论文原文:3D human pose estimation in video with temporal convolutions and semi-supervised training 作者信息:Dario Pavllo, Christoph Feichtenhofer, David Grangier, Michael Auli (facebook AI Research) 工程地址:https://github.com/facebookresearch/VideoPose3D
本文简介
本文方法取得的效果优于已有的监督学习方法以及半监督学习方法。半监督时,对于未标注的数据,通过估计3D信息之后映射回2D的方式。
3D估计实现方式,首先进行2D关节点的检测,然后在此基础上进行3D关节点的估计,但是这种方式有些问题:
While splitting up the problem arguably reduces the difficulty of the task, it is inherently ambiguous as multiple 3D poses can map to the same 2D keypoints. Previous work tackled this ambiguity by modeling temporal information with recurrent neural networks
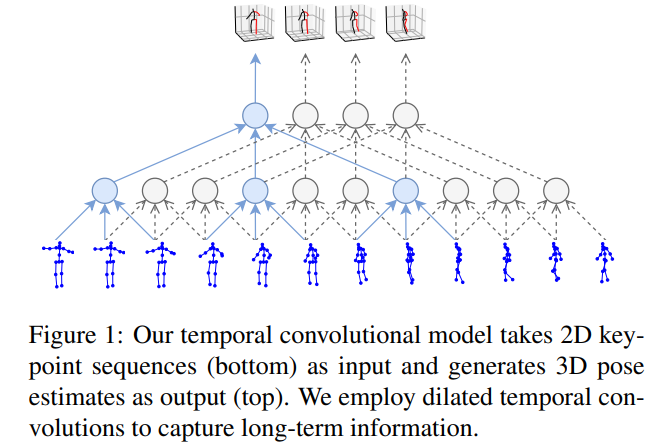
前面的一些工作采用的RNNs等网络来建模这种时序信息,本文采用的时域的空洞卷积实现:Compared to approaches relying on RNNs, it provides higher accuracy, simplicity, as well as efficiency, both in terms of computational complexity as well as the number of parameters
作者灵感来源:Our method is inspired by cycle consistency in unsupervised machine translation, where round-trip translation into an intermediate language and back into the original language should be close to the identity function. Specifically, we predict 2D keypoints for an unlabeled video with an off the shelf 2D keypoint detector, predict 3D poses, and then map these back to 2D space.
Compared to previous semi-supervised approaches, we only require camera intrinsic parameters rather than ground-truth 2D annotations or multi-view imagery with extrinsic camera parameters.(也就是在半监督过程中需要获取相机的内部参数罗???那如果不知道相机内部参数,采用默认参数应该对结果有一定的影响)
相关工作
两步姿态估计
有些方法采用的是直接 end-to-end 来直接估计人体的 3D Pose,但是这类方法精度不是很高。目前用得较多的是两步姿态估计的方法,即首先借助比较完善的 2D Pose 估计作为中继监督,然后将 2D Pose升为 3D Pose。由于有中继监督,这类方法由于 end-to-end 的方法。
这类方法关键在于估计精确的 2D Pose,2D Pose 中有的为了提高精度会借助人体的先验知识:关节点结构、关节长度比例等等
Video pose estimation
视频帧的作用是精化估计的3D姿态,利用时序上的连续性来纠正估计的部分错误。
但是,这种时序信息:Our experiments with seq2seq models showed that output poses tend to drift(漂移) over lengthy sequences.
Semi-supervised training
3D shape recovery
These approaches are typically based on parameterized 3D meshes and give less importance to pose accuracy.
Our work
不是采用的 heatmap,为了降低计算量采用了坐标,对于时序信息直接采用卷积的方式。Finally, contrary to most of the two-step models mentioned in this section (which use the popular stacked hourglass network for 2D keypoint detection), we show that Mask R-CNN and cascaded pyramid network (CPN) detections are more robust for 3D human pose estimation.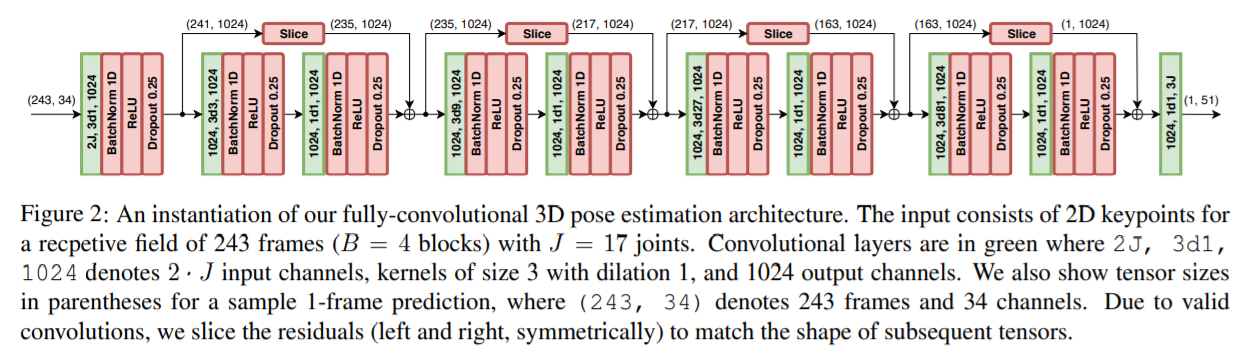
Temporal dilated convolutional model
Our model is a fully convolutional architecture with residual connections that takes a sequence of 2D poses as input and transforms them through temporal convolutions.
Convolutional models enable parallelization over both the batch and the time dimension while RNNs cannot be parallelized over time.
不采用RNN,采用卷积的原因:1、卷积能够并行计算;2、不论序列有多长,卷积模型的梯度回传长度一定,有利于降低梯度消失的概率;3、卷积结构能够对时域上的感受野精确控制;4、dilated convolution 有利于建模长期依赖;
网络输入层输入  个关节点的在时域上坐标
个关节点的在时域上坐标  的连接结果,然后对其进行 kernel size 为
的连接结果,然后对其进行 kernel size 为  的时域卷积,卷积输出通道数为
的时域卷积,卷积输出通道数为  。在这之后, 采用 的模块。每个模块首先进行
。在这之后, 采用 的模块。每个模块首先进行  卷积,其 kernel size 为,dilation factor 为
卷积,其 kernel size 为,dilation factor 为 ,紧接着的是 kernel size 为 1 的卷积。除了最好一层,所有的卷积后面都有 BN,Relu 以及 dropout 层。每一层都会按照指数级 增加感受野,但是参数增长速度是线性的。其中的
,紧接着的是 kernel size 为 1 的卷积。除了最好一层,所有的卷积后面都有 BN,Relu 以及 dropout 层。每一层都会按照指数级 增加感受野,但是参数增长速度是线性的。其中的  是超参数,但是他们被设置以致于使得对于任何输出帧的感受野形成一种树状,能够覆盖所有的输入帧(如图1所示)最后一个输出包含所有输入序列的一个3D姿态,同时考虑了过去和未来的时间信息.为了评估这个方法在实时场景的应用, 我们试验了因果卷积的方法(只对过去的信息进行卷积)。
是超参数,但是他们被设置以致于使得对于任何输出帧的感受野形成一种树状,能够覆盖所有的输入帧(如图1所示)最后一个输出包含所有输入序列的一个3D姿态,同时考虑了过去和未来的时间信息.为了评估这个方法在实时场景的应用, 我们试验了因果卷积的方法(只对过去的信息进行卷积)。
卷积网络一般采用零填充来获得和输入大小一样的输出,然而在早期实验中发现这会导致边际效应,增加了损失值。所以,我们通过左右帧关节点的复制填充这个输入序列。
在图2显示了本文你体系结构的一个实例,其中感受野大小为243帧,B = 4 块。 对于卷积层,我们设置 W = 3,C = 1024 输出通道,我们使用 dropout drop 率 p = 0.25。
Semi-supervised approach
因为获得实际的3D姿态预测的标注很困难,本文引进了一种半监督训练方法去提高在实际3D姿态标注有限情况下的姿态预测准确率。本文利用现有的2D姿态检测器和未标注的视频,将反向映射损失加入到监督损失函数中。去解决无标签数据的自动编码问题的关键思想是:将 3D 姿态预测作为编码器,把预测的姿态反向映射到 2D 姿态,基于此进行一个重建损失的计算。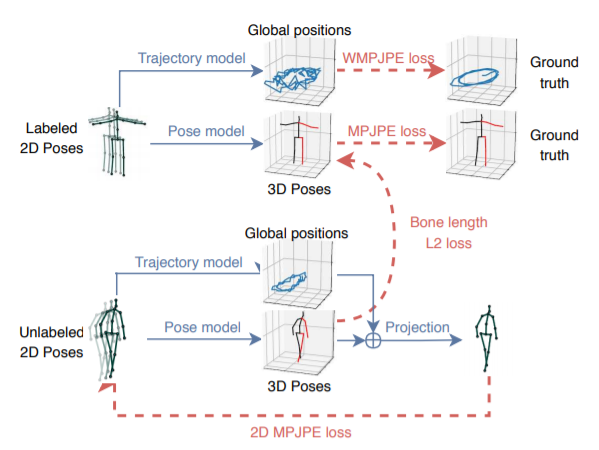
Figure 3: Semi-supervised training with a 3D pose model that takes a sequence of possibly predicted 2D poses as input. We regress the 3D trajectory of the person and add a soft-constraint to match the mean bone lengths of the unlabeled predictions to the labeled ones. Everything is trained jointly. WMPJPE stands for “Weighted MPJPE”.
对于有标签的数据采用实际的3D姿态作为目标,训练一个有监督的损失。未标签的数据被用于去执行一个自动编码器损失,即将预测的3D姿态反向映射到2D,然后检查它输入的连续性。
Trajectory model
Due to the perspective projection, the 2D pose on the screen depends both on the trajectory (i.e. the global position of the human root joint) and the 3D pose (the position of all joints with respect to the root joint). Without the global position, the subject would always be reprojected at the center of the screen with a fixed scale. We therefore also regress the 3D trajectory of the person, so that the back-projection to 2D can be performed correctly. To this end, we optimize a second network which regresses the global trajectory in camera space. The latter is added to the pose before projecting it back to 2D. The two networks have the same architecture but do not share any weights as we observed that they affect each other negatively when trained in a multi-task fashion. As it becomes increasingly difficult to regress a precise trajectory if the subject is further away from the camera, we optimize a weighted mean per-joint position error (WMPJPE) loss function for the trajectory: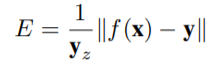
即,我们对每个样本给一个实际相机空间深度  的倒数作为权重。因为在远处物体中,相关的2D关节点都集中在一起,所以回归远处的物体也不是我们的目标。(越远的关节点预测的误差占比越小)
的倒数作为权重。因为在远处物体中,相关的2D关节点都集中在一起,所以回归远处的物体也不是我们的目标。(越远的关节点预测的误差占比越小)
Bone length L2 loss
本文你希望去激励这个大概的 3D 姿态预测,而不仅仅是复制这个输入。为此,作者发现在无标签的数据集中利用有标签数据集中的骨平均长度去做一个大致的匹配是非常有效的,这在自我监督中启到了巨大的作用。

若有收获,就点个赞吧
0 人点赞
