confuse action pattern learning; however, in (3), we ensure that  . Since the probability one is allocated to
. Since the probability one is allocated to  link types, it is hard to promote sparsity when
link types, it is hard to promote sparsity when  is small. To control the sparsity level, we introduce a ghost link with a large probability, indicating that two joints are not connected through any A-link. The ghost link still ensures that the probabilities sum up to one; that is, for
is small. To control the sparsity level, we introduce a ghost link with a large probability, indicating that two joints are not connected through any A-link. The ghost link still ensures that the probabilities sum up to one; that is, for  , where
, where  is the probability of isolation. Here we set the prior
is the probability of isolation. Here we set the prior  and
and  . In the training of AIM, we only update the probabilities of A-links
. In the training of AIM, we only update the probabilities of A-links  , where
, where  .
.
We accumulate  for multiple samples and minimize it to obtain a warmed-up
for multiple samples and minimize it to obtain a warmed-up  . Let
. Let  be the
be the  type of linking probability, which represents the topology of the
type of linking probability, which represents the topology of the  actional graph. We define the actional graph convolution (AGC), which uses the A-links to capture the actional dependencies among joints. In the AGC, we use
actional graph. We define the actional graph convolution (AGC), which uses the A-links to capture the actional dependencies among joints. In the AGC, we use  as the graph convolution kernel, where
as the graph convolution kernel, where  . Given the input
. Given the input  , the AGC is
, the AGC is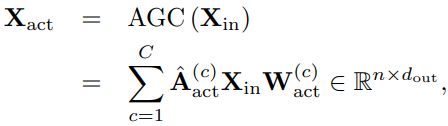
where  is the trainable weight to capture feature importance. Note that we use the AIM to warm-up A-links in the pretraining process; during the training of action recognition and pose prediction, the A-links are further optimized by forward-passing the encoder of AIM only.
is the trainable weight to capture feature importance. Note that we use the AIM to warm-up A-links in the pretraining process; during the training of action recognition and pose prediction, the A-links are further optimized by forward-passing the encoder of AIM only.
.2 Structural Links (S-links)
As shown in (1),  aggregates the 1-hop neighbors’ information in skeleton graph; that is, each layer in ST-GCN only diffuse information in a local range. To obtain long-range links, we use the high-order polynomial of
aggregates the 1-hop neighbors’ information in skeleton graph; that is, each layer in ST-GCN only diffuse information in a local range. To obtain long-range links, we use the high-order polynomial of  , indicating the S-links. Here we use as the graph convolution kernel, where
, indicating the S-links. Here we use as the graph convolution kernel, where  is the graph transition matrix and
is the graph transition matrix and  is the polynomial order.
is the polynomial order.  introduces the degree normalization to avoid the magnitude explosion and has probabilistic intuition [1, 4]. With the L-order polynomial, we define the structural graph convolution (SGC), which can directly reach the L-hop neighbors to increase the receptive field. The SGC is formulated as
introduces the degree normalization to avoid the magnitude explosion and has probabilistic intuition [1, 4]. With the L-order polynomial, we define the structural graph convolution (SGC), which can directly reach the L-hop neighbors to increase the receptive field. The SGC is formulated as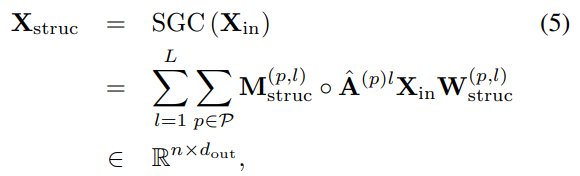
where  is the polynomial order,
is the polynomial order,  is the graph transition matrix for -th parted graph,
is the graph transition matrix for -th parted graph,  and
and  are the trainable weights to capture edge weights and feature importance; namely, larger weight indicates more important corresponding feature. The weights are introduced for each polynomial order and each individual parted graph. Note that with the degree normalization, the graph transition matrix
are the trainable weights to capture edge weights and feature importance; namely, larger weight indicates more important corresponding feature. The weights are introduced for each polynomial order and each individual parted graph. Note that with the degree normalization, the graph transition matrix  provides the nice initialization for edge weights, which stabilizes the learning of
provides the nice initialization for edge weights, which stabilizes the learning of  . When
. When  , the SGC degenerates to the original spatial graph convolution operation. For
, the SGC degenerates to the original spatial graph convolution operation. For  , the SGC acts like the Chebyshev filter and is able to approximate the convolution designed in the graph spectral domain [2]
, the SGC acts like the Chebyshev filter and is able to approximate the convolution designed in the graph spectral domain [2]
事实上哈,如果
表示距离为一的临接矩阵,那么
则可以表示距离为
的临接矩阵。易证! 这里和ST-GCN是类似的,但是其考虑的临接节点的距离更远! 为什么一个叫 actional 另外一个叫 structural 呢?actional 只考虑了关节点坐标的关系,其产生的“临接矩阵”是自动通过运动信息进行提取的;而 structual 则是考虑了具体的物理关节点的连接情况,与 ST-GCN 类似。
.3 Actional-Structural Graph Convolution Block
两种方式产生的连接是独立了,在实际过程中需要将他们组合起来(即 combine AGC and SGC):
We use a convex combination of both as the response of the ASGC. Mathematically, the ASGC operation is formulated as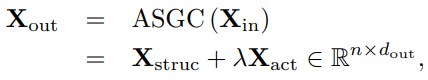
其中 是一个超参数。A non-linear activation function, such as ReLU(·), can be further introduced after ASGC.
是一个超参数。A non-linear activation function, such as ReLU(·), can be further introduced after ASGC.
凸组合。线性组合?之前只听说过凸优化?
Theorem 1. The actional-structural graph convolution is a valid linear operation; that is, when  and
and  . Then,
. Then, 
The linearity ensures that ASGC effectively preserves information from both structural and actional aspects; for example, when the response from the action aspect is stronger, it can be effectively reflected through ASGC.
To capture the inter-frame action features, we use one layer of temporal convolution (T-CN) along the time axis, which extracts the temporal feature of each joint independently but shares the weights on each joint. Since ASGC and T-CN learns spatial and temporal features, respectively, we concatenate both layers as an actional-structural graph convolution block (AS-GCN block) to extract temporal features from various actions; see Figure 5. Note that ASGC is a single operation to extract only spatial information and the AS-GCN block includes a series of operations to extract both spatial and temporal information.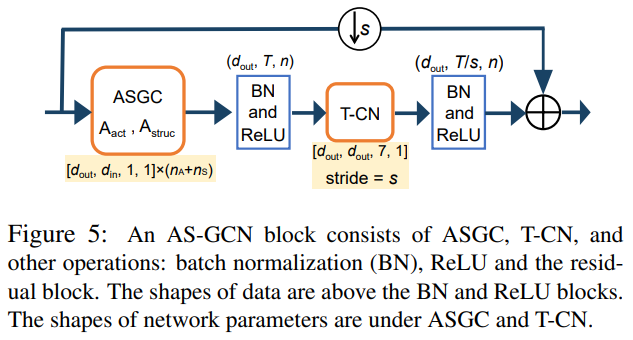
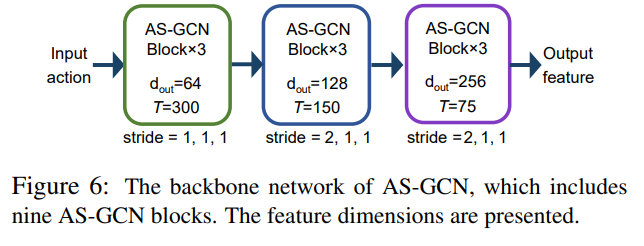
.4 Multitasking of AS-GCN
Backbone network. We stack a series of AS-GCN blocks to be the backbone network, called AS-GCN; see Figure 6. After the multiple spatial and temporal feature aggregations, AS-GCN extracts high-level semantic information across time.
AS-GCN 模块堆叠,从而产生主干网络。
Action recognition head. To classify actions, we construct a recognition head following the backbone network. We apply the global averaging pooling on the joint and temporal dimensions of the feature maps output by the backbone network, and obtain the feature vector, which is finally fed into a softmax classifier to obtain the predicted class-label  . The loss function for action recognition is the standard cross entropy loss
. The loss function for action recognition is the standard cross entropy loss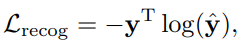
where  is the ground-truth label of the action.
is the ground-truth label of the action.
Future pose prediction head. Most previous works on the analysis of skeleton data focused on the classification task. Here we also consider pose prediction; that is, using AS-GCN to predict future 3D joint positions given by historical skeleton-based actions. To predict future poses, we construct a prediction module followed by the backbone network. We use several ASGCN blocks to decode the high-level feature maps extracted from the historical data and obtain the predicted future 3D joint positions  ; see Figure 7. The loss function for future prediction is the standard
; see Figure 7. The loss function for future prediction is the standard  loss
loss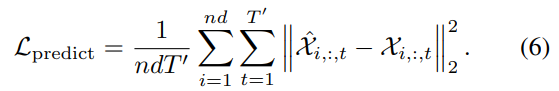
Joint model. In practice, when we train the recognition head and future prediction head together, recognition performance gets improved. The intuition behind is that the future prediction module promotes self-supervision and avoids overfitting in recognition.
结果展示
- 关于临接点分类:
 取得最好的结果;
取得最好的结果;  效果最好;
效果最好;- 考虑节点距离,即前面提到的阶数
 ,貌似越大效果越好;
,貌似越大效果越好; - 包括预测模块的网络效果更好;
总结
We propose the actional-structural graph convolution networks (AS-GCN) for skeleton-based action recognition. The A-link inference module captures actional dependencies. We also extend the skeleton graphs to represent higher order relationships. The generalized graphs are fed to ASGCN block for a better representation of actions. An additional future pose prediction head captures more detailed patterns through self-supervision. We validate AS-GCN in action recognition using two data sets, NTU-RGB+D and Kinetics. The AS-GCN achieves large improvement compared with the previous methods. Moreover, AS-GCN also shows promising results for future pose prediction.

若有收获,就点个赞吧
0 人点赞
